 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 9: Detecting Multilingual, Multicultural and Multievent Online Polarization
Apr 08, 2026We present SemEval-2026 Task 9, a shared task on online polarization detection, covering 22 languages and comprising over 110K annotated instances. Each data instance is multi-labeled with the presence of polarization, polarization type, and polarization manifestation. Participants were asked to predict labels in three sub-tasks: (1) detecting the presence of polarization, (2) identifying the type of polarization, and (3) recognizing the polarization manifestation. The three tasks attracted over 1,000 participants worldwide and more than 10k submission on Codabench. We received final submissions from 67 teams and 73 system description papers. We report the baseline results and analyze the performance of the best-performing systems, highlighting the most common approaches and the most effective methods across different subtasks and languages. The dataset of this task is publicly available.
Just Use XML: Revisiting Joint Translation and Label Projection
Mar 12, 2026Label projection is an effective technique for cross-lingual transfer, extending span-annotated datasets from a high-resource language to low-resource ones. Most approaches perform label projection as a separate step after machine translation, and prior work that combines the two reports degraded translation quality. We re-evaluate this claim with LabelPigeon, a novel framework that jointly performs translation and label projection via XML tags. We design a direct evaluation scheme for label projection, and find that LabelPigeon outperforms baselines and actively improves translation quality in 11 languages. We further assess translation quality across 203 languages and varying annotation complexity, finding consistent improvement attributed to additional fine-tuning. Finally, across 27 languages and three downstream tasks, we report substantial gains in cross-lingual transfer over comparable work, up to +39.9 F1 on NER. Overall, our results demonstrate that XML-tagged label projection provides effective and efficient label transfer without compromising translation quality.
Perspectives - Interactive Document Clustering in the Discourse Analysis Tool Suite
Feb 17, 2026This paper introduces Perspectives, an interactive extension of the Discourse Analysis Tool Suite designed to empower Digital Humanities (DH) scholars to explore and organize large, unstructured document collections. Perspectives implements a flexible, aspect-focused document clustering pipeline with human-in-the-loop refinement capabilities. We showcase how this process can be initially steered by defining analytical lenses through document rewriting prompts and instruction-based embeddings, and further aligned with user intent through tools for refining clusters and mechanisms for fine-tuning the embedding model. The demonstration highlights a typical workflow, illustrating how DH researchers can leverage Perspectives's interactive document map to uncover topics, sentiments, or other relevant categories, thereby gaining insights and preparing their data for subsequent in-depth analysis.
Comprehensive Comparison of RAG Methods Across Multi-Domain Conversational QA
Feb 10, 2026Conversational question answering increasingly relies on retrieval-augmented generation (RAG) to ground large language models (LLMs) in external knowledge. Yet, most existing studies evaluate RAG methods in isolation and primarily focus on single-turn settings. This paper addresses the lack of a systematic comparison of RAG methods for multi-turn conversational QA, where dialogue history, coreference, and shifting user intent substantially complicate retrieval. We present a comprehensive empirical study of vanilla and advanced RAG methods across eight diverse conversational QA datasets spanning multiple domains. Using a unified experimental setup, we evaluate retrieval quality and answer generation using generator and retrieval metrics, and analyze how performance evolves across conversation turns. Our results show that robust yet straightforward methods, such as reranking, hybrid BM25, and HyDE, consistently outperform vanilla RAG. In contrast, several advanced techniques fail to yield gains and can even degrade performance below the No-RAG baseline. We further demonstrate that dataset characteristics and dialogue length strongly influence retrieval effectiveness, explaining why no single RAG strategy dominates across settings. Overall, our findings indicate that effective conversational RAG depends less on method complexity than on alignment between the retrieval strategy and the dataset structure. We publish the code used.\footnote{\href{https://github.com/Klejda-A/exp-rag.git}{GitHub Repository}}
LEMUR: A Corpus for Robust Fine-Tuning of Multilingual Law Embedding Models for Retrieval
Feb 10, 2026Large language models (LLMs) are increasingly used to access legal information. Yet, their deployment in multilingual legal settings is constrained by unreliable retrieval and the lack of domain-adapted, open-embedding models. In particular, existing multilingual legal corpora are not designed for semantic retrieval, and PDF-based legislative sources introduce substantial noise due to imperfect text extraction. To address these challenges, we introduce LEMUR, a large-scale multilingual corpus of EU environmental legislation constructed from 24,953 official EUR-Lex PDF documents covering 25 languages. We quantify the fidelity of PDF-to-text conversion by measuring lexical consistency against authoritative HTML versions using the Lexical Content Score (LCS). Building on LEMUR, we fine-tune three state-of-the-art multilingual embedding models using contrastive objectives in both monolingual and bilingual settings, reflecting realistic legal-retrieval scenarios. Experiments across low- and high-resource languages demonstrate that legal-domain fine-tuning consistently improves Top-k retrieval accuracy relative to strong baselines, with particularly pronounced gains for low-resource languages. Cross-lingual evaluations show that these improvements transfer to unseen languages, indicating that fine-tuning primarily enhances language-independent, content-level legal representations rather than language-specific cues. We publish code\footnote{\href{https://github.com/nargesbh/eur_lex}{GitHub Repository}} and data\footnote{\href{https://huggingface.co/datasets/G4KMU/LEMUR}{Hugging Face Dataset}}.
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Jun 13, 2025Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans -- a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
MTabVQA: Evaluating Multi-Tabular Reasoning of Language Models in Visual Space
Jun 13, 2025Vision-Language Models (VLMs) have demonstrated remarkable capabilities in interpreting visual layouts and text. However, a significant challenge remains in their ability to interpret robustly and reason over multi-tabular data presented as images, a common occurrence in real-world scenarios like web pages and digital documents. Existing benchmarks typically address single tables or non-visual data (text/structured). This leaves a critical gap: they don't assess the ability to parse diverse table images, correlate information across them, and perform multi-hop reasoning on the combined visual data. We introduce MTabVQA, a novel benchmark specifically designed for multi-tabular visual question answering to bridge that gap. MTabVQA comprises 3,745 complex question-answer pairs that necessitate multi-hop reasoning across several visually rendered table images. We provide extensive benchmark results for state-of-the-art VLMs on MTabVQA, revealing significant performance limitations. We further investigate post-training techniques to enhance these reasoning abilities and release MTabVQA-Instruct, a large-scale instruction-tuning dataset. Our experiments show that fine-tuning VLMs with MTabVQA-Instruct substantially improves their performance on visual multi-tabular reasoning. Code and dataset (https://huggingface.co/datasets/mtabvqa/MTabVQA-Eval) are available online (https://anonymous.4open.science/r/MTabVQA-EMNLP-B16E).
FASCIST-O-METER: Classifier for Neo-fascist Discourse Online
Jun 12, 2025Neo-fascism is a political and societal ideology that has been having remarkable growth in the last decade in the United States of America (USA), as well as in other Western societies. It poses a grave danger to democracy and the minorities it targets, and it requires active actions against it to avoid escalation. This work presents the first-of-its-kind neo-fascist coding scheme for digital discourse in the USA societal context, overseen by political science researchers. Our work bridges the gap between Natural Language Processing (NLP) and political science against this phenomena. Furthermore, to test the coding scheme, we collect a tremendous amount of activity on the internet from notable neo-fascist groups (the forums of Iron March and Stormfront.org), and the guidelines are applied to a subset of the collected posts. Through crowdsourcing, we annotate a total of a thousand posts that are labeled as neo-fascist or non-neo-fascist. With this labeled data set, we fine-tune and test both Small Language Models (SLMs) and Large Language Models (LLMs), obtaining the very first classification models for neo-fascist discourse. We find that the prevalence of neo-fascist rhetoric in this kind of forum is ever-present, making them a good target for future research. The societal context is a key consideration for neo-fascist speech when conducting NLP research. Finally, the work against this kind of political movement must be pressed upon and continued for the well-being of a democratic society. Disclaimer: This study focuses on detecting neo-fascist content in text, similar to other hate speech analyses, without labeling individuals or organizations.
Chinese Toxic Language Mitigation via Sentiment Polarity Consistent Rewrites
May 21, 2025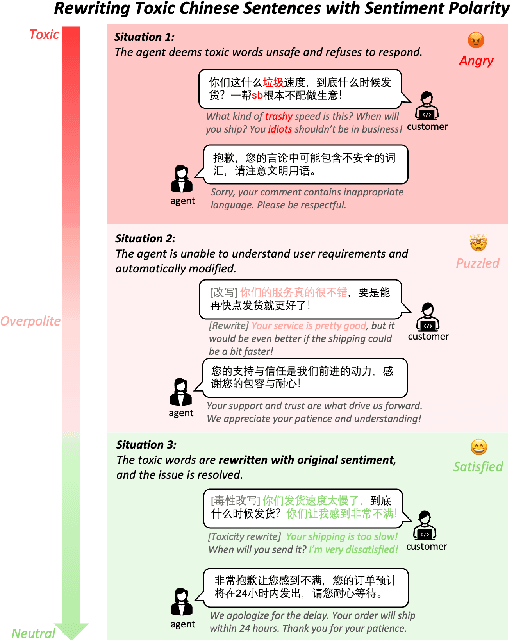
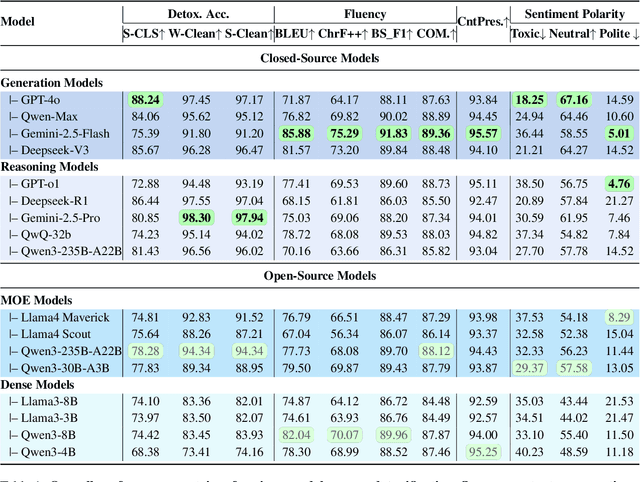
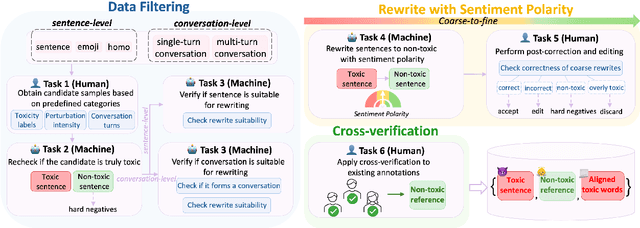
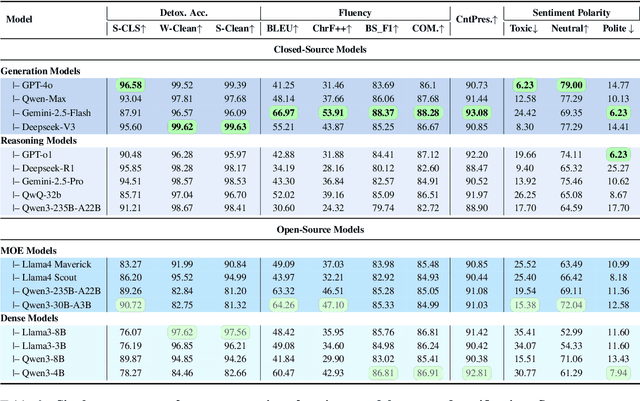
Detoxifying offensive language while preserving the speaker's original intent is a challenging yet critical goal for improving the quality of online interactions. Although large language models (LLMs) show promise in rewriting toxic content, they often default to overly polite rewrites, distorting the emotional tone and communicative intent. This problem is especially acute in Chinese, where toxicity often arises implicitly through emojis, homophones, or discourse context. We present ToxiRewriteCN, the first Chinese detoxification dataset explicitly designed to preserve sentiment polarity. The dataset comprises 1,556 carefully annotated triplets, each containing a toxic sentence, a sentiment-aligned non-toxic rewrite, and labeled toxic spans. It covers five real-world scenarios: standard expressions, emoji-induced and homophonic toxicity, as well as single-turn and multi-turn dialogues. We evaluate 17 LLMs, including commercial and open-source models with variant architectures, across four dimensions: detoxification accuracy, fluency, content preservation, and sentiment polarity. Results show that while commercial and MoE models perform best overall, all models struggle to balance safety with emotional fidelity in more subtle or context-heavy settings such as emoji, homophone, and dialogue-based inputs. We release ToxiRewriteCN to support future research on controllable, sentiment-aware detoxification for Chinese.
CollEX -- A Multimodal Agentic RAG System Enabling Interactive Exploration of Scientific Collections
Apr 10, 2025In this paper, we introduce CollEx, an innovative multimodal agentic Retrieval-Augmented Generation (RAG) system designed to enhance interactive exploration of extensive scientific collections. Given the overwhelming volume and inherent complexity of scientific collections, conventional search systems often lack necessary intuitiveness and interactivity, presenting substantial barriers for learners, educators, and researchers. CollEx addresses these limitations by employing state-of-the-art Large Vision-Language Models (LVLMs) as multimodal agents accessible through an intuitive chat interface. By abstracting complex interactions via specialized agents equipped with advanced tools, CollEx facilitates curiosity-driven exploration, significantly simplifying access to diverse scientific collections and records therein. Our system integrates textual and visual modalities, supporting educational scenarios that are helpful for teachers, pupils, students, and researchers by fostering independent exploration as well as scientific excitement and curiosity. Furthermore, CollEx serves the research community by discovering interdisciplinary connections and complementing visual data. We illustrate the effectiveness of our system through a proof-of-concept application containing over 64,000 unique records across 32 collections from a local scientific collection from a public university.