 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV4D: Voxel for 4D Novel View Synthesis
Paper and Code
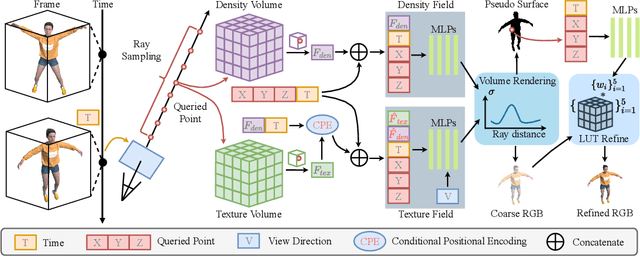
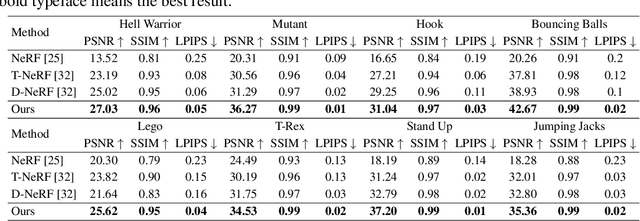
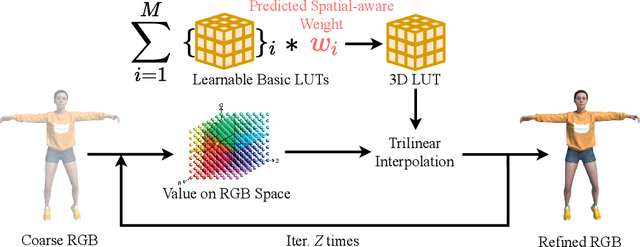
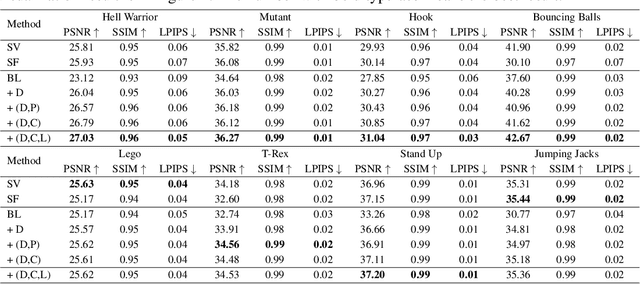
Neural radiance fields have made a remarkable breakthrough in the novel view synthesis task at the 3D static scene. However, for the 4D circumstance (e.g., dynamic scene), the performance of the existing method is still limited by the capacity of the neural network, typically in a multilayer perceptron network (MLP). In this paper, we present the method to model the 4D neural radiance field by the 3D voxel, short as V4D, where the 3D voxel has two formats. The first one is to regularly model the bounded 3D space and then use the sampled local 3D feature with the time index to model the density field and the texture field. The second one is in look-up tables (LUTs) format that is for the pixel-level refinement, where the pseudo-surface produced by the volume rendering is utilized as the guidance information to learn a 2D pixel-level refinement mapping. The proposed LUTs-based refinement module achieves the performance gain with a little computational cost and could serve as the plug-and-play module in the novel view synthesis task. Moreover, we propose a more effective conditional positional encoding toward the 4D data that achieves performance gain with negligible computational burdens. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance by a large margin. At last, the proposed V4D is also a computational-friendly method in both the training and testing phase, where we achieve 2 times faster in the training phase and 10 times faster in the inference phase compared with the state-of-the-art method.