 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Transfer: Leveraging Vision Foundation Model for Rapid Building Damage Mapping with Post-Earthquake VHR Imagery
Apr 03, 2026Living in a changing climate, human society now faces more frequent and severe natural disasters than ever before. As a consequence, rapid disaster response during the "Golden 72 Hours" of search and rescue becomes a vital humanitarian necessity and community concern. However, traditional disaster damage surveys routinely fail to generalize across distinct urban morphologies and new disaster events. Effective damage mapping typically requires exhaustive and time-consuming manual data annotation. To address this issue, we introduce Smart Transfer, a novel Geospatial Artificial Intelligence (GeoAI) framework, leveraging state-of-the-art vision Foundation Models (FMs) for rapid building damage mapping with post-earthquake Very High Resolution (VHR) imagery. Specifically, we design two novel model transfer strategies: first, Pixel-wise Clustering (PC), ensuring robust prototype-level global feature alignment; second, a Distance-Penalized Triplet (DPT), integrating patch-level spatial autocorrelation patterns by assigning stronger penalties to semantically inconsistent yet spatially adjacent patches. Extensive experiments and ablations from the recent 2023 Turkiye-Syria earthquake show promising performance in multiple cross-region transfer settings, namely Leave One Domain Out (LODO) and Specific Source Domain Combination (SSDC). Moreover, Smart Transfer provides a scalable, automated GeoAI solution to accelerate building damage mapping and support rapid disaster response, offering new opportunities to enhance disaster resilience in climate-vulnerable regions and communities. The data and code are publicly available at https://github.com/ai4city-hkust/SmartTransfer.
OpenEarth-Agent: From Tool Calling to Tool Creation for Open-Environment Earth Observation
Mar 23, 2026Earth Observation (EO) is essential for perceiving dynamic land surface changes, yet deploying autonomous EO in open environments is hindered by the immense diversity of multi-source data and heterogeneous tasks. While remote sensing agents have emerged to streamline EO workflows, existing tool-calling agents are confined to closed environments. They rely on pre-defined tools and are restricted to narrow scope, limiting their generalization to the diverse data and tasks. To overcome these limitations, we introduce OpenEarth-Agent, the first tool-creation agent framework tailored for open-environment EO. Rather than calling predefined tools, OpenEarth-Agent employs adaptive workflow planning and tool creation to generalize to unseen data and tasks. This adaptability is bolstered by an open-ended integration of multi-stage tools and cross-domain knowledge bases, enabling robust execution in the entire EO pipeline across multiple application domains. To comprehensively evaluate EO agents in open environments, we propose OpenEarth-Bench, a novel benchmark comprising 596 real-world, full-pipeline cases across seven application domains, explicitly designed to assess agents' adaptive planning and tool creation capabilities. Only essential pre-trained model tools are provided in this benchmark, devoid of any other predefined task-specific tools. Extensive experiments demonstrate that OpenEarth-Agent successfully masters full-pipeline EO across multiple domains in the open environment. Notably, on the cross-benchmark Earth-Bench, our tool-creating agent equipped with 6 essential pre-trained models achieves performance comparable to tool-calling agents relying on 104 specialized tools, and significantly outperforms them when provided with the complete toolset. In several cases, the created tools exhibit superior robustness to data anomalies compared to human-engineered counterparts.
MM-OVSeg:Multimodal Optical-SAR Fusion for Open-Vocabulary Segmentation in Remote Sensing
Mar 18, 2026Open-vocabulary segmentation enables pixel-level recognition from an open set of textual categories, allowing generalization beyond fixed classes. Despite great potential in remote sensing, progress in this area remains largely limited to clear-sky optical data and struggles under cloudy or haze-contaminated conditions. We present MM-OVSeg, a multimodal Optical-SAR fusion framework for resilient open-vocabulary segmentation under adverse weather conditions. MM-OVSeg leverages the complementary strengths of the two modalities--optical imagery provides rich spectral semantics, while synthetic aperture radar (SAR) offers cloud-penetrating structural cues. To address the cross-modal domain gap and the limited dense prediction capability of current vision-language models, we propose two key designs: a cross-modal unification process for multi-sensor representation alignment, and a dual-encoder fusion module that integrates hierarchical features from multiple vision foundation models for text-aligned multimodal segmentation. Extensive experiments demonstrate that MM-OVSeg achieves superior robustness and generalization across diverse cloud conditions. The source dataset and code are available here.
Direction-aware 3D Large Multimodal Models
Feb 22, 20263D large multimodal models (3D LMMs) rely heavily on ego poses for enabling directional question-answering and spatial reasoning. However, most existing point cloud benchmarks contain rich directional queries but lack the corresponding ego poses, making them inherently ill-posed in 3D large multimodal modelling. In this work, we redefine a new and rigorous paradigm that enables direction-aware 3D LMMs by identifying and supplementing ego poses into point cloud benchmarks and transforming the corresponding point cloud data according to the identified ego poses. We enable direction-aware 3D LMMs with two novel designs. The first is PoseRecover, a fully automatic pose recovery pipeline that matches questions with ego poses from RGB-D video extrinsics via object-frustum intersection and visibility check with Z-buffers. The second is PoseAlign that transforms the point cloud data to be aligned with the identified ego poses instead of either injecting ego poses into textual prompts or introducing pose-encoded features in the projection layers. Extensive experiments show that our designs yield consistent improvements across multiple 3D LMM backbones such as LL3DA, LL3DA-SONATA, Chat-Scene, and 3D-LLAVA, improving ScanRefer mIoU by 30.0% and Scan2Cap LLM-as-judge accuracy by 11.7%. In addition, our approach is simple, generic, and training-efficient, requiring only instruction tuning while establishing a strong baseline for direction-aware 3D-LMMs.
Experience-Driven Multi-Agent Systems Are Training-free Context-aware Earth Observers
Jan 30, 2026Recent advances have enabled large language model (LLM) agents to solve complex tasks by orchestrating external tools. However, these agents often struggle in specialized, tool-intensive domains that demand long-horizon execution, tight coordination across modalities, and strict adherence to implicit tool constraints. Earth Observation (EO) tasks exemplify this challenge due to the multi-modal and multi-temporal data inputs, as well as the requirements of geo-knowledge constraints (spectrum library, spatial reasoning, etc): many high-level plans can be derailed by subtle execution errors that propagate through a pipeline and invalidate final results. A core difficulty is that existing agents lack a mechanism to learn fine-grained, tool-level expertise from interaction. Without such expertise, they cannot reliably configure tool parameters or recover from mid-execution failures, limiting their effectiveness in complex EO workflows. To address this, we introduce \textbf{GeoEvolver}, a self-evolving multi-agent system~(MAS) that enables LLM agents to acquire EO expertise through structured interaction without any parameter updates. GeoEvolver decomposes each query into independent sub-goals via a retrieval-augmented multi-agent orchestrator, then explores diverse tool-parameter configurations at the sub-goal level. Successful patterns and root-cause attribution from failures are then distilled in an evolving memory bank that provides in-context demonstrations for future queries. Experiments on three tool-integrated EO benchmarks show that GeoEvolver consistently improves end-to-end task success, with an average gain of 12\% across multiple LLM backbones, demonstrating that EO expertise can emerge progressively from efficient, fine-grained interactions with the environment.
The Confidence Dichotomy: Analyzing and Mitigating Miscalibration in Tool-Use Agents
Jan 12, 2026Autonomous agents based on large language models (LLMs) are rapidly evolving to handle multi-turn tasks, but ensuring their trustworthiness remains a critical challenge. A fundamental pillar of this trustworthiness is calibration, which refers to an agent's ability to express confidence that reliably reflects its actual performance. While calibration is well-established for static models, its dynamics in tool-integrated agentic workflows remain underexplored. In this work, we systematically investigate verbalized calibration in tool-use agents, revealing a fundamental confidence dichotomy driven by tool type. Specifically, our pilot study identifies that evidence tools (e.g., web search) systematically induce severe overconfidence due to inherent noise in retrieved information, while verification tools (e.g., code interpreters) can ground reasoning through deterministic feedback and mitigate miscalibration. To robustly improve calibration across tool types, we propose a reinforcement learning (RL) fine-tuning framework that jointly optimizes task accuracy and calibration, supported by a holistic benchmark of reward designs. We demonstrate that our trained agents not only achieve superior calibration but also exhibit robust generalization from local training environments to noisy web settings and to distinct domains such as mathematical reasoning. Our results highlight the necessity of domain-specific calibration strategies for tool-use agents. More broadly, this work establishes a foundation for building self-aware agents that can reliably communicate uncertainty in high-stakes, real-world deployments.
Geo3DVQA: Evaluating Vision-Language Models for 3D Geospatial Reasoning from Aerial Imagery
Dec 21, 2025Three-dimensional geospatial analysis is critical for applications in urban planning, climate adaptation, and environmental assessment. However, current methodologies depend on costly, specialized sensors, such as LiDAR and multispectral sensors, which restrict global accessibility. Additionally, existing sensor-based and rule-driven methods struggle with tasks requiring the integration of multiple 3D cues, handling diverse queries, and providing interpretable reasoning. We present Geo3DVQA, a comprehensive benchmark that evaluates vision-language models (VLMs) in height-aware 3D geospatial reasoning from RGB imagery alone. Unlike conventional sensor-based frameworks, Geo3DVQA emphasizes realistic scenarios integrating elevation, sky view factors, and land cover patterns. The benchmark comprises 110k curated question-answer pairs across 16 task categories, including single-feature inference, multi-feature reasoning, and application-level analysis. Through a systematic evaluation of ten state-of-the-art VLMs, we reveal fundamental limitations in RGB-to-3D spatial reasoning. Our results further show that domain-specific instruction tuning consistently enhances model performance across all task categories, including height-aware and open-ended, application-oriented reasoning. Geo3DVQA provides a unified, interpretable framework for evaluating RGB-based 3D geospatial reasoning and identifies key challenges and opportunities for scalable 3D spatial analysis. The code and data are available at https://github.com/mm1129/Geo3DVQA.
Hyperspectral Imaging
Aug 11, 2025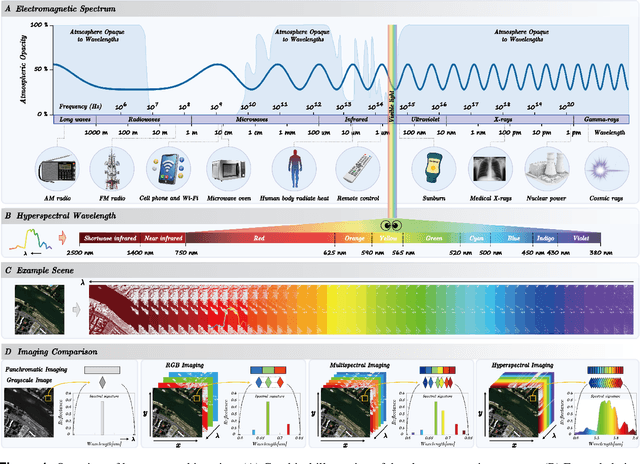
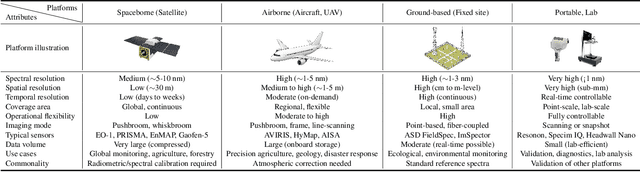
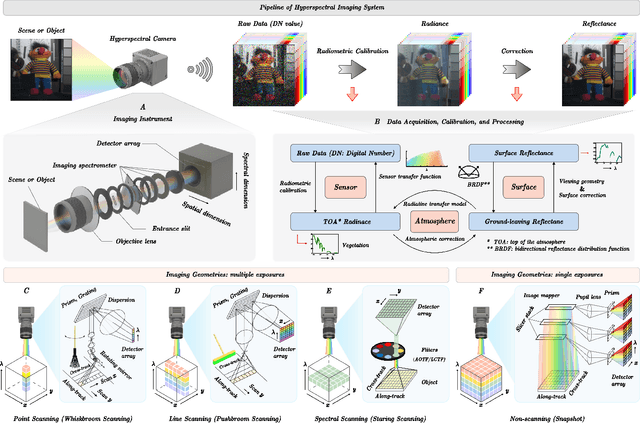

Hyperspectral imaging (HSI) is an advanced sensing modality that simultaneously captures spatial and spectral information, enabling non-invasive, label-free analysis of material, chemical, and biological properties. This Primer presents a comprehensive overview of HSI, from the underlying physical principles and sensor architectures to key steps in data acquisition, calibration, and correction. We summarize common data structures and highlight classical and modern analysis methods, including dimensionality reduction, classification, spectral unmixing, and AI-driven techniques such as deep learning. Representative applications across Earth observation, precision agriculture, biomedicine, industrial inspection, cultural heritage, and security are also discussed, emphasizing HSI's ability to uncover sub-visual features for advanced monitoring, diagnostics, and decision-making. Persistent challenges, such as hardware trade-offs, acquisition variability, and the complexity of high-dimensional data, are examined alongside emerging solutions, including computational imaging, physics-informed modeling, cross-modal fusion, and self-supervised learning. Best practices for dataset sharing, reproducibility, and metadata documentation are further highlighted to support transparency and reuse. Looking ahead, we explore future directions toward scalable, real-time, and embedded HSI systems, driven by sensor miniaturization, self-supervised learning, and foundation models. As HSI evolves into a general-purpose, cross-disciplinary platform, it holds promise for transformative applications in science, technology, and society.
DynamicVL: Benchmarking Multimodal Large Language Models for Dynamic City Understanding
May 27, 2025Multimodal large language models have demonstrated remarkable capabilities in visual understanding, but their application to long-term Earth observation analysis remains limited, primarily focusing on single-temporal or bi-temporal imagery. To address this gap, we introduce DVL-Suite, a comprehensive framework for analyzing long-term urban dynamics through remote sensing imagery. Our suite comprises 15,063 high-resolution (1.0m) multi-temporal images spanning 42 megacities in the U.S. from 2005 to 2023, organized into two components: DVL-Bench and DVL-Instruct. The DVL-Bench includes seven urban understanding tasks, from fundamental change detection (pixel-level) to quantitative analyses (regional-level) and comprehensive urban narratives (scene-level), capturing diverse urban dynamics including expansion/transformation patterns, disaster assessment, and environmental challenges. We evaluate 17 state-of-the-art multimodal large language models and reveal their limitations in long-term temporal understanding and quantitative analysis. These challenges motivate the creation of DVL-Instruct, a specialized instruction-tuning dataset designed to enhance models' capabilities in multi-temporal Earth observation. Building upon this dataset, we develop DVLChat, a baseline model capable of both image-level question-answering and pixel-level segmentation, facilitating a comprehensive understanding of city dynamics through language interactions.
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response
May 27, 2025Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities.