 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Adaptive Attacks against Content Watermarks for Language Models
Oct 03, 2024


Large Language Models (LLMs) can be \emph{misused} to spread online spam and misinformation. Content watermarking deters misuse by hiding a message in model-generated outputs, enabling their detection using a secret watermarking key. Robustness is a core security property, stating that evading detection requires (significant) degradation of the content's quality. Many LLM watermarking methods have been proposed, but robustness is tested only against \emph{non-adaptive} attackers who lack knowledge of the watermarking method and can find only suboptimal attacks. We formulate the robustness of LLM watermarking as an objective function and propose preference-based optimization to tune \emph{adaptive} attacks against the specific watermarking method. Our evaluation shows that (i) adaptive attacks substantially outperform non-adaptive baselines. (ii) Even in a non-adaptive setting, adaptive attacks optimized against a few known watermarks remain highly effective when tested against other unseen watermarks, and (iii) optimization-based attacks are practical and require less than seven GPU hours. Our findings underscore the need to test robustness against adaptive attackers.
FastLloyd: Federated, Accurate, Secure, and Tunable $k$-Means Clustering with Differential Privacy
May 03, 2024



We study the problem of privacy-preserving $k$-means clustering in the horizontally federated setting. Existing federated approaches using secure computation, suffer from substantial overheads and do not offer output privacy. At the same time, differentially private (DP) $k$-means algorithms assume a trusted central curator and do not extend to federated settings. Naively combining the secure and DP solutions results in a protocol with impractical overhead. Instead, our work provides enhancements to both the DP and secure computation components, resulting in a design that is faster, more private, and more accurate than previous work. By utilizing the computational DP model, we design a lightweight, secure aggregation-based approach that achieves four orders of magnitude speed-up over state-of-the-art related work. Furthermore, we not only maintain the utility of the state-of-the-art in the central model of DP, but we improve the utility further by taking advantage of constrained clustering techniques.
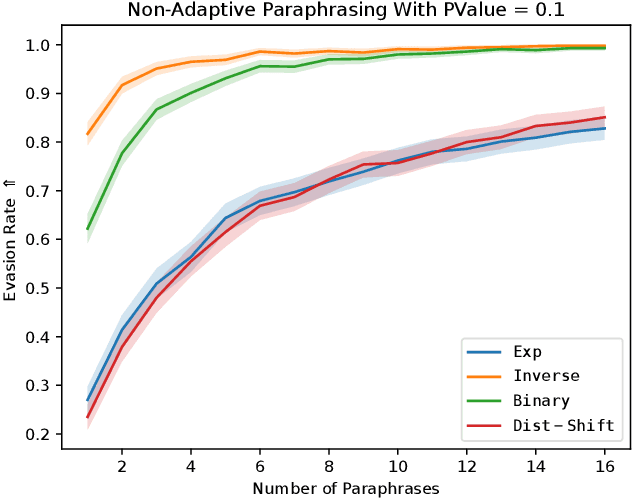
Leveraging Optimization for Adaptive Attacks on Image Watermarks
Sep 29, 2023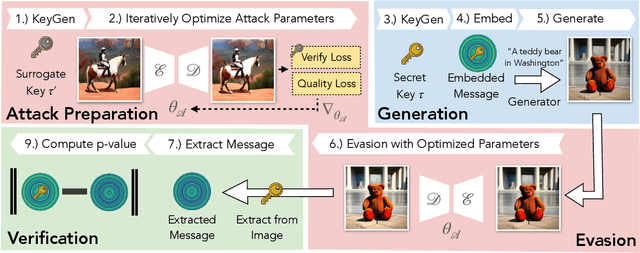
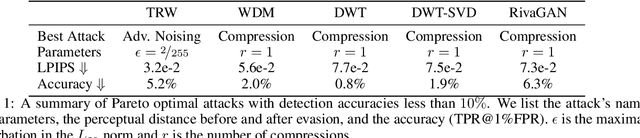
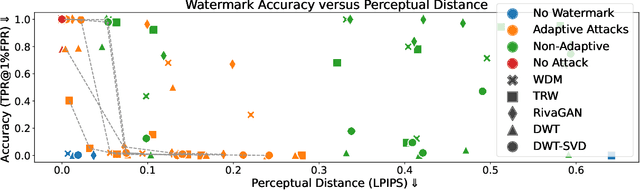
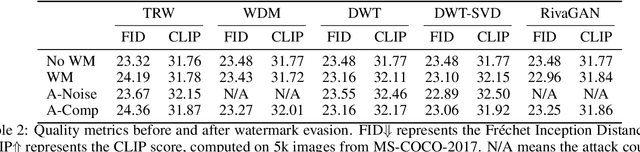
Untrustworthy users can misuse image generators to synthesize high-quality deepfakes and engage in online spam or disinformation campaigns. Watermarking deters misuse by marking generated content with a hidden message, enabling its detection using a secret watermarking key. A core security property of watermarking is robustness, which states that an attacker can only evade detection by substantially degrading image quality. Assessing robustness requires designing an adaptive attack for the specific watermarking algorithm. A challenge when evaluating watermarking algorithms and their (adaptive) attacks is to determine whether an adaptive attack is optimal, i.e., it is the best possible attack. We solve this problem by defining an objective function and then approach adaptive attacks as an optimization problem. The core idea of our adaptive attacks is to replicate secret watermarking keys locally by creating surrogate keys that are differentiable and can be used to optimize the attack's parameters. We demonstrate for Stable Diffusion models that such an attacker can break all five surveyed watermarking methods at negligible degradation in image quality. These findings emphasize the need for more rigorous robustness testing against adaptive, learnable attackers.
Fast and Private Inference of Deep Neural Networks by Co-designing Activation Functions
Jun 14, 2023



Machine Learning as a Service (MLaaS) is an increasingly popular design where a company with abundant computing resources trains a deep neural network and offers query access for tasks like image classification. The challenge with this design is that MLaaS requires the client to reveal their potentially sensitive queries to the company hosting the model. Multi-party computation (MPC) protects the client's data by allowing encrypted inferences. However, current approaches suffer prohibitively large inference times. The inference time bottleneck in MPC is the evaluation of non-linear layers such as ReLU activation functions. Motivated by the success of previous work co-designing machine learning and MPC aspects, we develop an activation function co-design. We replace all ReLUs with a polynomial approximation and evaluate them with single-round MPC protocols, which give state-of-the-art inference times in wide-area networks. Furthermore, to address the accuracy issues previously encountered with polynomial activations, we propose a novel training algorithm that gives accuracy competitive with plaintext models. Our evaluation shows between $4$ and $90\times$ speedups in inference time on large models with up to $23$ million parameters while maintaining competitive inference accuracy.