 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroVerse: A Preliminary Exploration Toward a Micro-World Simulation
Feb 28, 2026Recent advances in video generation have opened new avenues for macroscopic simulation of complex dynamic systems, but their application to microscopic phenomena remains largely unexplored. Microscale simulation holds great promise for biomedical applications such as drug discovery, organ-on-chip systems, and disease mechanism studies, while also showing potential in education and interactive visualization. In this work, we introduce MicroWorldBench, a multi-level rubric-based benchmark for microscale simulation tasks. MicroWorldBench enables systematic, rubric-based evaluation through 459 unique expert-annotated criteria spanning multiple microscale simulation task (e.g., organ-level processes, cellular dynamics, and subcellular molecular interactions) and evaluation dimensions (e.g., scientific fidelity, visual quality, instruction following). MicroWorldBench reveals that current SOTA video generation models fail in microscale simulation, showing violations of physical laws, temporal inconsistency, and misalignment with expert criteria. To address these limitations, we construct MicroSim-10K, a high-quality, expert-verified simulation dataset. Leveraging this dataset, we train MicroVerse, a video generation model tailored for microscale simulation. MicroVerse can accurately reproduce complex microscale mechanism. Our work first introduce the concept of Micro-World Simulation and present a proof of concept, paving the way for applications in biology, education, and scientific visualization. Our work demonstrates the potential of educational microscale simulations of biological mechanisms. Our data and code are publicly available at https://github.com/FreedomIntelligence/MicroVerse
Towards Assessing Medical Ethics from Knowledge to Practice
Aug 07, 2025The integration of large language models into healthcare necessitates a rigorous evaluation of their ethical reasoning, an area current benchmarks often overlook. We introduce PrinciplismQA, a comprehensive benchmark with 3,648 questions designed to systematically assess LLMs' alignment with core medical ethics. Grounded in Principlism, our benchmark features a high-quality dataset. This includes multiple-choice questions curated from authoritative textbooks and open-ended questions sourced from authoritative medical ethics case study literature, all validated by medical experts. Our experiments reveal a significant gap between models' ethical knowledge and their practical application, especially in dynamically applying ethical principles to real-world scenarios. Most LLMs struggle with dilemmas concerning Beneficence, often over-emphasizing other principles. Frontier closed-source models, driven by strong general capabilities, currently lead the benchmark. Notably, medical domain fine-tuning can enhance models' overall ethical competence, but further progress requires better alignment with medical ethical knowledge. PrinciplismQA offers a scalable framework to diagnose these specific ethical weaknesses, paving the way for more balanced and responsible medical AI.
Marco-Bench-MIF: On Multilingual Instruction-Following Capability of Large Language Models
Jul 16, 2025Instruction-following capability has become a major ability to be evaluated for Large Language Models (LLMs). However, existing datasets, such as IFEval, are either predominantly monolingual and centered on English or simply machine translated to other languages, limiting their applicability in multilingual contexts. In this paper, we present an carefully-curated extension of IFEval to a localized multilingual version named Marco-Bench-MIF, covering 30 languages with varying levels of localization. Our benchmark addresses linguistic constraints (e.g., modifying capitalization requirements for Chinese) and cultural references (e.g., substituting region-specific company names in prompts) via a hybrid pipeline combining translation with verification. Through comprehensive evaluation of 20+ LLMs on our Marco-Bench-MIF, we found that: (1) 25-35% accuracy gap between high/low-resource languages, (2) model scales largely impact performance by 45-60% yet persists script-specific challenges, and (3) machine-translated data underestimates accuracy by7-22% versus localized data. Our analysis identifies challenges in multilingual instruction following, including keyword consistency preservation and compositional constraint adherence across languages. Our Marco-Bench-MIF is available at https://github.com/AIDC-AI/Marco-Bench-MIF.
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Jun 13, 2025Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans -- a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
TransBench: Benchmarking Machine Translation for Industrial-Scale Applications
May 20, 2025Machine translation (MT) has become indispensable for cross-border communication in globalized industries like e-commerce, finance, and legal services, with recent advancements in large language models (LLMs) significantly enhancing translation quality. However, applying general-purpose MT models to industrial scenarios reveals critical limitations due to domain-specific terminology, cultural nuances, and stylistic conventions absent in generic benchmarks. Existing evaluation frameworks inadequately assess performance in specialized contexts, creating a gap between academic benchmarks and real-world efficacy. To address this, we propose a three-level translation capability framework: (1) Basic Linguistic Competence, (2) Domain-Specific Proficiency, and (3) Cultural Adaptation, emphasizing the need for holistic evaluation across these dimensions. We introduce TransBench, a benchmark tailored for industrial MT, initially targeting international e-commerce with 17,000 professionally translated sentences spanning 4 main scenarios and 33 language pairs. TransBench integrates traditional metrics (BLEU, TER) with Marco-MOS, a domain-specific evaluation model, and provides guidelines for reproducible benchmark construction. Our contributions include: (1) a structured framework for industrial MT evaluation, (2) the first publicly available benchmark for e-commerce translation, (3) novel metrics probing multi-level translation quality, and (4) open-sourced evaluation tools. This work bridges the evaluation gap, enabling researchers and practitioners to systematically assess and enhance MT systems for industry-specific needs.
HBO: Hierarchical Balancing Optimization for Fine-Tuning Large Language Models
May 18, 2025Fine-tuning large language models (LLMs) on a mixture of diverse datasets poses challenges due to data imbalance and heterogeneity. Existing methods often address these issues across datasets (globally) but overlook the imbalance and heterogeneity within individual datasets (locally), which limits their effectiveness. We introduce Hierarchical Balancing Optimization (HBO), a novel method that enables LLMs to autonomously adjust data allocation during fine-tuning both across datasets (globally) and within each individual dataset (locally). HBO employs a bilevel optimization strategy with two types of actors: a Global Actor, which balances data sampling across different subsets of the training mixture, and several Local Actors, which optimizes data usage within each subset based on difficulty levels. These actors are guided by reward functions derived from the LLM's training state, which measure learning progress and relative performance improvement. We evaluate HBO on three LLM backbones across nine diverse tasks in multilingual and multitask setups. Results show that HBO consistently outperforms existing baselines, achieving significant accuracy gains. Our in-depth analysis further demonstrates that both the global actor and local actors of HBO effectively adjust data usage during fine-tuning. HBO provides a comprehensive solution to the challenges of data imbalance and heterogeneity in LLM fine-tuning, enabling more effective training across diverse datasets.
ExpertSteer: Intervening in LLMs through Expert Knowledge
May 18, 2025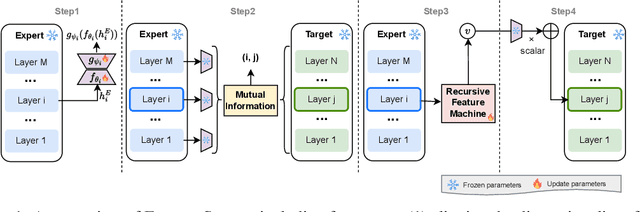
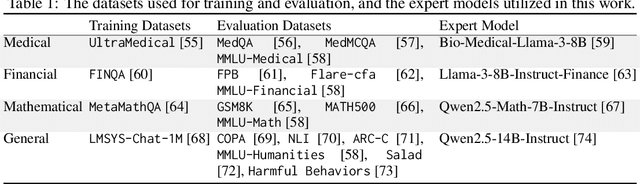
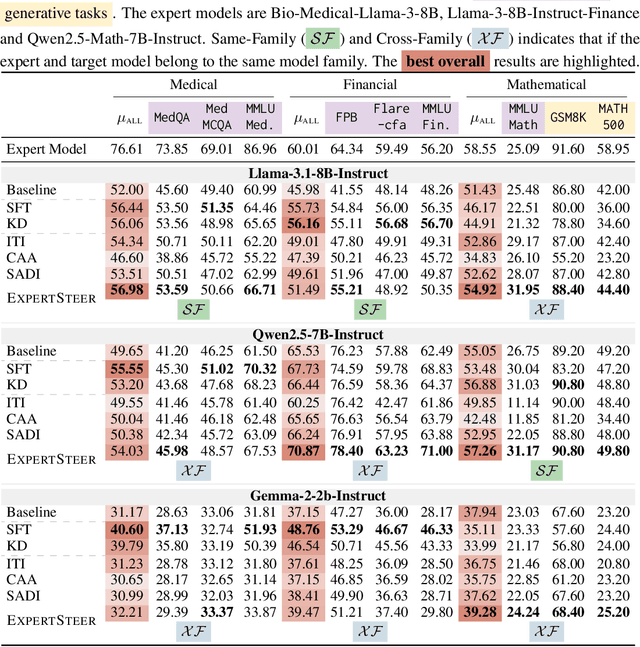
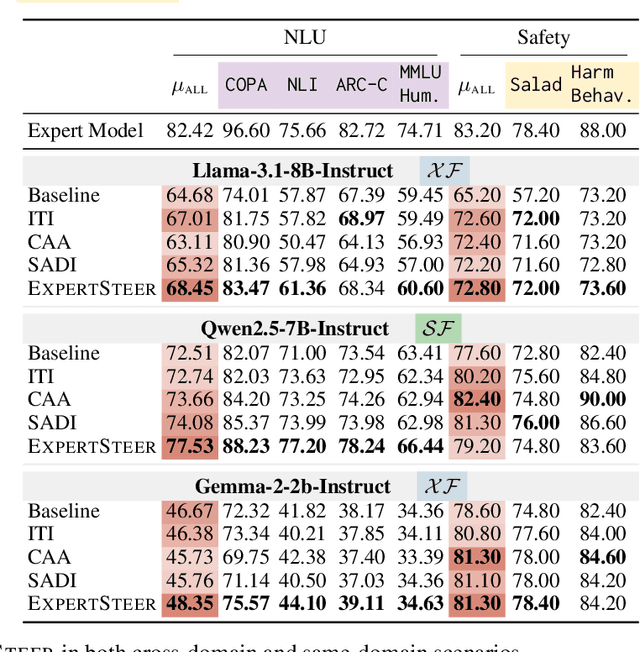
Large Language Models (LLMs) exhibit remarkable capabilities across various tasks, yet guiding them to follow desired behaviours during inference remains a significant challenge. Activation steering offers a promising method to control the generation process of LLMs by modifying their internal activations. However, existing methods commonly intervene in the model's behaviour using steering vectors generated by the model itself, which constrains their effectiveness to that specific model and excludes the possibility of leveraging powerful external expert models for steering. To address these limitations, we propose ExpertSteer, a novel approach that leverages arbitrary specialized expert models to generate steering vectors, enabling intervention in any LLMs. ExpertSteer transfers the knowledge from an expert model to a target LLM through a cohesive four-step process: first aligning representation dimensions with auto-encoders to enable cross-model transfer, then identifying intervention layer pairs based on mutual information analysis, next generating steering vectors from the expert model using Recursive Feature Machines, and finally applying these vectors on the identified layers during inference to selectively guide the target LLM without updating model parameters. We conduct comprehensive experiments using three LLMs on 15 popular benchmarks across four distinct domains. Experiments demonstrate that ExpertSteer significantly outperforms established baselines across diverse tasks at minimal cost.
The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks
Apr 22, 2025



As large language models (LLMs) continue to advance in linguistic capabilities, robust multilingual evaluation has become essential for promoting equitable technological progress. This position paper examines over 2,000 multilingual (non-English) benchmarks from 148 countries, published between 2021 and 2024, to evaluate past, present, and future practices in multilingual benchmarking. Our findings reveal that, despite significant investments amounting to tens of millions of dollars, English remains significantly overrepresented in these benchmarks. Additionally, most benchmarks rely on original language content rather than translations, with the majority sourced from high-resource countries such as China, India, Germany, the UK, and the USA. Furthermore, a comparison of benchmark performance with human judgments highlights notable disparities. STEM-related tasks exhibit strong correlations with human evaluations (0.70 to 0.85), while traditional NLP tasks like question answering (e.g., XQuAD) show much weaker correlations (0.11 to 0.30). Moreover, translating English benchmarks into other languages proves insufficient, as localized benchmarks demonstrate significantly higher alignment with local human judgments (0.68) than their translated counterparts (0.47). This underscores the importance of creating culturally and linguistically tailored benchmarks rather than relying solely on translations. Through this comprehensive analysis, we highlight six key limitations in current multilingual evaluation practices, propose the guiding principles accordingly for effective multilingual benchmarking, and outline five critical research directions to drive progress in the field. Finally, we call for a global collaborative effort to develop human-aligned benchmarks that prioritize real-world applications.
New Trends for Modern Machine Translation with Large Reasoning Models
Mar 13, 2025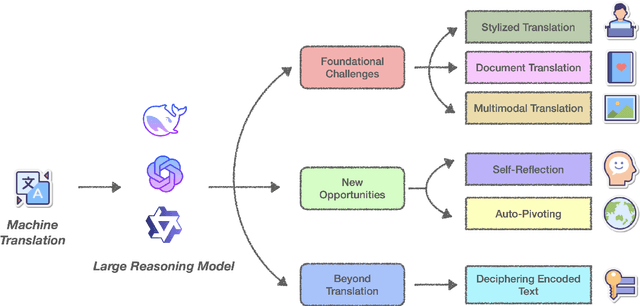



Recent advances in Large Reasoning Models (LRMs), particularly those leveraging Chain-of-Thought reasoning (CoT), have opened brand new possibility for Machine Translation (MT). This position paper argues that LRMs substantially transformed traditional neural MT as well as LLMs-based MT paradigms by reframing translation as a dynamic reasoning task that requires contextual, cultural, and linguistic understanding and reasoning. We identify three foundational shifts: 1) contextual coherence, where LRMs resolve ambiguities and preserve discourse structure through explicit reasoning over cross-sentence and complex context or even lack of context; 2) cultural intentionality, enabling models to adapt outputs by inferring speaker intent, audience expectations, and socio-linguistic norms; 3) self-reflection, LRMs can perform self-reflection during the inference time to correct the potential errors in translation especially extremely noisy cases, showing better robustness compared to simply mapping X->Y translation. We explore various scenarios in translation including stylized translation, document-level translation and multimodal translation by showcasing empirical examples that demonstrate the superiority of LRMs in translation. We also identify several interesting phenomenons for LRMs for MT including auto-pivot translation as well as the critical challenges such as over-localisation in translation and inference efficiency. In conclusion, we think that LRMs redefine translation systems not merely as text converters but as multilingual cognitive agents capable of reasoning about meaning beyond the text. This paradigm shift reminds us to think of problems in translation beyond traditional translation scenarios in a much broader context with LRMs - what we can achieve on top of it.
Towards Widening The Distillation Bottleneck for Reasoning Models
Mar 03, 2025Large Reasoning Models(LRMs) such as OpenAI o1 and DeepSeek-R1 have shown remarkable reasoning capabilities by scaling test-time compute and generating long Chain-of-Thought(CoT). Distillation--post-training on LRMs-generated data--is a straightforward yet effective method to enhance the reasoning abilities of smaller models, but faces a critical bottleneck: we found that distilled long CoT data poses learning difficulty for small models and leads to the inheritance of biases (i.e. over-thinking) when using Supervised Fine-tuning(SFT) and Reinforcement Learning(RL) methods. To alleviate this bottleneck, we propose constructing tree-based CoT data from scratch via Monte Carlo Tree Search(MCTS). We then exploit a set of CoT-aware approaches, including Thoughts Length Balance, Fine-grained DPO, and Joint Post-training Objective, to enhance SFT and RL on the construted data.