 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamicVL: Benchmarking Multimodal Large Language Models for Dynamic City Understanding
May 27, 2025Multimodal large language models have demonstrated remarkable capabilities in visual understanding, but their application to long-term Earth observation analysis remains limited, primarily focusing on single-temporal or bi-temporal imagery. To address this gap, we introduce DVL-Suite, a comprehensive framework for analyzing long-term urban dynamics through remote sensing imagery. Our suite comprises 15,063 high-resolution (1.0m) multi-temporal images spanning 42 megacities in the U.S. from 2005 to 2023, organized into two components: DVL-Bench and DVL-Instruct. The DVL-Bench includes seven urban understanding tasks, from fundamental change detection (pixel-level) to quantitative analyses (regional-level) and comprehensive urban narratives (scene-level), capturing diverse urban dynamics including expansion/transformation patterns, disaster assessment, and environmental challenges. We evaluate 17 state-of-the-art multimodal large language models and reveal their limitations in long-term temporal understanding and quantitative analysis. These challenges motivate the creation of DVL-Instruct, a specialized instruction-tuning dataset designed to enhance models' capabilities in multi-temporal Earth observation. Building upon this dataset, we develop DVLChat, a baseline model capable of both image-level question-answering and pixel-level segmentation, facilitating a comprehensive understanding of city dynamics through language interactions.
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response
May 27, 2025Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities.
SARLANG-1M: A Benchmark for Vision-Language Modeling in SAR Image Understanding
Apr 04, 2025
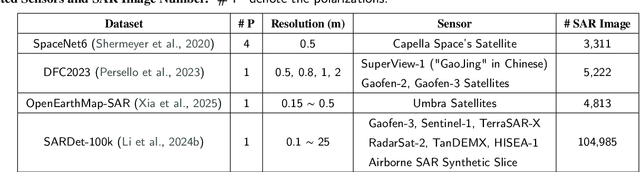

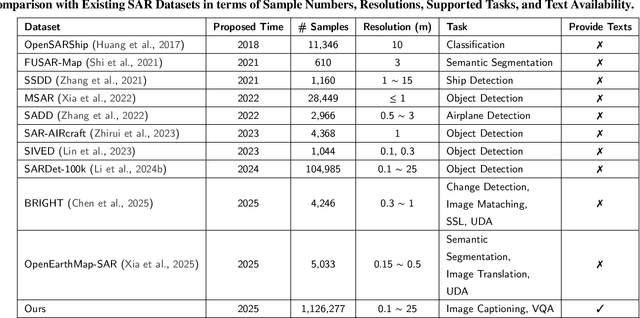
Synthetic Aperture Radar (SAR) is a crucial remote sensing technology, enabling all-weather, day-and-night observation with strong surface penetration for precise and continuous environmental monitoring and analysis. However, SAR image interpretation remains challenging due to its complex physical imaging mechanisms and significant visual disparities from human perception. Recently, Vision-Language Models (VLMs) have demonstrated remarkable success in RGB image understanding, offering powerful open-vocabulary interpretation and flexible language interaction. However, their application to SAR images is severely constrained by the absence of SAR-specific knowledge in their training distributions, leading to suboptimal performance. To address this limitation, we introduce SARLANG-1M, a large-scale benchmark tailored for multimodal SAR image understanding, with a primary focus on integrating SAR with textual modality. SARLANG-1M comprises more than 1 million high-quality SAR image-text pairs collected from over 59 cities worldwide. It features hierarchical resolutions (ranging from 0.1 to 25 meters), fine-grained semantic descriptions (including both concise and detailed captions), diverse remote sensing categories (1,696 object types and 16 land cover classes), and multi-task question-answering pairs spanning seven applications and 1,012 question types. Extensive experiments on mainstream VLMs demonstrate that fine-tuning with SARLANG-1M significantly enhances their performance in SAR image interpretation, reaching performance comparable to human experts. The dataset and code will be made publicly available at https://github.com/Jimmyxichen/SARLANG-1M.
OpenEarthMap-SAR: A Benchmark Synthetic Aperture Radar Dataset for Global High-Resolution Land Cover Mapping
Jan 18, 2025



High-resolution land cover mapping plays a crucial role in addressing a wide range of global challenges, including urban planning, environmental monitoring, disaster response, and sustainable development. However, creating accurate, large-scale land cover datasets remains a significant challenge due to the inherent complexities of geospatial data, such as diverse terrain, varying sensor modalities, and atmospheric conditions. Synthetic Aperture Radar (SAR) imagery, with its ability to penetrate clouds and capture data in all-weather, day-and-night conditions, offers unique advantages for land cover mapping. Despite these strengths, the lack of benchmark datasets tailored for SAR imagery has limited the development of robust models specifically designed for this data modality. To bridge this gap and facilitate advancements in SAR-based geospatial analysis, we introduce OpenEarthMap-SAR, a benchmark SAR dataset, for global high-resolution land cover mapping. OpenEarthMap-SAR consists of 1.5 million segments of 5033 aerial and satellite images with the size of 1024$\times$1024 pixels, covering 35 regions from Japan, France, and the USA, with partially manually annotated and fully pseudo 8-class land cover labels at a ground sampling distance of 0.15--0.5 m. We evaluated the performance of state-of-the-art methods for semantic segmentation and present challenging problem settings suitable for further technical development. The dataset also serves the official dataset for IEEE GRSS Data Fusion Contest Track I. The dataset has been made publicly available at https://zenodo.org/records/14622048.
BRIGHT: A globally distributed multimodal building damage assessment dataset with very-high-resolution for all-weather disaster response
Jan 10, 2025



Disaster events occur around the world and cause significant damage to human life and property. Earth observation (EO) data enables rapid and comprehensive building damage assessment (BDA), an essential capability in the aftermath of a disaster to reduce human casualties and to inform disaster relief efforts. Recent research focuses on the development of AI models to achieve accurate mapping of unseen disaster events, mostly using optical EO data. However, solutions based on optical data are limited to clear skies and daylight hours, preventing a prompt response to disasters. Integrating multimodal (MM) EO data, particularly the combination of optical and SAR imagery, makes it possible to provide all-weather, day-and-night disaster responses. Despite this potential, the development of robust multimodal AI models has been constrained by the lack of suitable benchmark datasets. In this paper, we present a BDA dataset using veRy-hIGH-resoluTion optical and SAR imagery (BRIGHT) to support AI-based all-weather disaster response. To the best of our knowledge, BRIGHT is the first open-access, globally distributed, event-diverse MM dataset specifically curated to support AI-based disaster response. It covers five types of natural disasters and two types of man-made disasters across 12 regions worldwide, with a particular focus on developing countries where external assistance is most needed. The optical and SAR imagery in BRIGHT, with a spatial resolution between 0.3-1 meters, provides detailed representations of individual buildings, making it ideal for precise BDA. In our experiments, we have tested seven advanced AI models trained with our BRIGHT to validate the transferability and robustness. The dataset and code are available at https://github.com/ChenHongruixuan/BRIGHT. BRIGHT also serves as the official dataset for the 2025 IEEE GRSS Data Fusion Contest.
Generalized Few-Shot Semantic Segmentation in Remote Sensing: Challenge and Benchmark
Sep 17, 2024



Learning with limited labelled data is a challenging problem in various applications, including remote sensing. Few-shot semantic segmentation is one approach that can encourage deep learning models to learn from few labelled examples for novel classes not seen during the training. The generalized few-shot segmentation setting has an additional challenge which encourages models not only to adapt to the novel classes but also to maintain strong performance on the training base classes. While previous datasets and benchmarks discussed the few-shot segmentation setting in remote sensing, we are the first to propose a generalized few-shot segmentation benchmark for remote sensing. The generalized setting is more realistic and challenging, which necessitates exploring it within the remote sensing context. We release the dataset augmenting OpenEarthMap with additional classes labelled for the generalized few-shot evaluation setting. The dataset is released during the OpenEarthMap land cover mapping generalized few-shot challenge in the L3D-IVU workshop in conjunction with CVPR 2024. In this work, we summarize the dataset and challenge details in addition to providing the benchmark results on the two phases of the challenge for the validation and test sets.
SynRS3D: A Synthetic Dataset for Global 3D Semantic Understanding from Monocular Remote Sensing Imagery
Jun 26, 2024



Global semantic 3D understanding from single-view high-resolution remote sensing (RS) imagery is crucial for Earth Observation (EO). However, this task faces significant challenges due to the high costs of annotations and data collection, as well as geographically restricted data availability. To address these challenges, synthetic data offer a promising solution by being easily accessible and thus enabling the provision of large and diverse datasets. We develop a specialized synthetic data generation pipeline for EO and introduce SynRS3D, the largest synthetic RS 3D dataset. SynRS3D comprises 69,667 high-resolution optical images that cover six different city styles worldwide and feature eight land cover types, precise height information, and building change masks. To further enhance its utility, we develop a novel multi-task unsupervised domain adaptation (UDA) method, RS3DAda, coupled with our synthetic dataset, which facilitates the RS-specific transition from synthetic to real scenarios for land cover mapping and height estimation tasks, ultimately enabling global monocular 3D semantic understanding based on synthetic data. Extensive experiments on various real-world datasets demonstrate the adaptability and effectiveness of our synthetic dataset and proposed RS3DAda method. SynRS3D and related codes will be available.
Unsupervised Domain Adaptation Architecture Search with Self-Training for Land Cover Mapping
Apr 23, 2024Unsupervised domain adaptation (UDA) is a challenging open problem in land cover mapping. Previous studies show encouraging progress in addressing cross-domain distribution shifts on remote sensing benchmarks for land cover mapping. The existing works are mainly built on large neural network architectures, which makes them resource-hungry systems, limiting their practical impact for many real-world applications in resource-constrained environments. Thus, we proposed a simple yet effective framework to search for lightweight neural networks automatically for land cover mapping tasks under domain shifts. This is achieved by integrating Markov random field neural architecture search (MRF-NAS) into a self-training UDA framework to search for efficient and effective networks under a limited computation budget. This is the first attempt to combine NAS with self-training UDA as a single framework for land cover mapping. We also investigate two different pseudo-labelling approaches (confidence-based and energy-based) in self-training scheme. Experimental results on two recent datasets (OpenEarthMap & FLAIR #1) for remote sensing UDA demonstrate a satisfactory performance. With only less than 2M parameters and 30.16 GFLOPs, the best-discovered lightweight network reaches state-of-the-art performance on the regional target domain of OpenEarthMap (59.38% mIoU) and the considered target domain of FLAIR #1 (51.19% mIoU). The code is at https://github.com/cliffbb/UDA-NAS}{https://github.com/cliffbb/UDA-NAS.
ChangeMamba: Remote Sensing Change Detection with Spatio-Temporal State Space Model
Apr 14, 2024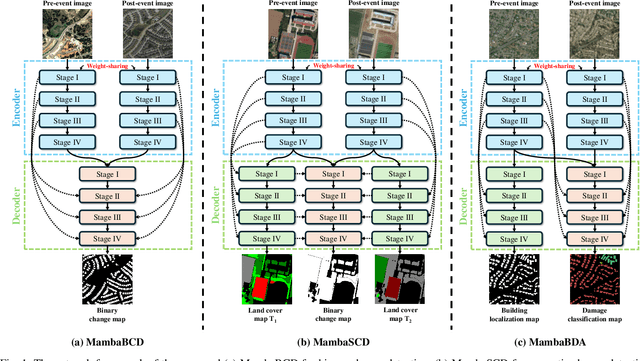
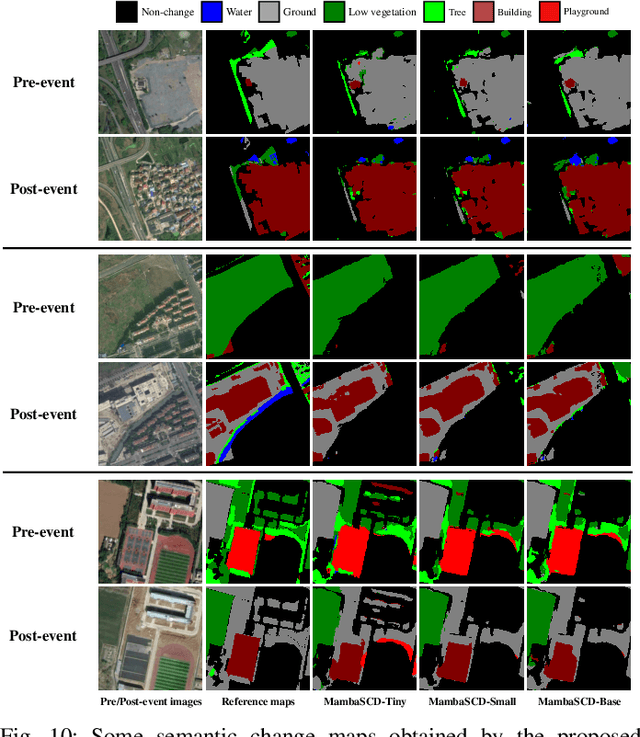
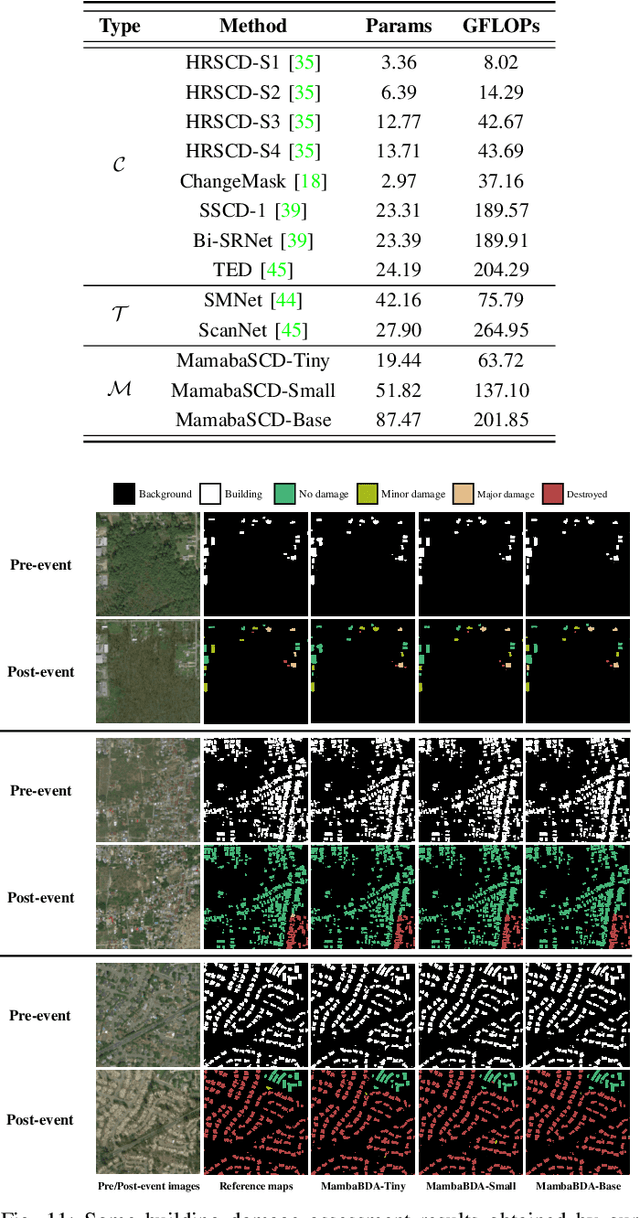

Convolutional neural networks (CNN) and Transformers have made impressive progress in the field of remote sensing change detection (CD). However, both architectures have inherent shortcomings. Recently, the Mamba architecture, based on state space models, has shown remarkable performance in a series of natural language processing tasks, which can effectively compensate for the shortcomings of the above two architectures. In this paper, we explore for the first time the potential of the Mamba architecture for remote sensing CD tasks. We tailor the corresponding frameworks, called MambaBCD, MambaSCD, and MambaBDA, for binary change detection (BCD), semantic change detection (SCD), and building damage assessment (BDA), respectively. All three frameworks adopt the cutting-edge Visual Mamba architecture as the encoder, which allows full learning of global spatial contextual information from the input images. For the change decoder, which is available in all three architectures, we propose three spatio-temporal relationship modeling mechanisms, which can be naturally combined with the Mamba architecture and fully utilize its attribute to achieve spatio-temporal interaction of multi-temporal features, thereby obtaining accurate change information. On five benchmark datasets, our proposed frameworks outperform current CNN- and Transformer-based approaches without using any complex training strategies or tricks, fully demonstrating the potential of the Mamba architecture in CD tasks. Specifically, we obtained 83.11%, 88.39% and 94.19% F1 scores on the three BCD datasets SYSU, LEVIR-CD+, and WHU-CD; on the SCD dataset SECOND, we obtained 24.11% SeK; and on the BDA dataset xBD, we obtained 81.41% overall F1 score. Further experiments show that our architecture is quite robust to degraded data. The source code will be available in https://github.com/ChenHongruixuan/MambaCD
Submeter-level Land Cover Mapping of Japan
Nov 19, 2023



Deep learning has shown promising performance in submeter-level mapping tasks; however, the annotation cost of submeter-level imagery remains a challenge, especially when applied on a large scale. In this paper, we present the first submeter-level land cover mapping of Japan with eight classes, at a relatively low annotation cost. We introduce a human-in-the-loop deep learning framework leveraging OpenEarthMap, a recently introduced benchmark dataset for global submeter-level land cover mapping, with a U-Net model that achieves national-scale mapping with a small amount of additional labeled data. By adding a small amount of labeled data of areas or regions where a U-Net model trained on OpenEarthMap clearly failed and retraining the model, an overall accuracy of 80\% was achieved, which is a nearly 16 percentage point improvement after retraining. Using aerial imagery provided by the Geospatial Information Authority of Japan, we create land cover classification maps of eight classes for the entire country of Japan. Our framework, with its low annotation cost and high-accuracy mapping results, demonstrates the potential to contribute to the automatic updating of national-scale land cover mapping using submeter-level optical remote sensing data. The mapping results will be made publicly available.