 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Adaptive Image Retouching Guided by Attribute-Based Text Representation
Dec 10, 2025Image retouching has received significant attention due to its ability to achieve high-quality visual content. Existing approaches mainly rely on uniform pixel-wise color mapping across entire images, neglecting the inherent color variations induced by image content. This limitation hinders existing approaches from achieving adaptive retouching that accommodates both diverse color distributions and user-defined style preferences. To address these challenges, we propose a novel Content-Adaptive image retouching method guided by Attribute-based Text Representation (CA-ATP). Specifically, we propose a content-adaptive curve mapping module, which leverages a series of basis curves to establish multiple color mapping relationships and learns the corresponding weight maps, enabling content-aware color adjustments. The proposed module can capture color diversity within the image content, allowing similar color values to receive distinct transformations based on their spatial context. In addition, we propose an attribute text prediction module that generates text representations from multiple image attributes, which explicitly represent user-defined style preferences. These attribute-based text representations are subsequently integrated with visual features via a multimodal model, providing user-friendly guidance for image retouching. Extensive experiments on several public datasets demonstrate that our method achieves state-of-the-art performance.
Voice Cloning: Comprehensive Survey
May 01, 2025Voice Cloning has rapidly advanced in today's digital world, with many researchers and corporations working to improve these algorithms for various applications. This article aims to establish a standardized terminology for voice cloning and explore its different variations. It will cover speaker adaptation as the fundamental concept and then delve deeper into topics such as few-shot, zero-shot, and multilingual TTS within that context. Finally, we will explore the evaluation metrics commonly used in voice cloning research and related datasets. This survey compiles the available voice cloning algorithms to encourage research toward its generation and detection to limit its misuse.
From ChatGPT to DeepSeek AI: A Comprehensive Analysis of Evolution, Deviation, and Future Implications in AI-Language Models
Apr 04, 2025



The rapid advancement of artificial intelligence (AI) has reshaped the field of natural language processing (NLP), with models like OpenAI ChatGPT and DeepSeek AI. Although ChatGPT established a strong foundation for conversational AI, DeepSeek AI introduces significant improvements in architecture, performance, and ethical considerations. This paper presents a detailed analysis of the evolution from ChatGPT to DeepSeek AI, highlighting their technical differences, practical applications, and broader implications for AI development. To assess their capabilities, we conducted a case study using a predefined set of multiple choice questions in various domains, evaluating the strengths and limitations of each model. By examining these aspects, we provide valuable insight into the future trajectory of AI, its potential to transform industries, and key research directions for improving AI-driven language models.
GroMo: Plant Growth Modeling with Multiview Images
Mar 09, 2025Understanding plant growth dynamics is essential for applications in agriculture and plant phenotyping. We present the Growth Modelling (GroMo) challenge, which is designed for two primary tasks: (1) plant age prediction and (2) leaf count estimation, both essential for crop monitoring and precision agriculture. For this challenge, we introduce GroMo25, a dataset with images of four crops: radish, okra, wheat, and mustard. Each crop consists of multiple plants (p1, p2, ..., pn) captured over different days (d1, d2, ..., dm) and categorized into five levels (L1, L2, L3, L4, L5). Each plant is captured from 24 different angles with a 15-degree gap between images. Participants are required to perform both tasks for all four crops with these multiview images. We proposed a Multiview Vision Transformer (MVVT) model for the GroMo challenge and evaluated the crop-wise performance on GroMo25. MVVT reports an average MAE of 7.74 for age prediction and an MAE of 5.52 for leaf count. The GroMo Challenge aims to advance plant phenotyping research by encouraging innovative solutions for tracking and predicting plant growth. The GitHub repository is publicly available at https://github.com/mriglab/GroMo-Plant-Growth-Modeling-with-Multiview-Images.
On the Reliability of Large Language Models to Misinformed and Demographically-Informed Prompts
Oct 06, 2024We investigate and observe the behaviour and performance of Large Language Model (LLM)-backed chatbots in addressing misinformed prompts and questions with demographic information within the domains of Climate Change and Mental Health. Through a combination of quantitative and qualitative methods, we assess the chatbots' ability to discern the veracity of statements, their adherence to facts, and the presence of bias or misinformation in their responses. Our quantitative analysis using True/False questions reveals that these chatbots can be relied on to give the right answers to these close-ended questions. However, the qualitative insights, gathered from domain experts, shows that there are still concerns regarding privacy, ethical implications, and the necessity for chatbots to direct users to professional services. We conclude that while these chatbots hold significant promise, their deployment in sensitive areas necessitates careful consideration, ethical oversight, and rigorous refinement to ensure they serve as a beneficial augmentation to human expertise rather than an autonomous solution.
OrientedFormer: An End-to-End Transformer-Based Oriented Object Detector in Remote Sensing Images
Sep 29, 2024Oriented object detection in remote sensing images is a challenging task due to objects being distributed in multi-orientation. Recently, end-to-end transformer-based methods have achieved success by eliminating the need for post-processing operators compared to traditional CNN-based methods. However, directly extending transformers to oriented object detection presents three main issues: 1) objects rotate arbitrarily, necessitating the encoding of angles along with position and size; 2) the geometric relations of oriented objects are lacking in self-attention, due to the absence of interaction between content and positional queries; and 3) oriented objects cause misalignment, mainly between values and positional queries in cross-attention, making accurate classification and localization difficult. In this paper, we propose an end-to-end transformer-based oriented object detector, consisting of three dedicated modules to address these issues. First, Gaussian positional encoding is proposed to encode the angle, position, and size of oriented boxes using Gaussian distributions. Second, Wasserstein self-attention is proposed to introduce geometric relations and facilitate interaction between content and positional queries by utilizing Gaussian Wasserstein distance scores. Third, oriented cross-attention is proposed to align values and positional queries by rotating sampling points around the positional query according to their angles. Experiments on six datasets DIOR-R, a series of DOTA, HRSC2016 and ICDAR2015 show the effectiveness of our approach. Compared with previous end-to-end detectors, the OrientedFormer gains 1.16 and 1.21 AP$_{50}$ on DIOR-R and DOTA-v1.0 respectively, while reducing training epochs from 3$\times$ to 1$\times$. The codes are available at https://github.com/wokaikaixinxin/OrientedFormer.
Characterizing Continual Learning Scenarios and Strategies for Audio Analysis
Jun 29, 2024



Audio analysis is useful in many application scenarios. The state-of-the-art audio analysis approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can encounter new classes in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we characterize continual learning (CL) approaches in audio analysis. In this paper, we characterize continual learning (CL) approaches, intended to tackle catastrophic forgetting arising due to drifts. As there is no CL dataset for audio analysis, we use DCASE 2020 to 2023 datasets to create various CL scenarios for audio-based monitoring tasks. We have investigated the following CL and non-CL approaches: EWC, LwF, SI, GEM, A-GEM, GDumb, Replay, Naive, cumulative, and joint training. The study is very beneficial for researchers and practitioners working in the area of audio analysis for developing adaptive models. We observed that Replay achieved better results than other methods in the DCASE challenge data. It achieved an accuracy of 70.12% for the domain incremental scenario and an accuracy of 96.98% for the class incremental scenario.
MADRL-Based Rate Adaptation for 360$\degree$ Video Streaming with Multi-Viewpoint Prediction
May 13, 2024Over the last few years, 360$\degree$ video traffic on the network has grown significantly. A key challenge of 360$\degree$ video playback is ensuring a high quality of experience (QoE) with limited network bandwidth. Currently, most studies focus on tile-based adaptive bitrate (ABR) streaming based on single viewport prediction to reduce bandwidth consumption. However, the performance of models for single-viewpoint prediction is severely limited by the inherent uncertainty in head movement, which can not cope with the sudden movement of users very well. This paper first presents a multimodal spatial-temporal attention transformer to generate multiple viewpoint trajectories with their probabilities given a historical trajectory. The proposed method models viewpoint prediction as a classification problem and uses attention mechanisms to capture the spatial and temporal characteristics of input video frames and viewpoint trajectories for multi-viewpoint prediction. After that, a multi-agent deep reinforcement learning (MADRL)-based ABR algorithm utilizing multi-viewpoint prediction for 360$\degree$ video streaming is proposed for maximizing different QoE objectives under various network conditions. We formulate the ABR problem as a decentralized partially observable Markov decision process (Dec-POMDP) problem and present a MAPPO algorithm based on centralized training and decentralized execution (CTDE) framework to solve the problem. The experimental results show that our proposed method improves the defined QoE metric by up to 85.5\% compared to existing ABR methods.
Efficient Test-Time Adaptation of Vision-Language Models
Mar 27, 2024
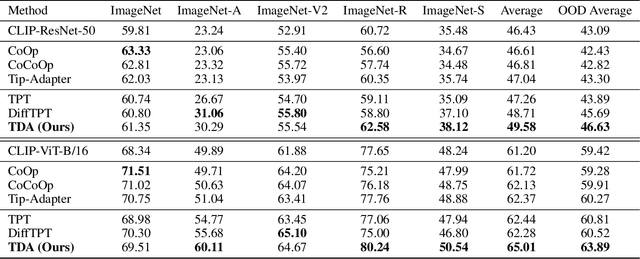
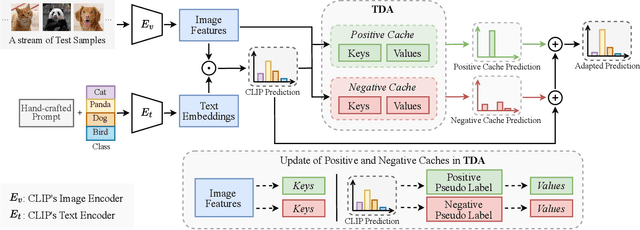

Test-time adaptation with pre-trained vision-language models has attracted increasing attention for tackling distribution shifts during the test time. Though prior studies have achieved very promising performance, they involve intensive computation which is severely unaligned with test-time adaptation. We design TDA, a training-free dynamic adapter that enables effective and efficient test-time adaptation with vision-language models. TDA works with a lightweight key-value cache that maintains a dynamic queue with few-shot pseudo labels as values and the corresponding test-sample features as keys. Leveraging the key-value cache, TDA allows adapting to test data gradually via progressive pseudo label refinement which is super-efficient without incurring any backpropagation. In addition, we introduce negative pseudo labeling that alleviates the adverse impact of pseudo label noises by assigning pseudo labels to certain negative classes when the model is uncertain about its pseudo label predictions. Extensive experiments over two benchmarks demonstrate TDA's superior effectiveness and efficiency as compared with the state-of-the-art. The code has been released in \url{https://kdiaaa.github.io/tda/}.
Bringing Robots Home: The Rise of AI Robots in Consumer Electronics
Mar 21, 2024On March 18, 2024, NVIDIA unveiled Project GR00T, a general-purpose multimodal generative AI model designed specifically for training humanoid robots. Preceding this event, Tesla's unveiling of the Optimus Gen 2 humanoid robot on December 12, 2023, underscored the profound impact robotics is poised to have on reshaping various facets of our daily lives. While robots have long dominated industrial settings, their presence within our homes is a burgeoning phenomenon. This can be attributed, in part, to the complexities of domestic environments and the challenges of creating robots that can seamlessly integrate into our daily routines.