 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
May 18, 2026Designing realistic and functional 3D indoor rooms is essential for a wide range of applications, including interior design, virtual reality, gaming, and embodied AI. While recent MLLM-based approaches have shown great potential for 3D room synthesis from textual descriptions or reference images, text-based methods struggle to capture precise spatial information, and existing image-conditioned agents suffer from instability and infinite looping when tasked with holistic room generation from top-down views. To address these limitations, we propose Code-as-Room, an MLLM-based agentic framework equipped with a structured execution harness, which represents 3D rooms with Blender codes. Given a top-down room image, the framework parses the reference image to extract scene elements and their spatial relationships, and synthesizes executable Blender code for geometry, materials, and lighting in a principled, multi-stage pipeline. A cross-stage memory module is maintained throughout to mitigate context forgetting inherent to existing agent-based frameworks. We further introduce a dedicated benchmark for code-based 3D room synthesis, encompassing various evaluation protocols. Based on our benchmark, comprehensive comparisons against existing agent-based methods are conducted to validate the effectiveness of our proposed execution harness.
GaussianOcc: Fully Self-supervised and Efficient 3D Occupancy Estimation with Gaussian Splatting
Aug 21, 2024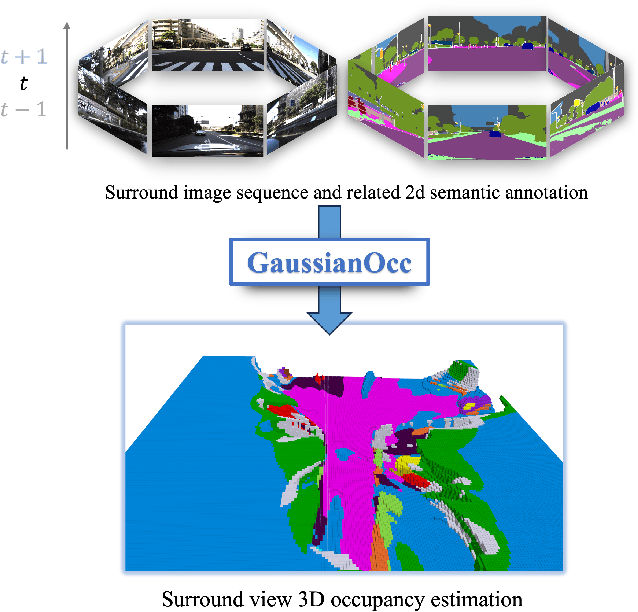
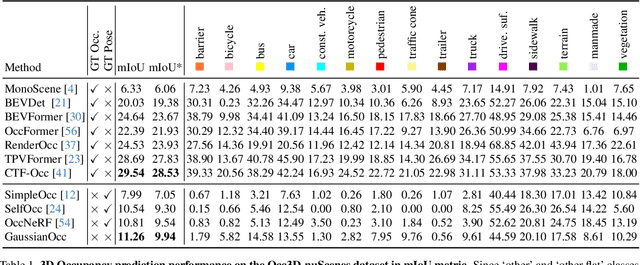
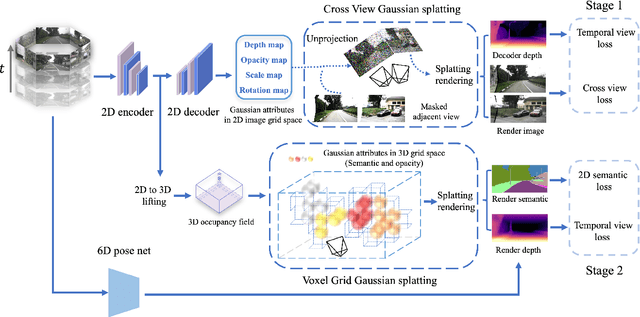
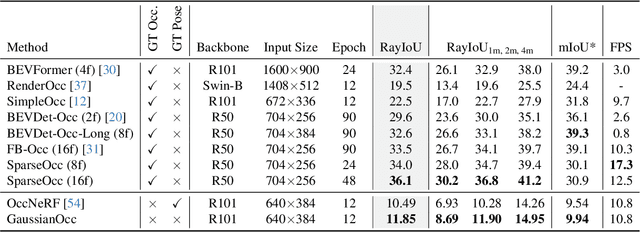
We introduce GaussianOcc, a systematic method that investigates the two usages of Gaussian splatting for fully self-supervised and efficient 3D occupancy estimation in surround views. First, traditional methods for self-supervised 3D occupancy estimation still require ground truth 6D poses from sensors during training. To address this limitation, we propose Gaussian Splatting for Projection (GSP) module to provide accurate scale information for fully self-supervised training from adjacent view projection. Additionally, existing methods rely on volume rendering for final 3D voxel representation learning using 2D signals (depth maps, semantic maps), which is both time-consuming and less effective. We propose Gaussian Splatting from Voxel space (GSV) to leverage the fast rendering properties of Gaussian splatting. As a result, the proposed GaussianOcc method enables fully self-supervised (no ground truth pose) 3D occupancy estimation in competitive performance with low computational cost (2.7 times faster in training and 5 times faster in rendering).
Enhancing Monocular Height Estimation from Aerial Images with Street-view Images
Nov 03, 2023



Accurate height estimation from monocular aerial imagery presents a significant challenge due to its inherently ill-posed nature. This limitation is rooted in the absence of adequate geometric constraints available to the model when training with monocular imagery. Without additional geometric information to supplement the monocular image data, the model's ability to provide reliable estimations is compromised. In this paper, we propose a method that enhances monocular height estimation by incorporating street-view images. Our insight is that street-view images provide a distinct viewing perspective and rich structural details of the scene, serving as geometric constraints to enhance the performance of monocular height estimation. Specifically, we aim to optimize an implicit 3D scene representation, density field, with geometry constraints from street-view images, thereby improving the accuracy and robustness of height estimation. Our experimental results demonstrate the effectiveness of our proposed method, outperforming the baseline and offering significant improvements in terms of accuracy and structural consistency.
A Simple Attempt for 3D Occupancy Estimation in Autonomous Driving
Apr 04, 2023The task of estimating 3D occupancy from surrounding view images is an exciting development in the field of autonomous driving, following the success of Birds Eye View (BEV) perception.This task provides crucial 3D attributes of the driving environment, enhancing the overall understanding and perception of the surrounding space. However, there is still a lack of a baseline to define the task, such as network design, optimization, and evaluation. In this work, we present a simple attempt for 3D occupancy estimation, which is a CNN-based framework designed to reveal several key factors for 3D occupancy estimation. In addition, we explore the relationship between 3D occupancy estimation and other related tasks, such as monocular depth estimation, stereo matching, and BEV perception (3D object detection and map segmentation), which could advance the study on 3D occupancy estimation. For evaluation, we propose a simple sampling strategy to define the metric for occupancy evaluation, which is flexible for current public datasets. Moreover, we establish a new benchmark in terms of the depth estimation metric, where we compare our proposed method with monocular depth estimation methods on the DDAD and Nuscenes datasets.The relevant code will be available in https://github.com/GANWANSHUI/SimpleOccupancy
V4D: Voxel for 4D Novel View Synthesis
May 28, 2022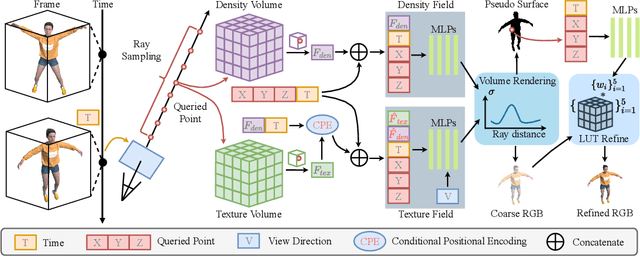
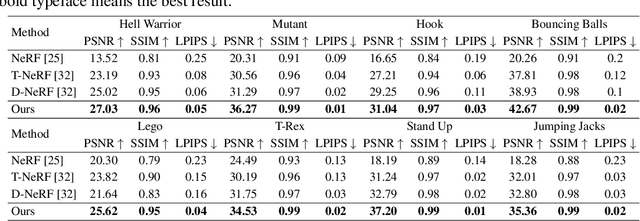
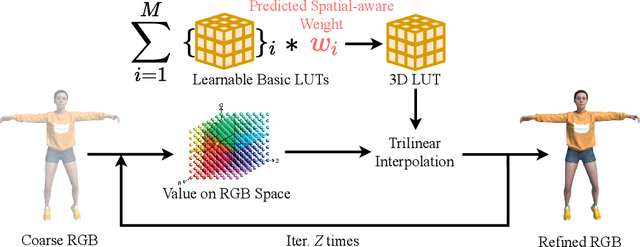
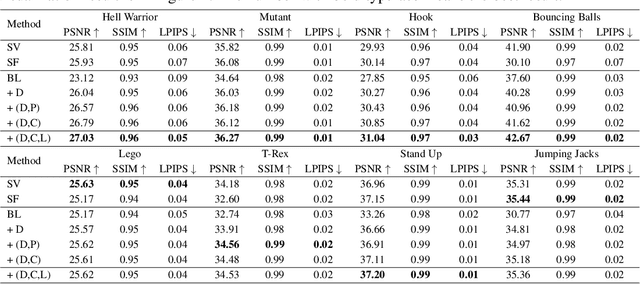
Neural radiance fields have made a remarkable breakthrough in the novel view synthesis task at the 3D static scene. However, for the 4D circumstance (e.g., dynamic scene), the performance of the existing method is still limited by the capacity of the neural network, typically in a multilayer perceptron network (MLP). In this paper, we present the method to model the 4D neural radiance field by the 3D voxel, short as V4D, where the 3D voxel has two formats. The first one is to regularly model the bounded 3D space and then use the sampled local 3D feature with the time index to model the density field and the texture field. The second one is in look-up tables (LUTs) format that is for the pixel-level refinement, where the pseudo-surface produced by the volume rendering is utilized as the guidance information to learn a 2D pixel-level refinement mapping. The proposed LUTs-based refinement module achieves the performance gain with a little computational cost and could serve as the plug-and-play module in the novel view synthesis task. Moreover, we propose a more effective conditional positional encoding toward the 4D data that achieves performance gain with negligible computational burdens. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance by a large margin. At last, the proposed V4D is also a computational-friendly method in both the training and testing phase, where we achieve 2 times faster in the training phase and 10 times faster in the inference phase compared with the state-of-the-art method.
ES6D: A Computation Efficient and Symmetry-Aware 6D Pose Regression Framework
Apr 03, 2022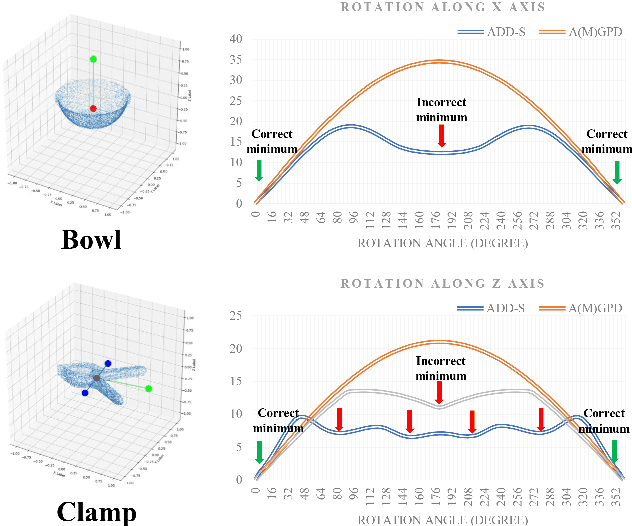

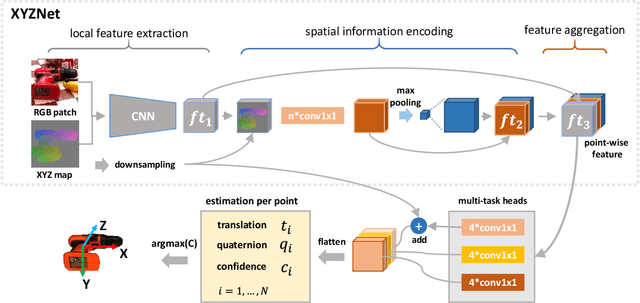

In this paper, a computation efficient regression framework is presented for estimating the 6D pose of rigid objects from a single RGB-D image, which is applicable to handling symmetric objects. This framework is designed in a simple architecture that efficiently extracts point-wise features from RGB-D data using a fully convolutional network, called XYZNet, and directly regresses the 6D pose without any post refinement. In the case of symmetric object, one object has multiple ground-truth poses, and this one-to-many relationship may lead to estimation ambiguity. In order to solve this ambiguity problem, we design a symmetry-invariant pose distance metric, called average (maximum) grouped primitives distance or A(M)GPD. The proposed A(M)GPD loss can make the regression network converge to the correct state, i.e., all minima in the A(M)GPD loss surface are mapped to the correct poses. Extensive experiments on YCB-Video and T-LESS datasets demonstrate the proposed framework's substantially superior performance in top accuracy and low computational cost.