 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-Net: Contour-Perturbed Reconstruction Network for Self-Supervised Point Cloud Learning
Paper and Code
Jan 20, 2022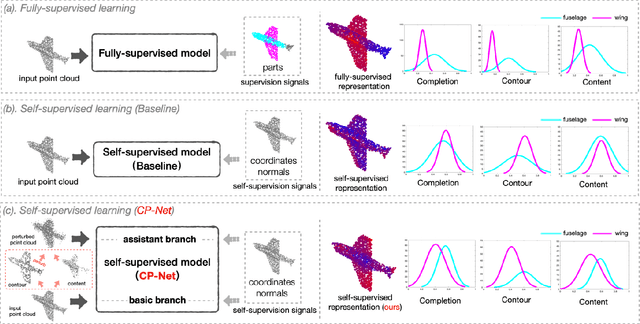
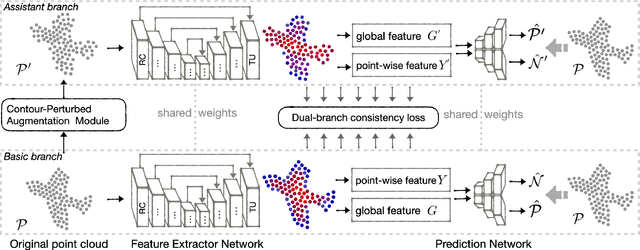
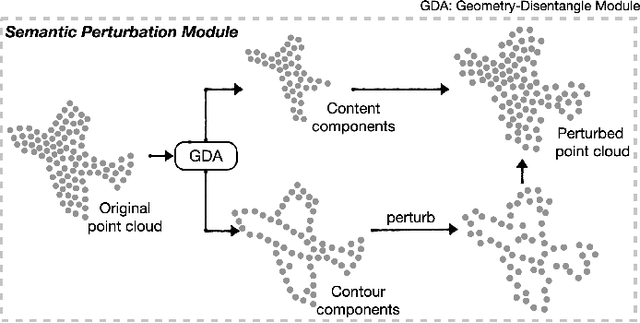

Self-supervised learning has not been fully explored for point cloud analysis. Current frameworks are mainly based on point cloud reconstruction. Given only 3D coordinates, such approaches tend to learn local geometric structures and contours, while failing in understanding high level semantic content. Consequently, they achieve unsatisfactory performance in downstream tasks such as classification, segmentation, etc. To fill this gap, we propose a generic Contour-Perturbed Reconstruction Network (CP-Net), which can effectively guide self-supervised reconstruction to learn semantic content in the point cloud, and thus promote discriminative power of point cloud representation. First, we introduce a concise contour-perturbed augmentation module for point cloud reconstruction. With guidance of geometry disentangling, we divide point cloud into contour and content components. Subsequently, we perturb the contour components and preserve the content components on the point cloud. As a result, self supervisor can effectively focus on semantic content, by reconstructing the original point cloud from such perturbed one. Second, we use this perturbed reconstruction as an assistant branch, to guide the learning of basic reconstruction branch via a distinct dual-branch consistency loss. In this case, our CP-Net not only captures structural contour but also learn semantic content for discriminative downstream tasks. Finally, we perform extensive experiments on a number of point cloud benchmarks. Part segmentation results demonstrate that our CP-Net (81.5% of mIoU) outperforms the previous self-supervised models, and narrows the gap with the fully-supervised methods. For classification, we get a competitive result with the fully-supervised methods on ModelNet40 (92.5% accuracy) and ScanObjectNN (87.9% accuracy). The codes and models will be released afterwards.