 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Machine Translation through the Lens of Personalized Federated Learning
Jun 18, 2024



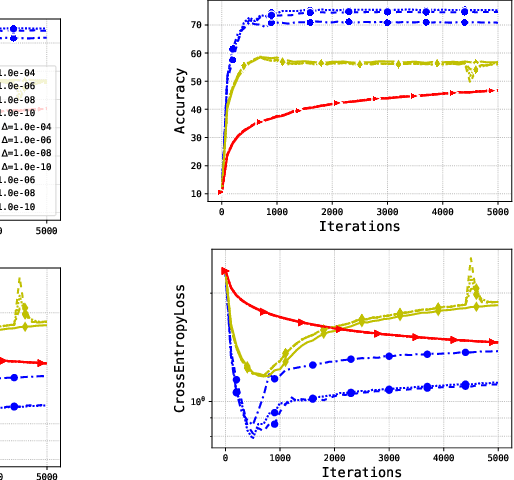
We present a new approach based on the Personalized Federated Learning algorithm MeritFed that can be applied to Natural Language Tasks with heterogeneous data. We evaluate it on the Low-Resource Machine Translation task, using the dataset from the Large-Scale Multilingual Machine Translation Shared Task (Small Track #2) and the subset of Sami languages from the multilingual benchmark for Finno-Ugric languages. In addition to its effectiveness, MeritFed is also highly interpretable, as it can be applied to track the impact of each language used for training. Our analysis reveals that target dataset size affects weight distribution across auxiliary languages, that unrelated languages do not interfere with the training, and auxiliary optimizer parameters have minimal impact. Our approach is easy to apply with a few lines of code, and we provide scripts for reproducing the experiments at https://github.com/VityaVitalich/MeritFed
Remove that Square Root: A New Efficient Scale-Invariant Version of AdaGrad
Mar 05, 2024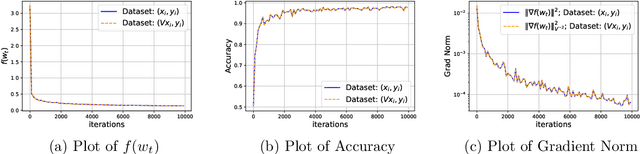
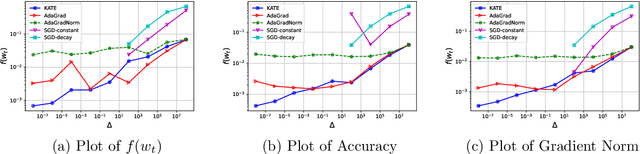
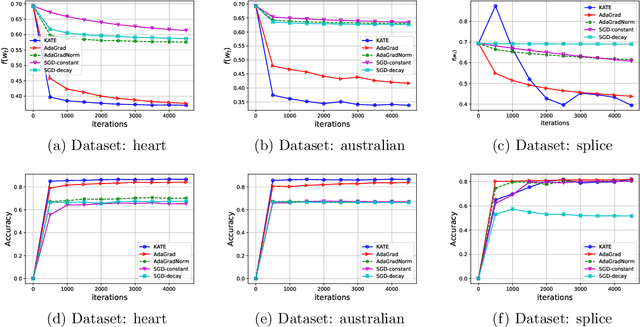
Adaptive methods are extremely popular in machine learning as they make learning rate tuning less expensive. This paper introduces a novel optimization algorithm named KATE, which presents a scale-invariant adaptation of the well-known AdaGrad algorithm. We prove the scale-invariance of KATE for the case of Generalized Linear Models. Moreover, for general smooth non-convex problems, we establish a convergence rate of $O \left(\frac{\log T}{\sqrt{T}} \right)$ for KATE, matching the best-known ones for AdaGrad and Adam. We also compare KATE to other state-of-the-art adaptive algorithms Adam and AdaGrad in numerical experiments with different problems, including complex machine learning tasks like image classification and text classification on real data. The results indicate that KATE consistently outperforms AdaGrad and matches/surpasses the performance of Adam in all considered scenarios.
Federated Learning Can Find Friends That Are Beneficial
Feb 14, 2024In Federated Learning (FL), the distributed nature and heterogeneity of client data present both opportunities and challenges. While collaboration among clients can significantly enhance the learning process, not all collaborations are beneficial; some may even be detrimental. In this study, we introduce a novel algorithm that assigns adaptive aggregation weights to clients participating in FL training, identifying those with data distributions most conducive to a specific learning objective. We demonstrate that our aggregation method converges no worse than the method that aggregates only the updates received from clients with the same data distribution. Furthermore, empirical evaluations consistently reveal that collaborations guided by our algorithm outperform traditional FL approaches. This underscores the critical role of judicious client selection and lays the foundation for more streamlined and effective FL implementations in the coming years.
Byzantine-Tolerant Methods for Distributed Variational Inequalities
Nov 08, 2023
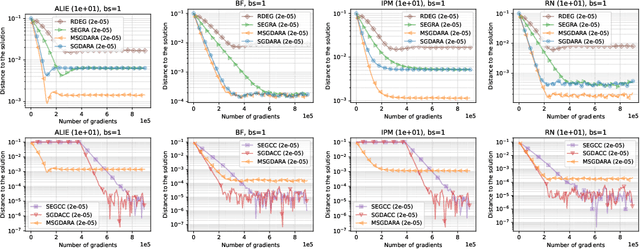
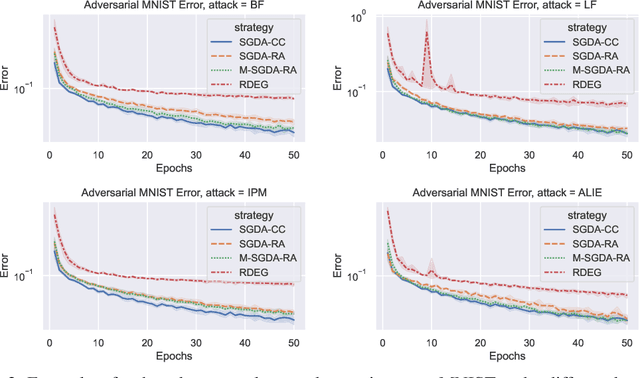
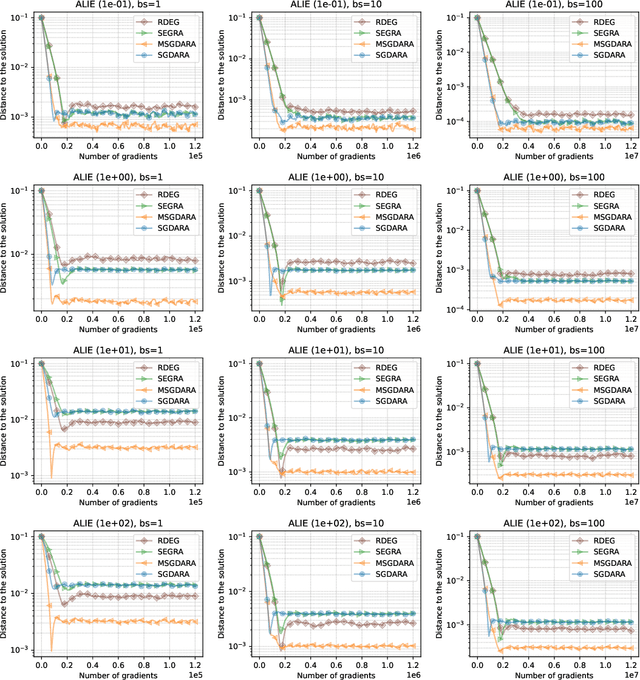
Robustness to Byzantine attacks is a necessity for various distributed training scenarios. When the training reduces to the process of solving a minimization problem, Byzantine robustness is relatively well-understood. However, other problem formulations, such as min-max problems or, more generally, variational inequalities, arise in many modern machine learning and, in particular, distributed learning tasks. These problems significantly differ from the standard minimization ones and, therefore, require separate consideration. Nevertheless, only one work (Adibi et al., 2022) addresses this important question in the context of Byzantine robustness. Our work makes a further step in this direction by providing several (provably) Byzantine-robust methods for distributed variational inequality, thoroughly studying their theoretical convergence, removing the limitations of the previous work, and providing numerical comparisons supporting the theoretical findings.