 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoSE: Mixture of Slimmable Experts for Efficient and Adaptive Language Models
Feb 05, 2026Mixture-of-Experts (MoE) models scale large language models efficiently by sparsely activating experts, but once an expert is selected, it is executed fully. Hence, the trade-off between accuracy and computation in an MoE model typically exhibits large discontinuities. We propose Mixture of Slimmable Experts (MoSE), an MoE architecture in which each expert has a nested, slimmable structure that can be executed at variable widths. This enables conditional computation not only over which experts are activated, but also over how much of each expert is utilized. Consequently, a single pretrained MoSE model can support a more continuous spectrum of accuracy-compute trade-offs at inference time. We present a simple and stable training recipe for slimmable experts under sparse routing, combining multi-width training with standard MoE objectives. During inference, we explore strategies for runtime width determination, including a lightweight test-time training mechanism that learns how to map router confidence/probabilities to expert widths under a fixed budget. Experiments on GPT models trained on OpenWebText demonstrate that MoSE matches or improves upon standard MoE at full width and consistently shifts the Pareto frontier for accuracy vs. cost, achieving comparable performance with significantly fewer FLOPs.
Stochastic Self-Organization in Multi-Agent Systems
Oct 01, 2025Multi-agent systems (MAS) based on Large Language Models (LLMs) have the potential to solve tasks that are beyond the reach of any single LLM. However, this potential can only be realized when the collaboration mechanism between agents is optimized. Specifically, optimizing the communication structure between agents is critical for fruitful collaboration. Most existing approaches rely on fixed topologies, pretrained graph generators, optimization over edges, or employ external LLM judges, thereby adding to the complexity. In this work, we introduce a response-conditioned framework that adapts communication on-the-fly. Agents independently generate responses to the user query and assess peer contributions using an approximation of the Shapley value. A directed acyclic graph (DAG) is then constructed to regulate the propagation of the responses among agents, which ensures stable and efficient message transmission from high-contributing agents to others. This graph is dynamically updated based on the agent responses from the previous collaboration round. Since the proposed framework enables the self-organization of agents without additional supervision or training, we refer to it as SelfOrg. The SelfOrg framework goes beyond task- and query-level optimization and takes into account the stochastic nature of agent responses. Experiments with both strong and weak LLM backends demonstrate robust performance, with significant gains in the weak regime where prior methods collapse. We also theoretically show that multiple agents increase the chance of correctness and that the correct responses naturally dominate the information flow.
LoFT: Low-Rank Adaptation That Behaves Like Full Fine-Tuning
May 27, 2025Large pre-trained models are commonly adapted to downstream tasks using parameter-efficient fine-tuning methods such as Low-Rank Adaptation (LoRA), which injects small trainable low-rank matrices instead of updating all weights. While LoRA dramatically reduces trainable parameters with little overhead, it can still underperform full fine-tuning in accuracy and often converges more slowly. We introduce LoFT, a novel low-rank adaptation method that behaves like full fine-tuning by aligning the optimizer's internal dynamics with those of updating all model weights. LoFT not only learns weight updates in a low-rank subspace (like LoRA) but also properly projects the optimizer's first and second moments (Adam's momentum and variance) into the same subspace, mirroring full-model updates. By aligning the low-rank update itself with the full update, LoFT eliminates the need for tuning extra hyperparameters, e.g., LoRA scaling factor $\alpha$. Empirically, this approach substantially narrows the performance gap between adapter-based tuning and full fine-tuning and consistently outperforms standard LoRA-style methods, all without increasing inference cost.
Double Momentum and Error Feedback for Clipping with Fast Rates and Differential Privacy
Feb 17, 2025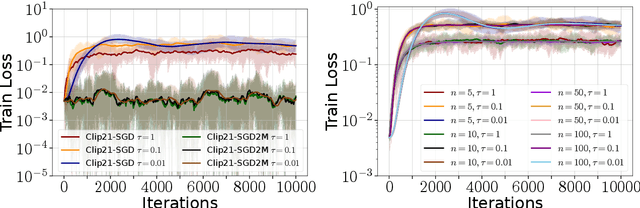
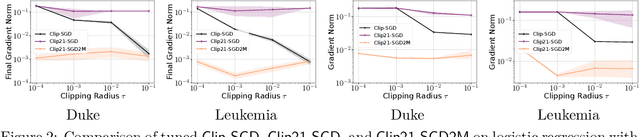


Strong Differential Privacy (DP) and Optimization guarantees are two desirable properties for a method in Federated Learning (FL). However, existing algorithms do not achieve both properties at once: they either have optimal DP guarantees but rely on restrictive assumptions such as bounded gradients/bounded data heterogeneity, or they ensure strong optimization performance but lack DP guarantees. To address this gap in the literature, we propose and analyze a new method called Clip21-SGD2M based on a novel combination of clipping, heavy-ball momentum, and Error Feedback. In particular, for non-convex smooth distributed problems with clients having arbitrarily heterogeneous data, we prove that Clip21-SGD2M has optimal convergence rate and also near optimal (local-)DP neighborhood. Our numerical experiments on non-convex logistic regression and training of neural networks highlight the superiority of Clip21-SGD2M over baselines in terms of the optimization performance for a given DP-budget.
Aequa: Fair Model Rewards in Collaborative Learning via Slimmable Networks
Feb 07, 2025



Collaborative learning enables multiple participants to learn a single global model by exchanging focused updates instead of sharing data. One of the core challenges in collaborative learning is ensuring that participants are rewarded fairly for their contributions, which entails two key sub-problems: contribution assessment and reward allocation. This work focuses on fair reward allocation, where the participants are incentivized through model rewards - differentiated final models whose performance is commensurate with the contribution. In this work, we leverage the concept of slimmable neural networks to collaboratively learn a shared global model whose performance degrades gracefully with a reduction in model width. We also propose a post-training fair allocation algorithm that determines the model width for each participant based on their contributions. We theoretically study the convergence of our proposed approach and empirically validate it using extensive experiments on different datasets and architectures. We also extend our approach to enable training-time model reward allocation.
CYCle: Choosing Your Collaborators Wisely to Enhance Collaborative Fairness in Decentralized Learning
Jan 21, 2025



Collaborative learning (CL) enables multiple participants to jointly train machine learning (ML) models on decentralized data sources without raw data sharing. While the primary goal of CL is to maximize the expected accuracy gain for each participant, it is also important to ensure that the gains are fairly distributed. Specifically, no client should be negatively impacted by the collaboration, and the individual gains must ideally be commensurate with the contributions. Most existing CL algorithms require central coordination and focus on the gain maximization objective while ignoring collaborative fairness. In this work, we first show that the existing measure of collaborative fairness based on the correlation between accuracy values without and with collaboration has drawbacks because it does not account for negative collaboration gain. We argue that maximizing mean collaboration gain (MCG) while simultaneously minimizing the collaboration gain spread (CGS) is a fairer alternative. Next, we propose the CYCle protocol that enables individual participants in a private decentralized learning (PDL) framework to achieve this objective through a novel reputation scoring method based on gradient alignment between the local cross-entropy and distillation losses. Experiments on the CIFAR-10, CIFAR-100, and Fed-ISIC2019 datasets empirically demonstrate the effectiveness of the CYCle protocol to ensure positive and fair collaboration gain for all participants, even in cases where the data distributions of participants are highly skewed. For the simple mean estimation problem with two participants, we also theoretically show that CYCle performs better than standard FedAvg, especially when there is large statistical heterogeneity.
Initialization using Update Approximation is a Silver Bullet for Extremely Efficient Low-Rank Fine-Tuning
Nov 29, 2024



Low-rank adapters have become a standard approach for efficiently fine-tuning large language models (LLMs), but they often fall short of achieving the performance of full fine-tuning. We propose a method, LoRA Silver Bullet or LoRA-SB, that approximates full fine-tuning within low-rank subspaces using a carefully designed initialization strategy. We theoretically demonstrate that the architecture of LoRA-XS, which inserts a trainable (r x r) matrix between B and A while keeping other matrices fixed, provides the precise conditions needed for this approximation. We leverage its constrained update space to achieve optimal scaling for high-rank gradient updates while removing the need for hyperparameter tuning. We prove that our initialization offers an optimal low-rank approximation of the initial gradient and preserves update directions throughout training. Extensive experiments across mathematical reasoning, commonsense reasoning, and language understanding tasks demonstrate that our approach exceeds the performance of standard LoRA while using 27-90x fewer parameters, and comprehensively outperforms LoRA-XS. Our findings establish that it is possible to simulate full fine-tuning in low-rank subspaces, and achieve significant efficiency gains without sacrificing performance. Our code is publicly available at https://github.com/RaghavSinghal10/lora-sb.
FedPeWS: Personalized Warmup via Subnetworks for Enhanced Heterogeneous Federated Learning
Oct 03, 2024Statistical data heterogeneity is a significant barrier to convergence in federated learning (FL). While prior work has advanced heterogeneous FL through better optimization objectives, these methods fall short when there is extreme data heterogeneity among collaborating participants. We hypothesize that convergence under extreme data heterogeneity is primarily hindered due to the aggregation of conflicting updates from the participants in the initial collaboration rounds. To overcome this problem, we propose a warmup phase where each participant learns a personalized mask and updates only a subnetwork of the full model. This personalized warmup allows the participants to focus initially on learning specific subnetworks tailored to the heterogeneity of their data. After the warmup phase, the participants revert to standard federated optimization, where all parameters are communicated. We empirically demonstrate that the proposed personalized warmup via subnetworks (FedPeWS) approach improves accuracy and convergence speed over standard federated optimization methods.
Redefining Contributions: Shapley-Driven Federated Learning
Jun 01, 2024Federated learning (FL) has emerged as a pivotal approach in machine learning, enabling multiple participants to collaboratively train a global model without sharing raw data. While FL finds applications in various domains such as healthcare and finance, it is challenging to ensure global model convergence when participants do not contribute equally and/or honestly. To overcome this challenge, principled mechanisms are required to evaluate the contributions made by individual participants in the FL setting. Existing solutions for contribution assessment rely on general accuracy evaluation, often failing to capture nuanced dynamics and class-specific influences. This paper proposes a novel contribution assessment method called ShapFed for fine-grained evaluation of participant contributions in FL. Our approach uses Shapley values from cooperative game theory to provide a granular understanding of class-specific influences. Based on ShapFed, we introduce a weighted aggregation method called ShapFed-WA, which outperforms conventional federated averaging, especially in class-imbalanced scenarios. Personalizing participant updates based on their contributions further enhances collaborative fairness by delivering differentiated models commensurate with the participant contributions. Experiments on CIFAR-10, Chest X-Ray, and Fed-ISIC2019 datasets demonstrate the effectiveness of our approach in improving utility, efficiency, and fairness in FL systems. The code can be found at https://github.com/tnurbek/shapfed.
Remove that Square Root: A New Efficient Scale-Invariant Version of AdaGrad
Mar 05, 2024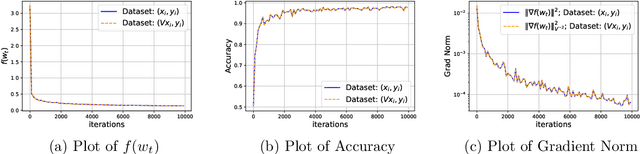
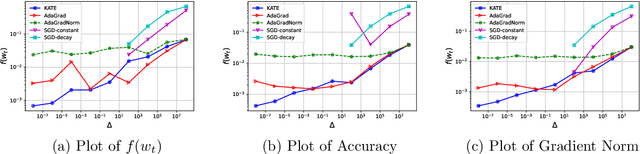
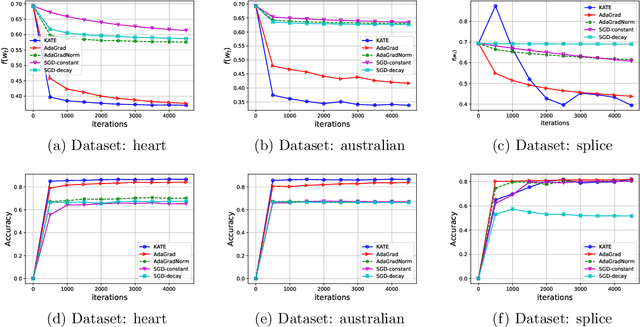
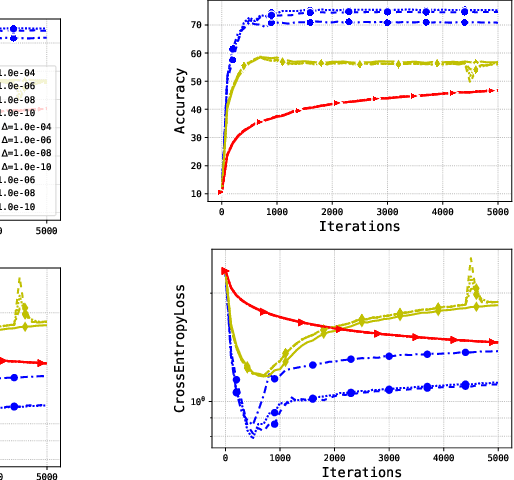
Adaptive methods are extremely popular in machine learning as they make learning rate tuning less expensive. This paper introduces a novel optimization algorithm named KATE, which presents a scale-invariant adaptation of the well-known AdaGrad algorithm. We prove the scale-invariance of KATE for the case of Generalized Linear Models. Moreover, for general smooth non-convex problems, we establish a convergence rate of $O \left(\frac{\log T}{\sqrt{T}} \right)$ for KATE, matching the best-known ones for AdaGrad and Adam. We also compare KATE to other state-of-the-art adaptive algorithms Adam and AdaGrad in numerical experiments with different problems, including complex machine learning tasks like image classification and text classification on real data. The results indicate that KATE consistently outperforms AdaGrad and matches/surpasses the performance of Adam in all considered scenarios.