 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelve into the Applicability of Advanced Optimizers for Multi-Task Learning
Apr 10, 2026Multi-Task Learning (MTL) is a foundational machine learning problem that has seen extensive development over the past decade. Recently, various optimization-based MTL approaches have been proposed to learn multiple tasks simultaneously by altering the optimization trajectory. Although these methods strive to de-conflict and re-balance tasks, we empirically identify that their effectiveness is often undermined by an overlooked factor when employing advanced optimizers: the instant-derived gradients play only a marginal role in the actual parameter updates. This discrepancy prevents MTL frameworks from fully releasing its power on learning dynamics. Furthermore, we observe that Muon-a recently emerged advanced optimizer-inherently functions as a multi-task learner, which underscores the critical importance of the gradients used for its orthogonalization. To address these issues, we propose APT (Applicability of advanced oPTimizers), a framework featuring a simple adaptive momentum mechanism designed to balance the strengths between advanced optimizers and MTL. Additionally, we introduce a light direction preservation method to facilitate Muon's orthogonalization. Extensive experiments across four mainstream MTL datasets demonstrate that APT consistently augments existing MTL approaches, yielding substantial performance improvements.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
3D Point Cloud Generation via Autoregressive Up-sampling
Mar 11, 2025We introduce a pioneering autoregressive generative model for 3D point cloud generation. Inspired by visual autoregressive modeling (VAR), we conceptualize point cloud generation as an autoregressive up-sampling process. This leads to our novel model, PointARU, which progressively refines 3D point clouds from coarse to fine scales. PointARU follows a two-stage training paradigm: first, it learns multi-scale discrete representations of point clouds, and then it trains an autoregressive transformer for next-scale prediction. To address the inherent unordered and irregular structure of point clouds, we incorporate specialized point-based up-sampling network modules in both stages and integrate 3D absolute positional encoding based on the decoded point cloud at each scale during the second stage. Our model surpasses state-of-the-art (SoTA) diffusion-based approaches in both generation quality and parameter efficiency across diverse experimental settings, marking a new milestone for autoregressive methods in 3D point cloud generation. Furthermore, PointARU demonstrates exceptional performance in completing partial 3D shapes and up-sampling sparse point clouds, outperforming existing generative models in these tasks.
Injecting Imbalance Sensitivity for Multi-Task Learning
Mar 11, 2025Multi-task learning (MTL) has emerged as a promising approach for deploying deep learning models in real-life applications. Recent studies have proposed optimization-based learning paradigms to establish task-shared representations in MTL. However, our paper empirically argues that these studies, specifically gradient-based ones, primarily emphasize the conflict issue while neglecting the potentially more significant impact of imbalance/dominance in MTL. In line with this perspective, we enhance the existing baseline method by injecting imbalance-sensitivity through the imposition of constraints on the projected norms. To demonstrate the effectiveness of our proposed IMbalance-sensitive Gradient (IMGrad) descent method, we evaluate it on multiple mainstream MTL benchmarks, encompassing supervised learning tasks as well as reinforcement learning. The experimental results consistently demonstrate competitive performance.
Continual Optimization with Symmetry Teleportation for Multi-Task Learning
Mar 06, 2025



Multi-task learning (MTL) is a widely explored paradigm that enables the simultaneous learning of multiple tasks using a single model. Despite numerous solutions, the key issues of optimization conflict and task imbalance remain under-addressed, limiting performance. Unlike existing optimization-based approaches that typically reweight task losses or gradients to mitigate conflicts or promote progress, we propose a novel approach based on Continual Optimization with Symmetry Teleportation (COST). During MTL optimization, when an optimization conflict arises, we seek an alternative loss-equivalent point on the loss landscape to reduce conflict. Specifically, we utilize a low-rank adapter (LoRA) to facilitate this practical teleportation by designing convergent, loss-invariant objectives. Additionally, we introduce a historical trajectory reuse strategy to continually leverage the benefits of advanced optimizers. Extensive experiments on multiple mainstream datasets demonstrate the effectiveness of our approach. COST is a plug-and-play solution that enhances a wide range of existing MTL methods. When integrated with state-of-the-art methods, COST achieves superior performance.
ControLRM: Fast and Controllable 3D Generation via Large Reconstruction Model
Oct 12, 2024



Despite recent advancements in 3D generation methods, achieving controllability still remains a challenging issue. Current approaches utilizing score-distillation sampling are hindered by laborious procedures that consume a significant amount of time. Furthermore, the process of first generating 2D representations and then mapping them to 3D lacks internal alignment between the two forms of representation. To address these challenges, we introduce ControLRM, an end-to-end feed-forward model designed for rapid and controllable 3D generation using a large reconstruction model (LRM). ControLRM comprises a 2D condition generator, a condition encoding transformer, and a triplane decoder transformer. Instead of training our model from scratch, we advocate for a joint training framework. In the condition training branch, we lock the triplane decoder and reuses the deep and robust encoding layers pretrained with millions of 3D data in LRM. In the image training branch, we unlock the triplane decoder to establish an implicit alignment between the 2D and 3D representations. To ensure unbiased evaluation, we curate evaluation samples from three distinct datasets (G-OBJ, GSO, ABO) rather than relying on cherry-picking manual generation. The comprehensive experiments conducted on quantitative and qualitative comparisons of 3D controllability and generation quality demonstrate the strong generalization capacity of our proposed approach.
CostFormer:Cost Transformer for Cost Aggregation in Multi-view Stereo
May 17, 2023



The core of Multi-view Stereo(MVS) is the matching process among reference and source pixels. Cost aggregation plays a significant role in this process, while previous methods focus on handling it via CNNs. This may inherit the natural limitation of CNNs that fail to discriminate repetitive or incorrect matches due to limited local receptive fields. To handle the issue, we aim to involve Transformer into cost aggregation. However, another problem may occur due to the quadratically growing computational complexity caused by Transformer, resulting in memory overflow and inference latency. In this paper, we overcome these limits with an efficient Transformer-based cost aggregation network, namely CostFormer. The Residual Depth-Aware Cost Transformer(RDACT) is proposed to aggregate long-range features on cost volume via self-attention mechanisms along the depth and spatial dimensions. Furthermore, Residual Regression Transformer(RRT) is proposed to enhance spatial attention. The proposed method is a universal plug-in to improve learning-based MVS methods.
Semi-supervised Deep Multi-view Stereo
Jul 24, 2022
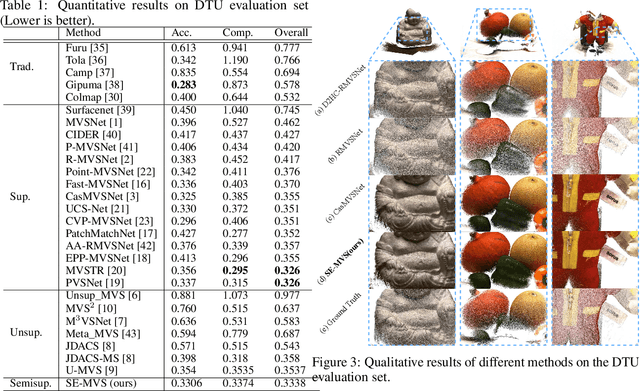
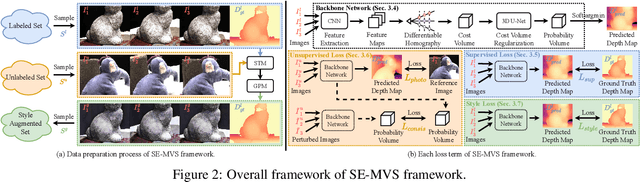
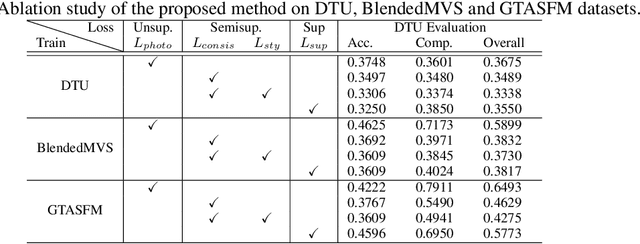
Significant progress has been witnessed in learning-based Multi-view Stereo (MVS) of supervised and unsupervised settings. To combine their respective merits in accuracy and completeness, meantime reducing the demand for expensive labeled data, this paper explores a novel semi-supervised setting of learning-based MVS problem that only a tiny part of the MVS data is attached with dense depth ground truth. However, due to huge variation of scenarios and flexible setting in views, semi-supervised MVS problem (Semi-MVS) may break the basic assumption in classic semi-supervised learning, that unlabeled data and labeled data share the same label space and data distribution. To handle these issues, we propose a novel semi-supervised MVS framework, namely SE-MVS. For the simple case that the basic assumption works in MVS data, consistency regularization encourages the model predictions to be consistent between original sample and randomly augmented sample via constraints on KL divergence. For further troublesome case that the basic assumption is conflicted in MVS data, we propose a novel style consistency loss to alleviate the negative effect caused by the distribution gap. The visual style of unlabeled sample is transferred to labeled sample to shrink the gap, and the model prediction of generated sample is further supervised with the label in original labeled sample. The experimental results on DTU, BlendedMVS, GTA-SFM, and Tanks\&Temples datasets show the superior performance of the proposed method. With the same settings in backbone network, our proposed SE-MVS outperforms its fully-supervised and unsupervised baselines.
Rethinking the Zigzag Flattening for Image Reading
Mar 15, 2022


Sequence ordering of word vector matters a lot to text reading, which has been proven in natural language processing (NLP). However, the rule of different sequence ordering in computer vision (CV) was not well explored, e.g., why the "zigzag" flattening (ZF) is commonly utilized as a default option to get the image patches ordering in vision transformers (ViTs). Notably, when decomposing multi-scale images, the ZF could not maintain the invariance of feature point positions. To this end, we investigate the Hilbert fractal flattening (HF) as another method for sequence ordering in CV and contrast it against ZF. The HF has proven to be superior to other curves in maintaining spatial locality, when performing multi-scale transformations of dimensional space. And it can be easily plugged into most deep neural networks (DNNs). Extensive experiments demonstrate that it can yield consistent and significant performance boosts for a variety of architectures. Finally, we hope that our studies spark further research about the flattening strategy of image reading.
CP-Net: Contour-Perturbed Reconstruction Network for Self-Supervised Point Cloud Learning
Jan 20, 2022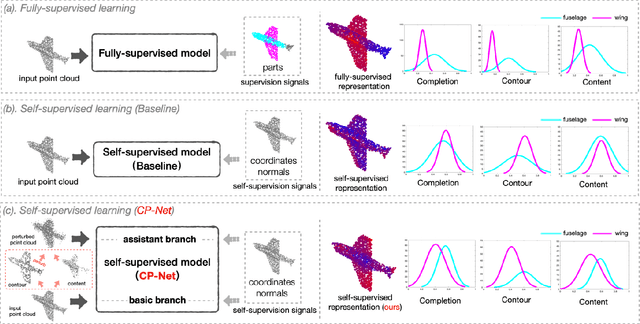
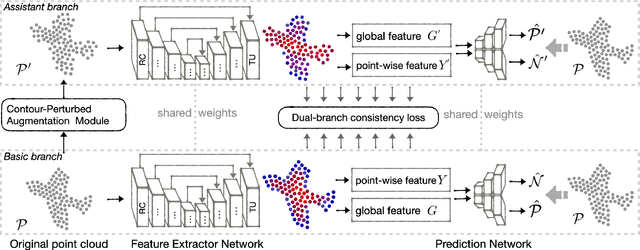
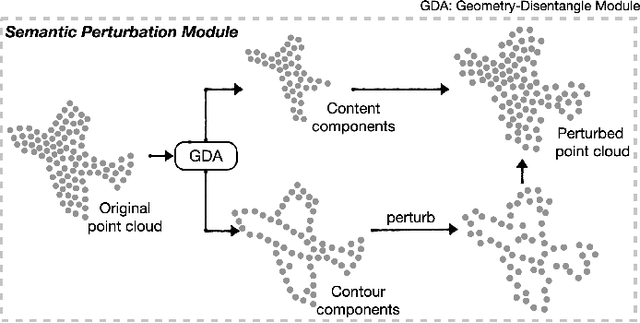

Self-supervised learning has not been fully explored for point cloud analysis. Current frameworks are mainly based on point cloud reconstruction. Given only 3D coordinates, such approaches tend to learn local geometric structures and contours, while failing in understanding high level semantic content. Consequently, they achieve unsatisfactory performance in downstream tasks such as classification, segmentation, etc. To fill this gap, we propose a generic Contour-Perturbed Reconstruction Network (CP-Net), which can effectively guide self-supervised reconstruction to learn semantic content in the point cloud, and thus promote discriminative power of point cloud representation. First, we introduce a concise contour-perturbed augmentation module for point cloud reconstruction. With guidance of geometry disentangling, we divide point cloud into contour and content components. Subsequently, we perturb the contour components and preserve the content components on the point cloud. As a result, self supervisor can effectively focus on semantic content, by reconstructing the original point cloud from such perturbed one. Second, we use this perturbed reconstruction as an assistant branch, to guide the learning of basic reconstruction branch via a distinct dual-branch consistency loss. In this case, our CP-Net not only captures structural contour but also learn semantic content for discriminative downstream tasks. Finally, we perform extensive experiments on a number of point cloud benchmarks. Part segmentation results demonstrate that our CP-Net (81.5% of mIoU) outperforms the previous self-supervised models, and narrows the gap with the fully-supervised methods. For classification, we get a competitive result with the fully-supervised methods on ModelNet40 (92.5% accuracy) and ScanObjectNN (87.9% accuracy). The codes and models will be released afterwards.