 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Learning Does Not Bound Membership Inference
Paper and Code

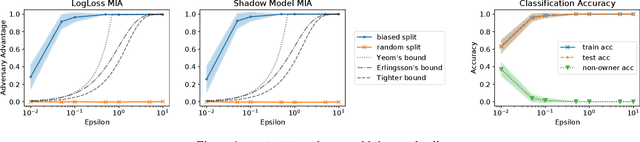
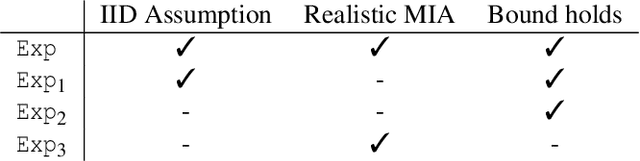
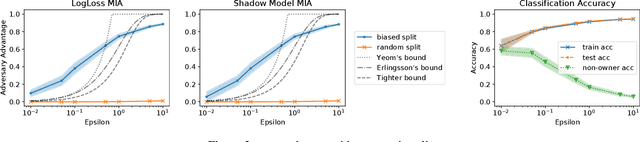
Training machine learning models on privacy-sensitive data has become a popular practice, driving innovation in ever-expanding fields. This has opened the door to a series of new attacks, such as Membership Inference Attacks (MIAs), that exploit vulnerabilities in ML models in order to expose the privacy of individual training samples. A growing body of literature holds up Differential Privacy (DP) as an effective defense against such attacks, and companies like Google and Amazon include this privacy notion in their machine-learning-as-a-service products. However, little scrutiny has been given to how underlying correlations within the datasets used for training these models can impact the privacy guarantees provided by DP. In this work, we challenge prior findings that suggest DP provides a strong defense against MIAs. We provide theoretical and experimental evidence for cases where the theoretical bounds of DP are violated by MIAs using the same attacks described in prior work. We show this hypothetically with artificial, pathological datasets as well as with real-world datasets carefully split to create a distinction between member and non-member samples. Our findings suggest that certain properties of datasets, such as bias or data correlation, play a critical role in determining the effectiveness of DP as a privacy preserving mechanism against MIAs. Further, ensuring that a given dataset is resilient against these MIAs may be virtually impossible for a data analyst to determine.