 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Watermark Stealing Attacks in Generative Models via Multi-Key Watermarking
Jul 10, 2025Watermarking offers a promising solution for GenAI providers to establish the provenance of their generated content. A watermark is a hidden signal embedded in the generated content, whose presence can later be verified using a secret watermarking key. A threat to GenAI providers are \emph{watermark stealing} attacks, where users forge a watermark into content that was \emph{not} generated by the provider's models without access to the secret key, e.g., to falsely accuse the provider. Stealing attacks collect \emph{harmless} watermarked samples from the provider's model and aim to maximize the expected success rate of generating \emph{harmful} watermarked samples. Our work focuses on mitigating stealing attacks while treating the underlying watermark as a black-box. Our contributions are: (i) Proposing a multi-key extension to mitigate stealing attacks that can be applied post-hoc to any watermarking method across any modality. (ii) We provide theoretical guarantees and demonstrate empirically that our method makes forging substantially less effective across multiple datasets, and (iii) we formally define the threat of watermark forging as the task of generating harmful, watermarked content and model this threat via security games.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
On the Reliability of Large Language Models to Misinformed and Demographically-Informed Prompts
Oct 06, 2024We investigate and observe the behaviour and performance of Large Language Model (LLM)-backed chatbots in addressing misinformed prompts and questions with demographic information within the domains of Climate Change and Mental Health. Through a combination of quantitative and qualitative methods, we assess the chatbots' ability to discern the veracity of statements, their adherence to facts, and the presence of bias or misinformation in their responses. Our quantitative analysis using True/False questions reveals that these chatbots can be relied on to give the right answers to these close-ended questions. However, the qualitative insights, gathered from domain experts, shows that there are still concerns regarding privacy, ethical implications, and the necessity for chatbots to direct users to professional services. We conclude that while these chatbots hold significant promise, their deployment in sensitive areas necessitates careful consideration, ethical oversight, and rigorous refinement to ensure they serve as a beneficial augmentation to human expertise rather than an autonomous solution.
Optimizing Adaptive Attacks against Content Watermarks for Language Models
Oct 03, 2024

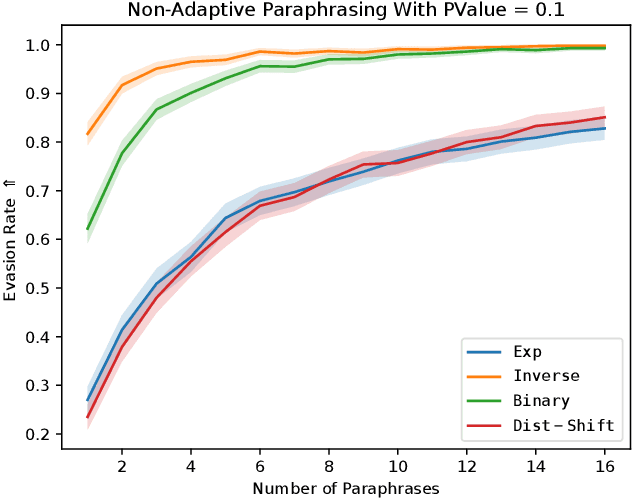

Large Language Models (LLMs) can be \emph{misused} to spread online spam and misinformation. Content watermarking deters misuse by hiding a message in model-generated outputs, enabling their detection using a secret watermarking key. Robustness is a core security property, stating that evading detection requires (significant) degradation of the content's quality. Many LLM watermarking methods have been proposed, but robustness is tested only against \emph{non-adaptive} attackers who lack knowledge of the watermarking method and can find only suboptimal attacks. We formulate the robustness of LLM watermarking as an objective function and propose preference-based optimization to tune \emph{adaptive} attacks against the specific watermarking method. Our evaluation shows that (i) adaptive attacks substantially outperform non-adaptive baselines. (ii) Even in a non-adaptive setting, adaptive attacks optimized against a few known watermarks remain highly effective when tested against other unseen watermarks, and (iii) optimization-based attacks are practical and require less than seven GPU hours. Our findings underscore the need to test robustness against adaptive attackers.
MirrorCheck: Efficient Adversarial Defense for Vision-Language Models
Jun 13, 2024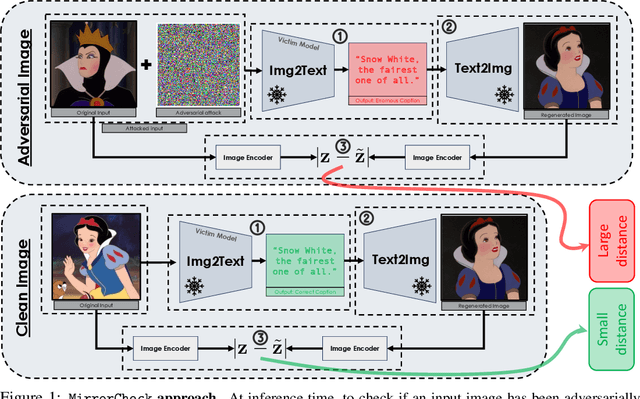



Vision-Language Models (VLMs) are becoming increasingly vulnerable to adversarial attacks as various novel attack strategies are being proposed against these models. While existing defenses excel in unimodal contexts, they currently fall short in safeguarding VLMs against adversarial threats. To mitigate this vulnerability, we propose a novel, yet elegantly simple approach for detecting adversarial samples in VLMs. Our method leverages Text-to-Image (T2I) models to generate images based on captions produced by target VLMs. Subsequently, we calculate the similarities of the embeddings of both input and generated images in the feature space to identify adversarial samples. Empirical evaluations conducted on different datasets validate the efficacy of our approach, outperforming baseline methods adapted from image classification domains. Furthermore, we extend our methodology to classification tasks, showcasing its adaptability and model-agnostic nature. Theoretical analyses and empirical findings also show the resilience of our approach against adaptive attacks, positioning it as an excellent defense mechanism for real-world deployment against adversarial threats.
Redefining Contributions: Shapley-Driven Federated Learning
Jun 01, 2024Federated learning (FL) has emerged as a pivotal approach in machine learning, enabling multiple participants to collaboratively train a global model without sharing raw data. While FL finds applications in various domains such as healthcare and finance, it is challenging to ensure global model convergence when participants do not contribute equally and/or honestly. To overcome this challenge, principled mechanisms are required to evaluate the contributions made by individual participants in the FL setting. Existing solutions for contribution assessment rely on general accuracy evaluation, often failing to capture nuanced dynamics and class-specific influences. This paper proposes a novel contribution assessment method called ShapFed for fine-grained evaluation of participant contributions in FL. Our approach uses Shapley values from cooperative game theory to provide a granular understanding of class-specific influences. Based on ShapFed, we introduce a weighted aggregation method called ShapFed-WA, which outperforms conventional federated averaging, especially in class-imbalanced scenarios. Personalizing participant updates based on their contributions further enhances collaborative fairness by delivering differentiated models commensurate with the participant contributions. Experiments on CIFAR-10, Chest X-Ray, and Fed-ISIC2019 datasets demonstrate the effectiveness of our approach in improving utility, efficiency, and fairness in FL systems. The code can be found at https://github.com/tnurbek/shapfed.
Regularized PolyKervNets: Optimizing Expressiveness and Efficiency for Private Inference in Deep Neural Networks
Dec 23, 2023



Private computation of nonlinear functions, such as Rectified Linear Units (ReLUs) and max-pooling operations, in deep neural networks (DNNs) poses significant challenges in terms of storage, bandwidth, and time consumption. To address these challenges, there has been a growing interest in utilizing privacy-preserving techniques that leverage polynomial activation functions and kernelized convolutions as alternatives to traditional ReLUs. However, these alternative approaches often suffer from a trade-off between achieving faster private inference (PI) and sacrificing model accuracy. In particular, when applied to much deeper networks, these methods encounter training instabilities, leading to issues like exploding gradients (resulting in NaNs) or suboptimal approximations. In this study, we focus on PolyKervNets, a technique known for offering improved dynamic approximations in smaller networks but still facing instabilities in larger and more complex networks. Our primary objective is to empirically explore optimization-based training recipes to enhance the performance of PolyKervNets in larger networks. By doing so, we aim to potentially eliminate the need for traditional nonlinear activation functions, thereby advancing the state-of-the-art in privacy-preserving deep neural network architectures. Code can be found on GitHub at: \url{https://github.com/tolusophy/PolyKervNets/}
Towards Smart City Security: Violence and Weaponized Violence Detection using DCNN
Jul 26, 2022
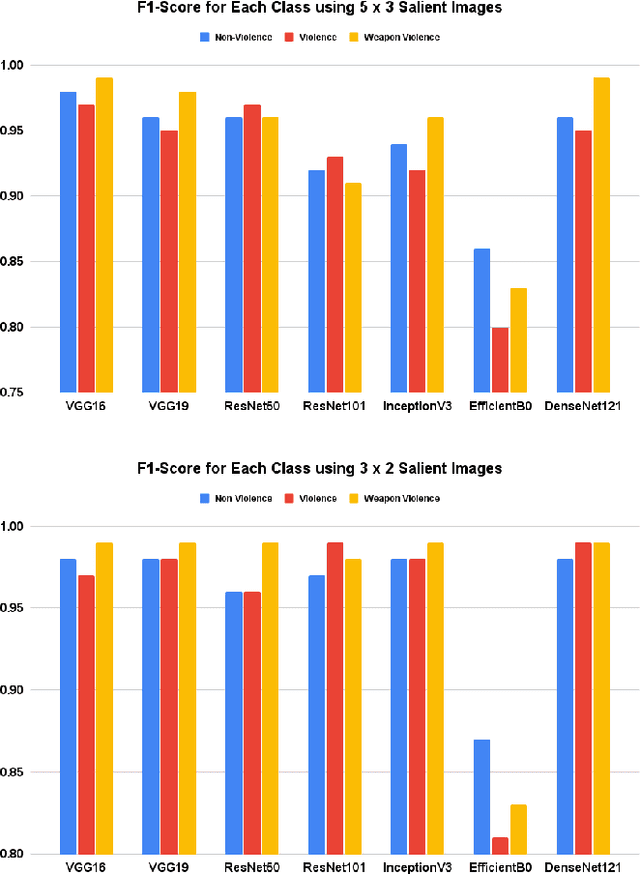


In this ever connected society, CCTVs have had a pivotal role in enforcing safety and security of the citizens by recording unlawful activities for the authorities to take actions. In a smart city context, using Deep Convolutional Neural Networks (DCNN) to detection violence and weaponized violence from CCTV videos will provide an additional layer of security by ensuring real-time detection around the clock. In this work, we introduced a new specialised dataset by gathering real CCTV footage of both weaponized and non-weaponized violence as well as non-violence videos from YouTube. We also proposed a novel approach in merging consecutive video frames into a single salient image which will then be the input to the DCNN. Results from multiple DCNN architectures have proven the effectiveness of our method by having the highest accuracy of 99\%. We also take into consideration the efficiency of our methods through several parameter trade-offs to ensure smart city sustainability.