 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptMark: Robust Multi-bit Diffusion Watermarking via Inference Time Optimization
Aug 29, 2025



Watermarking diffusion-generated images is crucial for copyright protection and user tracking. However, current diffusion watermarking methods face significant limitations: zero-bit watermarking systems lack the capacity for large-scale user tracking, while multi-bit methods are highly sensitive to certain image transformations or generative attacks, resulting in a lack of comprehensive robustness. In this paper, we propose OptMark, an optimization-based approach that embeds a robust multi-bit watermark into the intermediate latents of the diffusion denoising process. OptMark strategically inserts a structural watermark early to resist generative attacks and a detail watermark late to withstand image transformations, with tailored regularization terms to preserve image quality and ensure imperceptibility. To address the challenge of memory consumption growing linearly with the number of denoising steps during optimization, OptMark incorporates adjoint gradient methods, reducing memory usage from O(N) to O(1). Experimental results demonstrate that OptMark achieves invisible multi-bit watermarking while ensuring robust resilience against valuemetric transformations, geometric transformations, editing, and regeneration attacks.
Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
May 19, 2025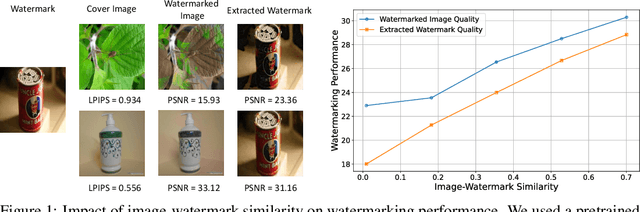
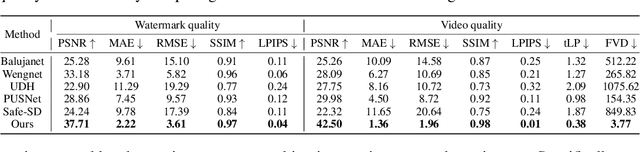
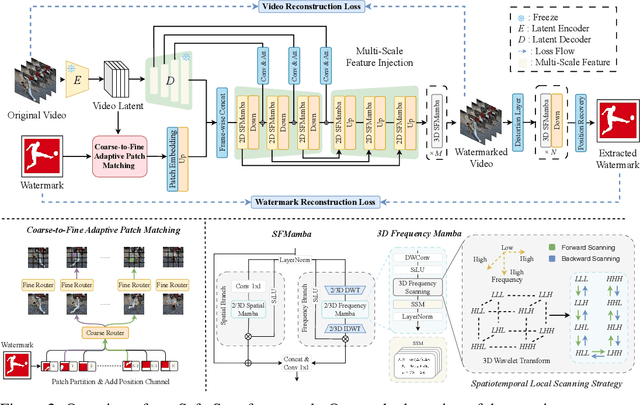

The explosive growth of generative video models has amplified the demand for reliable copyright preservation of AI-generated content. Despite its popularity in image synthesis, invisible generative watermarking remains largely underexplored in video generation. To address this gap, we propose Safe-Sora, the first framework to embed graphical watermarks directly into the video generation process. Motivated by the observation that watermarking performance is closely tied to the visual similarity between the watermark and cover content, we introduce a hierarchical coarse-to-fine adaptive matching mechanism. Specifically, the watermark image is divided into patches, each assigned to the most visually similar video frame, and further localized to the optimal spatial region for seamless embedding. To enable spatiotemporal fusion of watermark patches across video frames, we develop a 3D wavelet transform-enhanced Mamba architecture with a novel spatiotemporal local scanning strategy, effectively modeling long-range dependencies during watermark embedding and retrieval. To the best of our knowledge, this is the first attempt to apply state space models to watermarking, opening new avenues for efficient and robust watermark protection. Extensive experiments demonstrate that Safe-Sora achieves state-of-the-art performance in terms of video quality, watermark fidelity, and robustness, which is largely attributed to our proposals. We will release our code upon publication.
AS3D: 2D-Assisted Cross-Modal Understanding with Semantic-Spatial Scene Graphs for 3D Visual Grounding
May 07, 20253D visual grounding aims to localize the unique target described by natural languages in 3D scenes. The significant gap between 3D and language modalities makes it a notable challenge to distinguish multiple similar objects through the described spatial relationships. Current methods attempt to achieve cross-modal understanding in complex scenes via a target-centered learning mechanism, ignoring the perception of referred objects. We propose a novel 2D-assisted 3D visual grounding framework that constructs semantic-spatial scene graphs with referred object discrimination for relationship perception. The framework incorporates a dual-branch visual encoder that utilizes 2D pre-trained attributes to guide the multi-modal object encoding. Furthermore, our cross-modal interaction module uses graph attention to facilitate relationship-oriented information fusion. The enhanced object representation and iterative relational learning enable the model to establish effective alignment between 3D vision and referential descriptions. Experimental results on the popular benchmarks demonstrate our superior performance compared to state-of-the-art methods, especially in addressing the challenges of multiple similar distractors.
Cyc3D: Fine-grained Controllable 3D Generation via Cycle Consistency Regularization
Apr 21, 2025


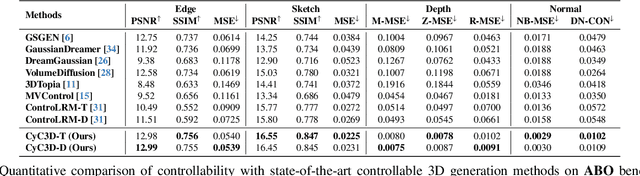
Despite the remarkable progress of 3D generation, achieving controllability, i.e., ensuring consistency between generated 3D content and input conditions like edge and depth, remains a significant challenge. Existing methods often struggle to maintain accurate alignment, leading to noticeable discrepancies. To address this issue, we propose \name{}, a new framework that enhances controllable 3D generation by explicitly encouraging cyclic consistency between the second-order 3D content, generated based on extracted signals from the first-order generation, and its original input controls. Specifically, we employ an efficient feed-forward backbone that can generate a 3D object from an input condition and a text prompt. Given an initial viewpoint and a control signal, a novel view is rendered from the generated 3D content, from which the extracted condition is used to regenerate the 3D content. This re-generated output is then rendered back to the initial viewpoint, followed by another round of control signal extraction, forming a cyclic process with two consistency constraints. \emph{View consistency} ensures coherence between the two generated 3D objects, measured by semantic similarity to accommodate generative diversity. \emph{Condition consistency} aligns the final extracted signal with the original input control, preserving structural or geometric details throughout the process. Extensive experiments on popular benchmarks demonstrate that \name{} significantly improves controllability, especially for fine-grained details, outperforming existing methods across various conditions (e.g., +14.17\% PSNR for edge, +6.26\% PSNR for sketch).
TextSplat: Text-Guided Semantic Fusion for Generalizable Gaussian Splatting
Apr 13, 2025Recent advancements in Generalizable Gaussian Splatting have enabled robust 3D reconstruction from sparse input views by utilizing feed-forward Gaussian Splatting models, achieving superior cross-scene generalization. However, while many methods focus on geometric consistency, they often neglect the potential of text-driven guidance to enhance semantic understanding, which is crucial for accurately reconstructing fine-grained details in complex scenes. To address this limitation, we propose TextSplat--the first text-driven Generalizable Gaussian Splatting framework. By employing a text-guided fusion of diverse semantic cues, our framework learns robust cross-modal feature representations that improve the alignment of geometric and semantic information, producing high-fidelity 3D reconstructions. Specifically, our framework employs three parallel modules to obtain complementary representations: the Diffusion Prior Depth Estimator for accurate depth information, the Semantic Aware Segmentation Network for detailed semantic information, and the Multi-View Interaction Network for refined cross-view features. Then, in the Text-Guided Semantic Fusion Module, these representations are integrated via the text-guided and attention-based feature aggregation mechanism, resulting in enhanced 3D Gaussian parameters enriched with detailed semantic cues. Experimental results on various benchmark datasets demonstrate improved performance compared to existing methods across multiple evaluation metrics, validating the effectiveness of our framework. The code will be publicly available.
Safe-VAR: Safe Visual Autoregressive Model for Text-to-Image Generative Watermarking
Mar 14, 2025With the success of autoregressive learning in large language models, it has become a dominant approach for text-to-image generation, offering high efficiency and visual quality. However, invisible watermarking for visual autoregressive (VAR) models remains underexplored, despite its importance in misuse prevention. Existing watermarking methods, designed for diffusion models, often struggle to adapt to the sequential nature of VAR models. To bridge this gap, we propose Safe-VAR, the first watermarking framework specifically designed for autoregressive text-to-image generation. Our study reveals that the timing of watermark injection significantly impacts generation quality, and watermarks of different complexities exhibit varying optimal injection times. Motivated by this observation, we propose an Adaptive Scale Interaction Module, which dynamically determines the optimal watermark embedding strategy based on the watermark information and the visual characteristics of the generated image. This ensures watermark robustness while minimizing its impact on image quality. Furthermore, we introduce a Cross-Scale Fusion mechanism, which integrates mixture of both heads and experts to effectively fuse multi-resolution features and handle complex interactions between image content and watermark patterns. Experimental results demonstrate that Safe-VAR achieves state-of-the-art performance, significantly surpassing existing counterparts regarding image quality, watermarking fidelity, and robustness against perturbations. Moreover, our method exhibits strong generalization to an out-of-domain watermark dataset QR Codes.
4DStyleGaussian: Zero-shot 4D Style Transfer with Gaussian Splatting
Oct 14, 20243D neural style transfer has gained significant attention for its potential to provide user-friendly stylization with spatial consistency. However, existing 3D style transfer methods often fall short in terms of inference efficiency, generalization ability, and struggle to handle dynamic scenes with temporal consistency. In this paper, we introduce 4DStyleGaussian, a novel 4D style transfer framework designed to achieve real-time stylization of arbitrary style references while maintaining reasonable content affinity, multi-view consistency, and temporal coherence. Our approach leverages an embedded 4D Gaussian Splatting technique, which is trained using a reversible neural network for reducing content loss in the feature distillation process. Utilizing the 4D embedded Gaussians, we predict a 4D style transformation matrix that facilitates spatially and temporally consistent style transfer with Gaussian Splatting. Experiments demonstrate that our method can achieve high-quality and zero-shot stylization for 4D scenarios with enhanced efficiency and spatial-temporal consistency.
Improving 3D Finger Traits Recognition via Generalizable Neural Rendering
Oct 12, 20243D biometric techniques on finger traits have become a new trend and have demonstrated a powerful ability for recognition and anti-counterfeiting. Existing methods follow an explicit 3D pipeline that reconstructs the models first and then extracts features from 3D models. However, these explicit 3D methods suffer from the following problems: 1) Inevitable information dropping during 3D reconstruction; 2) Tight coupling between specific hardware and algorithm for 3D reconstruction. It leads us to a question: Is it indispensable to reconstruct 3D information explicitly in recognition tasks? Hence, we consider this problem in an implicit manner, leaving the nerve-wracking 3D reconstruction problem for learnable neural networks with the help of neural radiance fields (NeRFs). We propose FingerNeRF, a novel generalizable NeRF for 3D finger biometrics. To handle the shape-radiance ambiguity problem that may result in incorrect 3D geometry, we aim to involve extra geometric priors based on the correspondence of binary finger traits like fingerprints or finger veins. First, we propose a novel Trait Guided Transformer (TGT) module to enhance the feature correspondence with the guidance of finger traits. Second, we involve extra geometric constraints on the volume rendering loss with the proposed Depth Distillation Loss and Trait Guided Rendering Loss. To evaluate the performance of the proposed method on different modalities, we collect two new datasets: SCUT-Finger-3D with finger images and SCUT-FingerVein-3D with finger vein images. Moreover, we also utilize the UNSW-3D dataset with fingerprint images for evaluation. In experiments, our FingerNeRF can achieve 4.37% EER on SCUT-Finger-3D dataset, 8.12% EER on SCUT-FingerVein-3D dataset, and 2.90% EER on UNSW-3D dataset, showing the superiority of the proposed implicit method in 3D finger biometrics.
ControLRM: Fast and Controllable 3D Generation via Large Reconstruction Model
Oct 12, 2024



Despite recent advancements in 3D generation methods, achieving controllability still remains a challenging issue. Current approaches utilizing score-distillation sampling are hindered by laborious procedures that consume a significant amount of time. Furthermore, the process of first generating 2D representations and then mapping them to 3D lacks internal alignment between the two forms of representation. To address these challenges, we introduce ControLRM, an end-to-end feed-forward model designed for rapid and controllable 3D generation using a large reconstruction model (LRM). ControLRM comprises a 2D condition generator, a condition encoding transformer, and a triplane decoder transformer. Instead of training our model from scratch, we advocate for a joint training framework. In the condition training branch, we lock the triplane decoder and reuses the deep and robust encoding layers pretrained with millions of 3D data in LRM. In the image training branch, we unlock the triplane decoder to establish an implicit alignment between the 2D and 3D representations. To ensure unbiased evaluation, we curate evaluation samples from three distinct datasets (G-OBJ, GSO, ABO) rather than relying on cherry-picking manual generation. The comprehensive experiments conducted on quantitative and qualitative comparisons of 3D controllability and generation quality demonstrate the strong generalization capacity of our proposed approach.
GaussianOcc: Fully Self-supervised and Efficient 3D Occupancy Estimation with Gaussian Splatting
Aug 21, 2024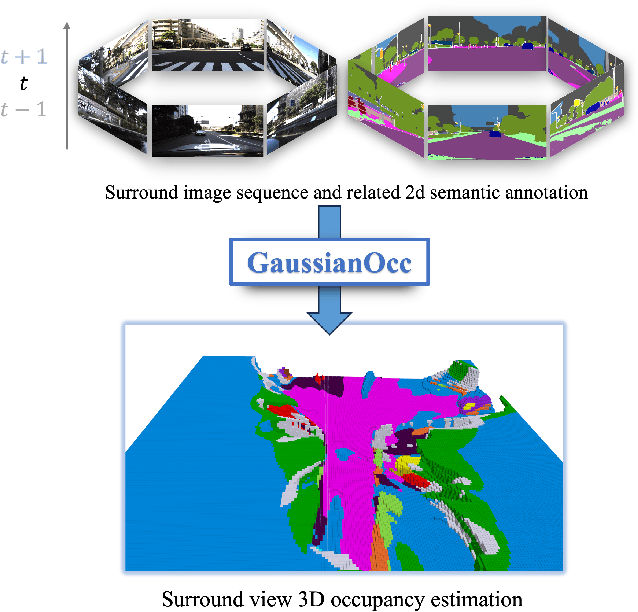
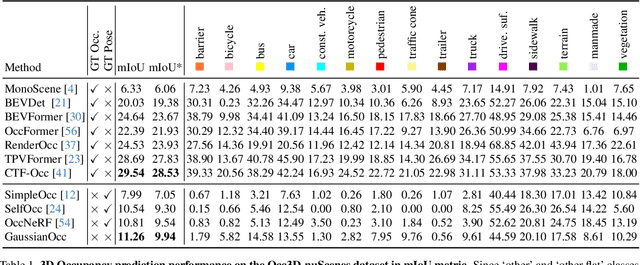
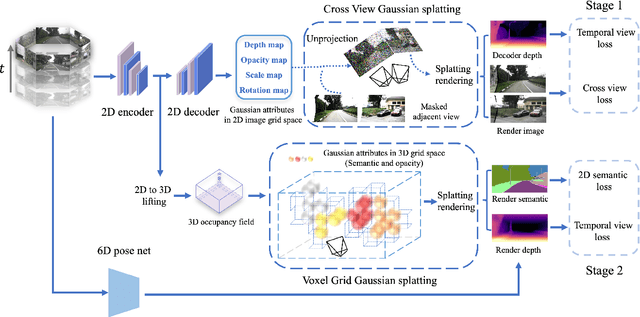
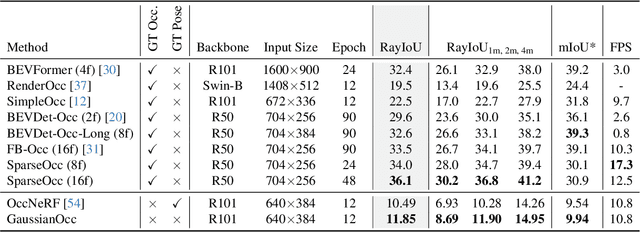
We introduce GaussianOcc, a systematic method that investigates the two usages of Gaussian splatting for fully self-supervised and efficient 3D occupancy estimation in surround views. First, traditional methods for self-supervised 3D occupancy estimation still require ground truth 6D poses from sensors during training. To address this limitation, we propose Gaussian Splatting for Projection (GSP) module to provide accurate scale information for fully self-supervised training from adjacent view projection. Additionally, existing methods rely on volume rendering for final 3D voxel representation learning using 2D signals (depth maps, semantic maps), which is both time-consuming and less effective. We propose Gaussian Splatting from Voxel space (GSV) to leverage the fast rendering properties of Gaussian splatting. As a result, the proposed GaussianOcc method enables fully self-supervised (no ground truth pose) 3D occupancy estimation in competitive performance with low computational cost (2.7 times faster in training and 5 times faster in rendering).