 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastLloyd: Federated, Accurate, Secure, and Tunable $k$-Means Clustering with Differential Privacy
May 03, 2024



We study the problem of privacy-preserving $k$-means clustering in the horizontally federated setting. Existing federated approaches using secure computation, suffer from substantial overheads and do not offer output privacy. At the same time, differentially private (DP) $k$-means algorithms assume a trusted central curator and do not extend to federated settings. Naively combining the secure and DP solutions results in a protocol with impractical overhead. Instead, our work provides enhancements to both the DP and secure computation components, resulting in a design that is faster, more private, and more accurate than previous work. By utilizing the computational DP model, we design a lightweight, secure aggregation-based approach that achieves four orders of magnitude speed-up over state-of-the-art related work. Furthermore, we not only maintain the utility of the state-of-the-art in the central model of DP, but we improve the utility further by taking advantage of constrained clustering techniques.
Fast and Private Inference of Deep Neural Networks by Co-designing Activation Functions
Jun 14, 2023



Machine Learning as a Service (MLaaS) is an increasingly popular design where a company with abundant computing resources trains a deep neural network and offers query access for tasks like image classification. The challenge with this design is that MLaaS requires the client to reveal their potentially sensitive queries to the company hosting the model. Multi-party computation (MPC) protects the client's data by allowing encrypted inferences. However, current approaches suffer prohibitively large inference times. The inference time bottleneck in MPC is the evaluation of non-linear layers such as ReLU activation functions. Motivated by the success of previous work co-designing machine learning and MPC aspects, we develop an activation function co-design. We replace all ReLUs with a polynomial approximation and evaluate them with single-round MPC protocols, which give state-of-the-art inference times in wide-area networks. Furthermore, to address the accuracy issues previously encountered with polynomial activations, we propose a novel training algorithm that gives accuracy competitive with plaintext models. Our evaluation shows between $4$ and $90\times$ speedups in inference time on large models with up to $23$ million parameters while maintaining competitive inference accuracy.
Self-Attention Generative Adversarial Network for Iterative Reconstruction of CT Images
Dec 23, 2021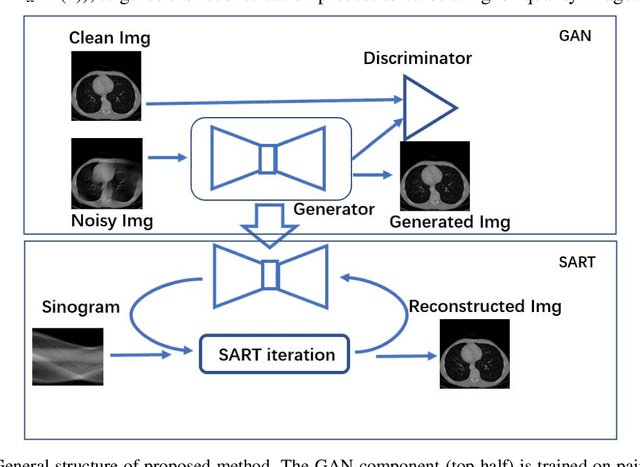
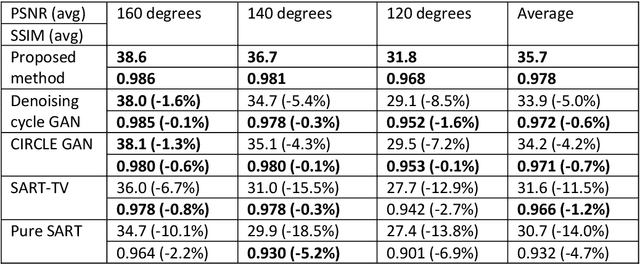
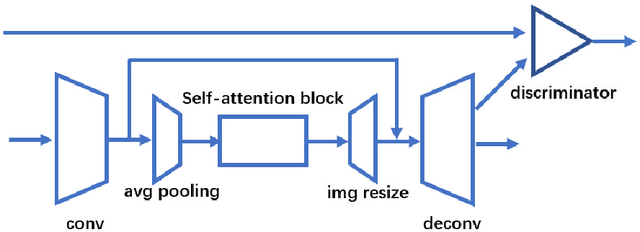
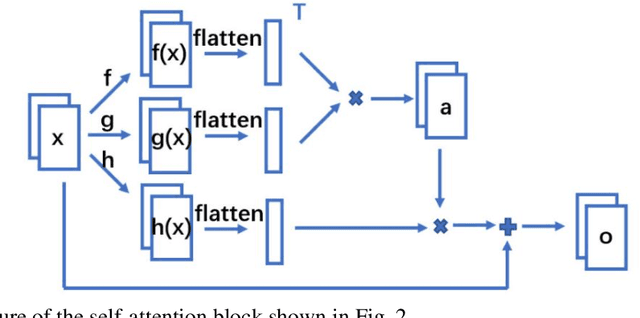
Computed tomography (CT) uses X-ray measurements taken from sensors around the body to generate tomographic images of the human body. Conventional reconstruction algorithms can be used if the X-ray data are adequately sampled and of high quality; however, concerns such as reducing dose to the patient, or geometric limitations on data acquisition, may result in low quality or incomplete data. Images reconstructed from these data using conventional methods are of poor quality, due to noise and other artifacts. The aim of this study is to train a single neural network to reconstruct high-quality CT images from noisy or incomplete CT scan data, including low-dose, sparse-view, and limited-angle scenarios. To accomplish this task, we train a generative adversarial network (GAN) as a signal prior, to be used in conjunction with the iterative simultaneous algebraic reconstruction technique (SART) for CT data. The network includes a self-attention block to model long-range dependencies in the data. We compare our Self-Attention GAN for CT image reconstruction with several state-of-the-art approaches, including denoising cycle GAN, CIRCLE GAN, and a total variation superiorized algorithm. Our approach is shown to have comparable overall performance to CIRCLE GAN, while outperforming the other two approaches.
Differentially Private Learning Does Not Bound Membership Inference
Oct 23, 2020
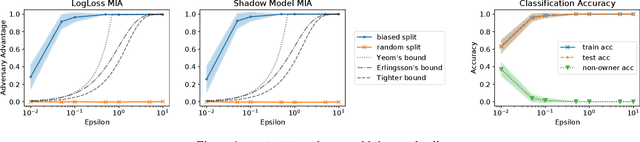
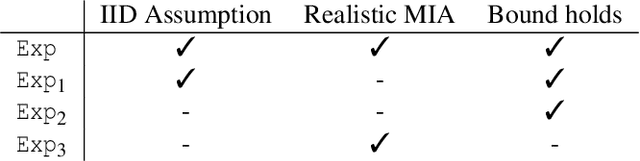
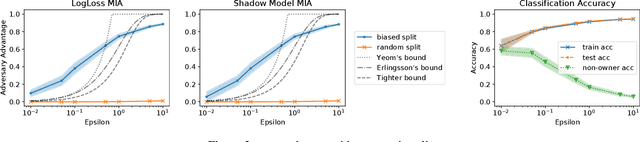
Training machine learning models on privacy-sensitive data has become a popular practice, driving innovation in ever-expanding fields. This has opened the door to a series of new attacks, such as Membership Inference Attacks (MIAs), that exploit vulnerabilities in ML models in order to expose the privacy of individual training samples. A growing body of literature holds up Differential Privacy (DP) as an effective defense against such attacks, and companies like Google and Amazon include this privacy notion in their machine-learning-as-a-service products. However, little scrutiny has been given to how underlying correlations within the datasets used for training these models can impact the privacy guarantees provided by DP. In this work, we challenge prior findings that suggest DP provides a strong defense against MIAs. We provide theoretical and experimental evidence for cases where the theoretical bounds of DP are violated by MIAs using the same attacks described in prior work. We show this hypothetically with artificial, pathological datasets as well as with real-world datasets carefully split to create a distinction between member and non-member samples. Our findings suggest that certain properties of datasets, such as bias or data correlation, play a critical role in determining the effectiveness of DP as a privacy preserving mechanism against MIAs. Further, ensuring that a given dataset is resilient against these MIAs may be virtually impossible for a data analyst to determine.