 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-OVSeg:Multimodal Optical-SAR Fusion for Open-Vocabulary Segmentation in Remote Sensing
Mar 18, 2026Open-vocabulary segmentation enables pixel-level recognition from an open set of textual categories, allowing generalization beyond fixed classes. Despite great potential in remote sensing, progress in this area remains largely limited to clear-sky optical data and struggles under cloudy or haze-contaminated conditions. We present MM-OVSeg, a multimodal Optical-SAR fusion framework for resilient open-vocabulary segmentation under adverse weather conditions. MM-OVSeg leverages the complementary strengths of the two modalities--optical imagery provides rich spectral semantics, while synthetic aperture radar (SAR) offers cloud-penetrating structural cues. To address the cross-modal domain gap and the limited dense prediction capability of current vision-language models, we propose two key designs: a cross-modal unification process for multi-sensor representation alignment, and a dual-encoder fusion module that integrates hierarchical features from multiple vision foundation models for text-aligned multimodal segmentation. Extensive experiments demonstrate that MM-OVSeg achieves superior robustness and generalization across diverse cloud conditions. The source dataset and code are available here.
PacGDC: Label-Efficient Generalizable Depth Completion with Projection Ambiguity and Consistency
Jul 10, 2025Generalizable depth completion enables the acquisition of dense metric depth maps for unseen environments, offering robust perception capabilities for various downstream tasks. However, training such models typically requires large-scale datasets with metric depth labels, which are often labor-intensive to collect. This paper presents PacGDC, a label-efficient technique that enhances data diversity with minimal annotation effort for generalizable depth completion. PacGDC builds on novel insights into inherent ambiguities and consistencies in object shapes and positions during 2D-to-3D projection, allowing the synthesis of numerous pseudo geometries for the same visual scene. This process greatly broadens available geometries by manipulating scene scales of the corresponding depth maps. To leverage this property, we propose a new data synthesis pipeline that uses multiple depth foundation models as scale manipulators. These models robustly provide pseudo depth labels with varied scene scales, affecting both local objects and global layouts, while ensuring projection consistency that supports generalization. To further diversify geometries, we incorporate interpolation and relocation strategies, as well as unlabeled images, extending the data coverage beyond the individual use of foundation models. Extensive experiments show that PacGDC achieves remarkable generalizability across multiple benchmarks, excelling in diverse scene semantics/scales and depth sparsity/patterns under both zero-shot and few-shot settings. Code: https://github.com/Wang-xjtu/PacGDC.
SARLANG-1M: A Benchmark for Vision-Language Modeling in SAR Image Understanding
Apr 04, 2025
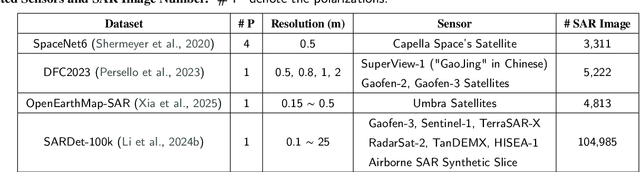

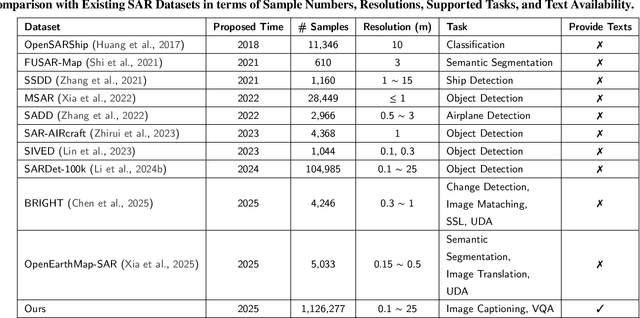
Synthetic Aperture Radar (SAR) is a crucial remote sensing technology, enabling all-weather, day-and-night observation with strong surface penetration for precise and continuous environmental monitoring and analysis. However, SAR image interpretation remains challenging due to its complex physical imaging mechanisms and significant visual disparities from human perception. Recently, Vision-Language Models (VLMs) have demonstrated remarkable success in RGB image understanding, offering powerful open-vocabulary interpretation and flexible language interaction. However, their application to SAR images is severely constrained by the absence of SAR-specific knowledge in their training distributions, leading to suboptimal performance. To address this limitation, we introduce SARLANG-1M, a large-scale benchmark tailored for multimodal SAR image understanding, with a primary focus on integrating SAR with textual modality. SARLANG-1M comprises more than 1 million high-quality SAR image-text pairs collected from over 59 cities worldwide. It features hierarchical resolutions (ranging from 0.1 to 25 meters), fine-grained semantic descriptions (including both concise and detailed captions), diverse remote sensing categories (1,696 object types and 16 land cover classes), and multi-task question-answering pairs spanning seven applications and 1,012 question types. Extensive experiments on mainstream VLMs demonstrate that fine-tuning with SARLANG-1M significantly enhances their performance in SAR image interpretation, reaching performance comparable to human experts. The dataset and code will be made publicly available at https://github.com/Jimmyxichen/SARLANG-1M.
A Vision Centric Remote Sensing Benchmark
Mar 20, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable success in vision-language tasks but their remote sensing (RS) counterpart are relatively under explored. Unlike natural images, RS imagery presents unique challenges that current MLLMs struggle to handle, particularly in visual grounding and spatial reasoning. This study investigates the limitations of CLIP-based MLLMs in RS, highlighting their failure to differentiate visually distinct yet semantically similar RS images. To address this, we introduce a remote sensing multimodal visual patterns (RSMMVP) benchmark. It is designed to evaluate MLLMs in RS tasks by identifying the CLIP-blind pairs, where CLIP-based models incorrectly assign high similarity scores to visually distinct RS images. Through a visual question answering (VQA) evaluation, we analyze the performance of state-of-the-art MLLMs, revealing significant limitations in RS specific representation learning. The results provide valuable insights into the weaknesses of CLIP-based visual encoding and offer a foundation for future research to develop more effective MLLMs tailored for remote sensing applications.
Foundation Models for Remote Sensing and Earth Observation: A Survey
Oct 22, 2024



Remote Sensing (RS) is a crucial technology for observing, monitoring, and interpreting our planet, with broad applications across geoscience, economics, humanitarian fields, etc. While artificial intelligence (AI), particularly deep learning, has achieved significant advances in RS, unique challenges persist in developing more intelligent RS systems, including the complexity of Earth's environments, diverse sensor modalities, distinctive feature patterns, varying spatial and spectral resolutions, and temporal dynamics. Meanwhile, recent breakthroughs in large Foundation Models (FMs) have expanded AI's potential across many domains due to their exceptional generalizability and zero-shot transfer capabilities. However, their success has largely been confined to natural data like images and video, with degraded performance and even failures for RS data of various non-optical modalities. This has inspired growing interest in developing Remote Sensing Foundation Models (RSFMs) to address the complex demands of Earth Observation (EO) tasks, spanning the surface, atmosphere, and oceans. This survey systematically reviews the emerging field of RSFMs. It begins with an outline of their motivation and background, followed by an introduction of their foundational concepts. It then categorizes and reviews existing RSFM studies including their datasets and technical contributions across Visual Foundation Models (VFMs), Visual-Language Models (VLMs), Large Language Models (LLMs), and beyond. In addition, we benchmark these models against publicly available datasets, discuss existing challenges, and propose future research directions in this rapidly evolving field.
Segment Anything with Multiple Modalities
Aug 17, 2024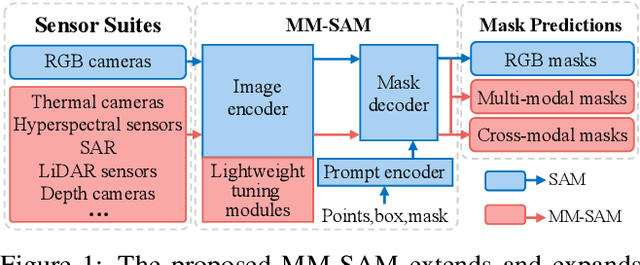


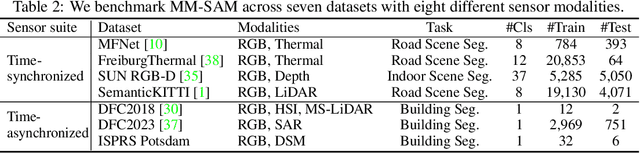
Robust and accurate segmentation of scenes has become one core functionality in various visual recognition and navigation tasks. This has inspired the recent development of Segment Anything Model (SAM), a foundation model for general mask segmentation. However, SAM is largely tailored for single-modal RGB images, limiting its applicability to multi-modal data captured with widely-adopted sensor suites, such as LiDAR plus RGB, depth plus RGB, thermal plus RGB, etc. We develop MM-SAM, an extension and expansion of SAM that supports cross-modal and multi-modal processing for robust and enhanced segmentation with different sensor suites. MM-SAM features two key designs, namely, unsupervised cross-modal transfer and weakly-supervised multi-modal fusion, enabling label-efficient and parameter-efficient adaptation toward various sensor modalities. It addresses three main challenges: 1) adaptation toward diverse non-RGB sensors for single-modal processing, 2) synergistic processing of multi-modal data via sensor fusion, and 3) mask-free training for different downstream tasks. Extensive experiments show that MM-SAM consistently outperforms SAM by large margins, demonstrating its effectiveness and robustness across various sensors and data modalities.
CAT-SAM: Conditional Tuning Network for Few-Shot Adaptation of Segmentation Anything Model
Feb 06, 2024

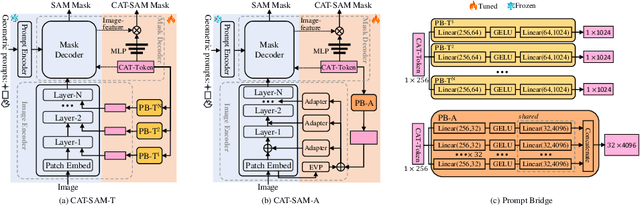
The recent Segment Anything Model (SAM) has demonstrated remarkable zero-shot capability and flexible geometric prompting in general image segmentation. However, SAM often struggles when handling various unconventional images, such as aerial, medical, and non-RGB images. This paper presents CAT-SAM, a ConditionAl Tuning network that adapts SAM toward various unconventional target tasks with just few-shot target samples. CAT-SAM freezes the entire SAM and adapts its mask decoder and image encoder simultaneously with a small number of learnable parameters. The core design is a prompt bridge structure that enables decoder-conditioned joint tuning of the heavyweight image encoder and the lightweight mask decoder. The bridging maps the prompt token of the mask decoder to the image encoder, fostering synergic adaptation of the encoder and the decoder with mutual benefits. We develop two representative tuning strategies for the image encoder which leads to two CAT-SAM variants: one injecting learnable prompt tokens in the input space and the other inserting lightweight adapter networks. Extensive experiments over 11 unconventional tasks show that both CAT-SAM variants achieve superior target segmentation performance consistently even under the very challenging one-shot adaptation setup. Project page: \url{https://xiaoaoran.github.io/projects/CAT-SAM}
Cross-Domain Few-Shot Segmentation via Iterative Support-Query Correspondence Mining
Jan 16, 2024



Cross-Domain Few-Shot Segmentation (CD-FSS) poses the challenge of segmenting novel categories from a distinct domain using only limited exemplars. In this paper, we undertake a comprehensive study of CD-FSS and uncover two crucial insights: (i) the necessity of a fine-tuning stage to effectively transfer the learned meta-knowledge across domains, and (ii) the overfitting risk during the na\"ive fine-tuning due to the scarcity of novel category examples. With these insights, we propose a novel cross-domain fine-tuning strategy that addresses the challenging CD-FSS tasks. We first design Bi-directional Few-shot Prediction (BFP), which establishes support-query correspondence in a bi-directional manner, crafting augmented supervision to reduce the overfitting risk. Then we further extend BFP into Iterative Few-shot Adaptor (IFA), which is a recursive framework to capture the support-query correspondence iteratively, targeting maximal exploitation of supervisory signals from the sparse novel category samples. Extensive empirical evaluations show that our method significantly outperforms the state-of-the-arts (+7.8\%), which verifies that IFA tackles the cross-domain challenges and mitigates the overfitting simultaneously. Code will be made available.
Bridging Semantic Gaps for Language-Supervised Semantic Segmentation
Sep 27, 2023



Vision-Language Pre-training has demonstrated its remarkable zero-shot recognition ability and potential to learn generalizable visual representations from language supervision. Taking a step ahead, language-supervised semantic segmentation enables spatial localization of textual inputs by learning pixel grouping solely from image-text pairs. Nevertheless, the state-of-the-art suffers from clear semantic gaps between visual and textual modality: plenty of visual concepts appeared in images are missing in their paired captions. Such semantic misalignment circulates in pre-training, leading to inferior zero-shot performance in dense predictions due to insufficient visual concepts captured in textual representations. To close such semantic gap, we propose Concept Curation (CoCu), a pipeline that leverages CLIP to compensate for the missing semantics. For each image-text pair, we establish a concept archive that maintains potential visually-matched concepts with our proposed vision-driven expansion and text-to-vision-guided ranking. Relevant concepts can thus be identified via cluster-guided sampling and fed into pre-training, thereby bridging the gap between visual and textual semantics. Extensive experiments over a broad suite of 8 segmentation benchmarks show that CoCu achieves superb zero-shot transfer performance and greatly boosts language-supervised segmentation baseline by a large margin, suggesting the value of bridging semantic gap in pre-training data.
A Survey of Label-Efficient Deep Learning for 3D Point Clouds
May 31, 2023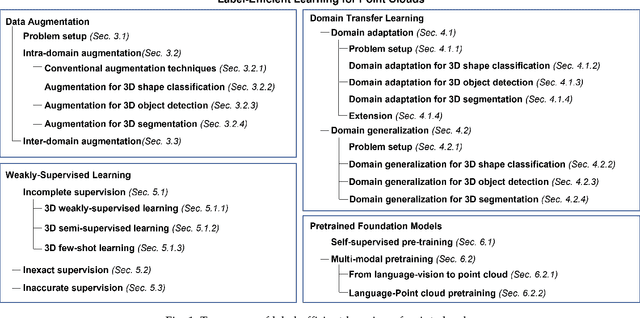

In the past decade, deep neural networks have achieved significant progress in point cloud learning. However, collecting large-scale precisely-annotated training data is extremely laborious and expensive, which hinders the scalability of existing point cloud datasets and poses a bottleneck for efficient exploration of point cloud data in various tasks and applications. Label-efficient learning offers a promising solution by enabling effective deep network training with much-reduced annotation efforts. This paper presents the first comprehensive survey of label-efficient learning of point clouds. We address three critical questions in this emerging research field: i) the importance and urgency of label-efficient learning in point cloud processing, ii) the subfields it encompasses, and iii) the progress achieved in this area. To achieve this, we propose a taxonomy that organizes label-efficient learning methods based on the data prerequisites provided by different types of labels. We categorize four typical label-efficient learning approaches that significantly reduce point cloud annotation efforts: data augmentation, domain transfer learning, weakly-supervised learning, and pretrained foundation models. For each approach, we outline the problem setup and provide an extensive literature review that showcases relevant progress and challenges. Finally, we share insights into current research challenges and potential future directions. A project associated with this survey has been built at \url{https://github.com/xiaoaoran/3D_label_efficient_learning}.