 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWuNeng: Hybrid State with Attention
Apr 27, 2025The WuNeng architecture introduces a novel approach to enhancing the expressivity and power of large language models by integrating recurrent neural network (RNN)-based RWKV-7 with advanced attention mechanisms, prioritizing heightened contextual coherence over reducing KV cache size. Building upon the hybrid-head concept from Hymba, WuNeng augments standard multi-head attention with additional RWKV-7 state-driven heads, rather than replacing existing heads, to enrich the model's representational capacity. A cross-head interaction technique fosters dynamic synergy among standard, state-driven, and newly introduced middle heads, leveraging concatenation, additive modulation, and gated fusion for robust information integration. Furthermore, a multi-token state processing mechanism harnesses the continuous RWKV-7 state to capture intricate, sequence-wide dependencies, significantly boosting expressivity. Remarkably, these enhancements are achieved with minimal additional parameters, ensuring efficiency while empowering the model to excel in complex reasoning and sequence generation tasks. WuNeng sets a new standard for balancing expressivity and computational efficiency in modern neural architectures.
Cross-attention for State-based model RWKV-7
Apr 19, 2025We introduce CrossWKV, a novel cross-attention mechanism for the state-based RWKV-7 model, designed to enhance the expressive power of text-to-image generation. Leveraging RWKV-7's linear-complexity Weighted Key-Value (WKV) architecture, CrossWKV integrates text and image modalities in a single pass, utilizing a generalized delta rule with vector-valued gating and low-rank adaptations (LoRA) to achieve superior cross-modal alignment. Unlike Transformer-based models, CrossWKV's non-diagonal, input-dependent transition matrix enables it to represent complex functions beyond the $\mathrm{TC}^0$ complexity class, including all regular languages, as demonstrated by its ability to perform state-tracking tasks like $S_5$ permutation modeling. Evaluated within the Diffusion in RWKV-7 (DIR-7) on datasets such as LAION-5B and ImageNet, CrossWKV achieves a Frechet Inception Distance (FID) of 2.88 and a CLIP score of 0.33 on ImageNet 256x256, matching state-of-the-art performance while offering robust generalization across diverse prompts. The model's enhanced expressivity, combined with constant memory usage and linear scaling, positions it as a powerful solution for advanced cross-modal tasks, with potential applications in high-resolution generation and dynamic state manipulation.Code at https://github.com/TorchRWKV/flash-linear-attention
Millions of States: Designing a Scalable MoE Architecture with RWKV-7 Meta-learner
Apr 11, 2025State-based sequence models like RWKV-7 offer a compelling alternative to Transformer architectures, achieving linear complexity while demonstrating greater expressive power in short-context scenarios and enabling state tracking beyond the \(\text{TC}^0\) complexity class. However, RWKV-7 lacks mechanisms for token-parameter interactions and native scalability, limiting its adaptability and growth without retraining. In this paper, we propose \textbf{Meta-State}, a novel extension to RWKV-7 that replaces attention mechanisms with a fully state-driven approach, integrating token-parameter interactions through a \textbf{Self-State Encoder} (SSE) mechanism. The SSE repurposes a portion of the RWKV-7 Weighted Key-Value (WKV) state as transformation weights to encode token-parameter interactions in a linear, state-driven manner without introducing new trainable matrices or softmax operations, while preserving the autoregressive property of token processing. Meta-State supports progressive model scaling by expanding the WKV state and parameter tokens, reusing existing parameters without retraining. Our approach bridges the gap between state-based modeling, token-parameter interactions, and scalable architectures, offering a flexible framework for efficient and adaptable sequence modeling with linear complexity and constant memory usage.
State Tuning: State-based Test-Time Scaling on RWKV-7
Apr 07, 2025Test-time scaling has emerged as a prominent research direction in machine learning, enabling models to enhance their expressive capabilities during inference.Transformers, renowned for striking a delicate balance between efficiency and expressiveness, have benefited from test-time scaling techniques that leverage an expanding key-value (KV) cache to significantly improve performance.In this paper, we introduce a novel state-based approach to test-time scaling, which we term state tuning, tailored to the RNN-based RWKV-7 model.By exploiting the unique strengths of RWKV-7, our method achieves state-of-the-art performance on the target task without altering the model's pre-trained weights. Our approach centers on three key innovations. First, we develop an observer framework that allows a smaller model to replicate and learn the state dynamics of the RWKV-7 model. Second, we employ a kernel method to dynamically upscale the state size, enhancing the model's capacity to capture intricate patterns. Third, we integrate Decorrelated Backpropagation (DBP) to optimize the upscaled state matrix, thereby improving convergence and expressivity. By tuning only the state matrix, we demonstrate that a smaller model can outperform larger models on the given task. This method preserves the efficiency of the original RWKV-7 architecture while harnessing the power of test-time scaling to deliver superior results. Our findings underscore the potential of state tuning as an effective strategy for advancing model performance in resource-constrained settings. Our code is https://github.com/TorchRWKV/flash-linear-attention.
ARWKV: Pretrain is not what we need, an RNN-Attention-Based Language Model Born from Transformer
Jan 26, 2025As is known, hybrid quadratic and subquadratic attention models in multi-head architectures have surpassed both Transformer and Linear RNN models , with these works primarily focusing on reducing KV complexity and improving efficiency. For further research on expressiveness, we introduce our series of models distilled from Qwen 2.5, based on pure native RWKV-7 attention, which aims to make RNN more expressive and demonstrates state tracking ability beyond transformers. We work with QRWK 32B based on RWKV-6 architecture, another approach that reduces the entire knowledge processing time to just 8 hours using 16 AMD MI300X GPUs while maintaining Qwen 2.5's performance. In fact, the distillation process can utilize any LLM, not just Qwen, and enables knowledge transfer from larger LLMs to smaller ones with more fewer tokens. We will explain the detailed process and share our insights on building more powerful foundation models. Please note that this is an ongoing work that will be updated continuously. The model checkpoints and source code are available at \href{https://github.com/yynil/RWKVInside}{https://github.com/yynil/RWKVInside}, \href{https://huggingface.co/RWKV-Red-Team/ARWKV-7B-Preview-0.1}{https://huggingface.co/RWKV-Red-Team/ARWKV-7B-Preview-0.1}.
Towards Smart City Security: Violence and Weaponized Violence Detection using DCNN
Jul 26, 2022
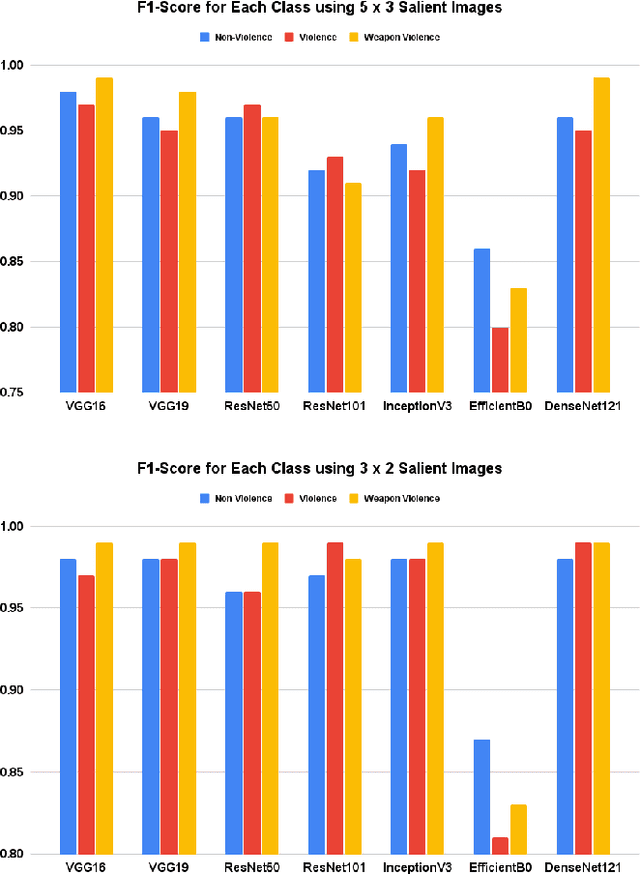


In this ever connected society, CCTVs have had a pivotal role in enforcing safety and security of the citizens by recording unlawful activities for the authorities to take actions. In a smart city context, using Deep Convolutional Neural Networks (DCNN) to detection violence and weaponized violence from CCTV videos will provide an additional layer of security by ensuring real-time detection around the clock. In this work, we introduced a new specialised dataset by gathering real CCTV footage of both weaponized and non-weaponized violence as well as non-violence videos from YouTube. We also proposed a novel approach in merging consecutive video frames into a single salient image which will then be the input to the DCNN. Results from multiple DCNN architectures have proven the effectiveness of our method by having the highest accuracy of 99\%. We also take into consideration the efficiency of our methods through several parameter trade-offs to ensure smart city sustainability.