 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
F-Actor: Controllable Conversational Behaviour in Full-Duplex Models
Jan 16, 2026Spoken conversational systems require more than accurate speech generation to have human-like conversations: to feel natural and engaging, they must produce conversational behaviour that adapts dynamically to the context. Current spoken conversational systems, however, rarely allow such customization, limiting their naturalness and usability. In this work, we present the first open, instruction-following full-duplex conversational speech model that can be trained efficiently under typical academic resource constraints. By keeping the audio encoder frozen and finetuning only the language model, our model requires just 2,000 hours of data, without relying on large-scale pretraining or multi-stage optimization. The model can follow explicit instructions to control speaker voice, conversation topic, conversational behaviour (e.g., backchanneling and interruptions), and dialogue initiation. We propose a single-stage training protocol and systematically analyze design choices. Both the model and training code will be released to enable reproducible research on controllable full-duplex speech systems.
EuroGEST: Investigating gender stereotypes in multilingual language models
Jun 04, 2025Large language models increasingly support multiple languages, yet most benchmarks for gender bias remain English-centric. We introduce EuroGEST, a dataset designed to measure gender-stereotypical reasoning in LLMs across English and 29 European languages. EuroGEST builds on an existing expert-informed benchmark covering 16 gender stereotypes, expanded in this work using translation tools, quality estimation metrics, and morphological heuristics. Human evaluations confirm that our data generation method results in high accuracy of both translations and gender labels across languages. We use EuroGEST to evaluate 24 multilingual language models from six model families, demonstrating that the strongest stereotypes in all models across all languages are that women are 'beautiful', 'empathetic' and 'neat' and men are 'leaders', 'strong, tough' and 'professional'. We also show that larger models encode gendered stereotypes more strongly and that instruction finetuning does not consistently reduce gendered stereotypes. Our work highlights the need for more multilingual studies of fairness in LLMs and offers scalable methods and resources to audit gender bias across languages.
EuroLLM-9B: Technical Report
Jun 04, 2025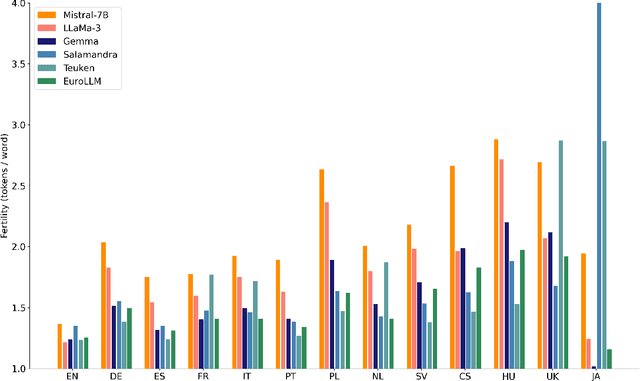
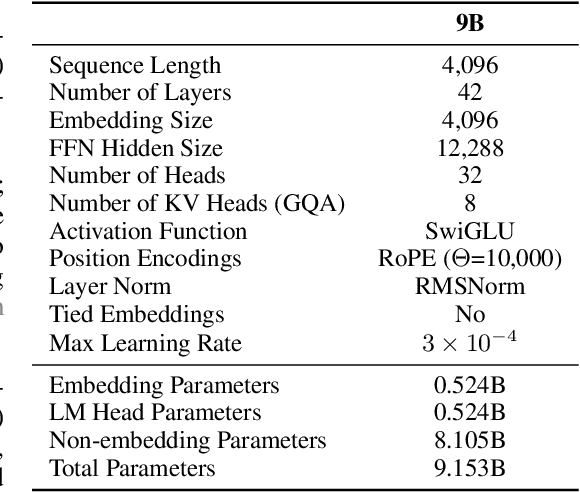
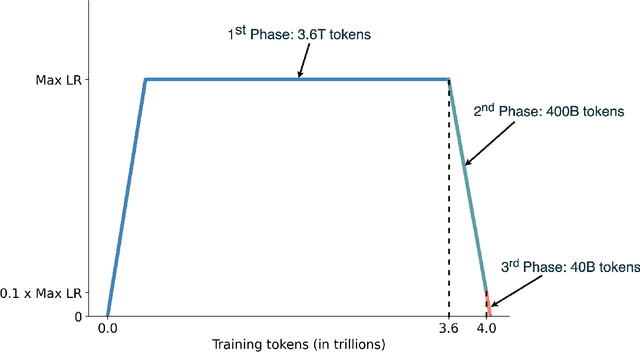
This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
ExpertSteer: Intervening in LLMs through Expert Knowledge
May 18, 2025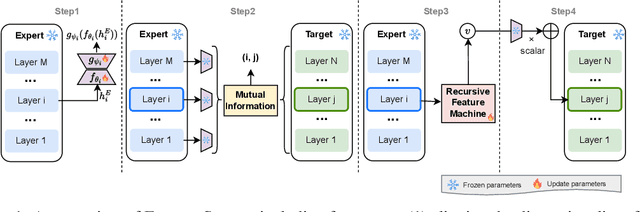
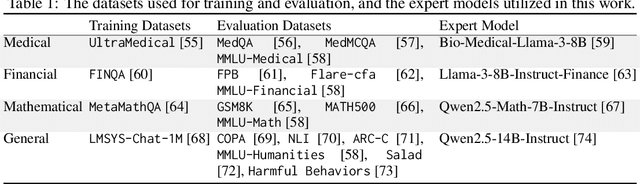
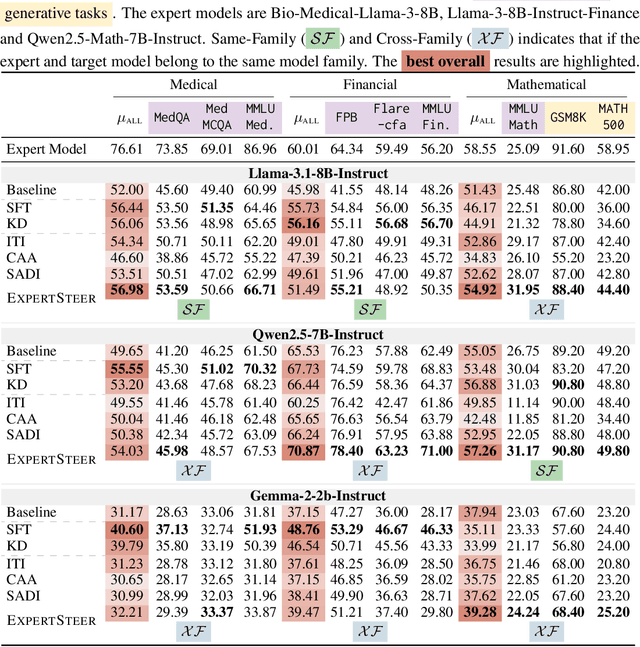
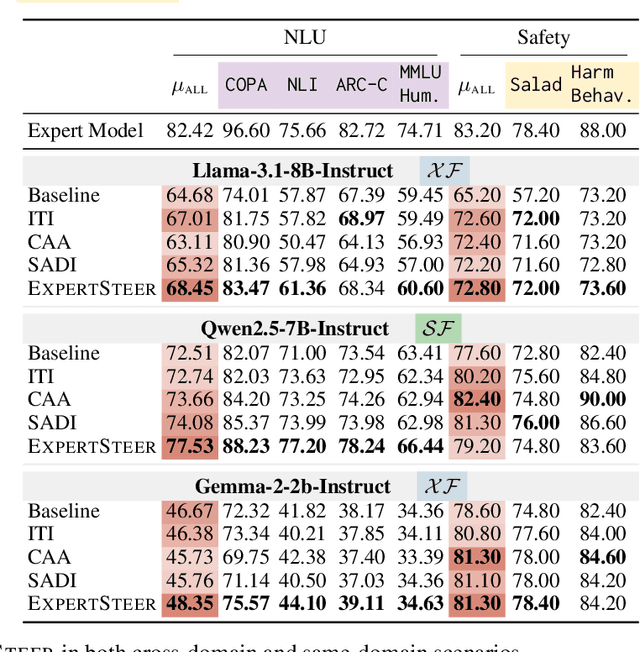
Large Language Models (LLMs) exhibit remarkable capabilities across various tasks, yet guiding them to follow desired behaviours during inference remains a significant challenge. Activation steering offers a promising method to control the generation process of LLMs by modifying their internal activations. However, existing methods commonly intervene in the model's behaviour using steering vectors generated by the model itself, which constrains their effectiveness to that specific model and excludes the possibility of leveraging powerful external expert models for steering. To address these limitations, we propose ExpertSteer, a novel approach that leverages arbitrary specialized expert models to generate steering vectors, enabling intervention in any LLMs. ExpertSteer transfers the knowledge from an expert model to a target LLM through a cohesive four-step process: first aligning representation dimensions with auto-encoders to enable cross-model transfer, then identifying intervention layer pairs based on mutual information analysis, next generating steering vectors from the expert model using Recursive Feature Machines, and finally applying these vectors on the identified layers during inference to selectively guide the target LLM without updating model parameters. We conduct comprehensive experiments using three LLMs on 15 popular benchmarks across four distinct domains. Experiments demonstrate that ExpertSteer significantly outperforms established baselines across diverse tasks at minimal cost.
HBO: Hierarchical Balancing Optimization for Fine-Tuning Large Language Models
May 18, 2025Fine-tuning large language models (LLMs) on a mixture of diverse datasets poses challenges due to data imbalance and heterogeneity. Existing methods often address these issues across datasets (globally) but overlook the imbalance and heterogeneity within individual datasets (locally), which limits their effectiveness. We introduce Hierarchical Balancing Optimization (HBO), a novel method that enables LLMs to autonomously adjust data allocation during fine-tuning both across datasets (globally) and within each individual dataset (locally). HBO employs a bilevel optimization strategy with two types of actors: a Global Actor, which balances data sampling across different subsets of the training mixture, and several Local Actors, which optimizes data usage within each subset based on difficulty levels. These actors are guided by reward functions derived from the LLM's training state, which measure learning progress and relative performance improvement. We evaluate HBO on three LLM backbones across nine diverse tasks in multilingual and multitask setups. Results show that HBO consistently outperforms existing baselines, achieving significant accuracy gains. Our in-depth analysis further demonstrates that both the global actor and local actors of HBO effectively adjust data usage during fine-tuning. HBO provides a comprehensive solution to the challenges of data imbalance and heterogeneity in LLM fine-tuning, enabling more effective training across diverse datasets.
Improving Multilingual Retrieval-Augmented Language Models through Dialectic Reasoning Argumentations
Apr 07, 2025Retrieval-augmented generation (RAG) is key to enhancing large language models (LLMs) to systematically access richer factual knowledge. Yet, using RAG brings intrinsic challenges, as LLMs must deal with potentially conflicting knowledge, especially in multilingual retrieval, where the heterogeneity of knowledge retrieved may deliver different outlooks. To make RAG more analytical, critical and grounded, we introduce Dialectic-RAG (DRAG), a modular approach guided by Argumentative Explanations, i.e., structured reasoning process that systematically evaluates retrieved information by comparing, contrasting, and resolving conflicting perspectives. Given a query and a set of multilingual related documents, DRAG selects and exemplifies relevant knowledge for delivering dialectic explanations that, by critically weighing opposing arguments and filtering extraneous content, clearly determine the final response. Through a series of in-depth experiments, we show the impact of our framework both as an in-context learning strategy and for constructing demonstrations to instruct smaller models. The final results demonstrate that DRAG significantly improves RAG approaches, requiring low-impact computational effort and providing robustness to knowledge perturbations.
Multilingual Retrieval-Augmented Generation for Knowledge-Intensive Task
Apr 04, 2025Retrieval-augmented generation (RAG) has become a cornerstone of contemporary NLP, enhancing large language models (LLMs) by allowing them to access richer factual contexts through in-context retrieval. While effective in monolingual settings, especially in English, its use in multilingual tasks remains unexplored. This paper investigates the effectiveness of RAG across multiple languages by proposing novel approaches for multilingual open-domain question-answering. We evaluate the performance of various multilingual RAG strategies, including question-translation (tRAG), which translates questions into English before retrieval, and Multilingual RAG (MultiRAG), where retrieval occurs directly across multiple languages. Our findings reveal that tRAG, while useful, suffers from limited coverage. In contrast, MultiRAG improves efficiency by enabling multilingual retrieval but introduces inconsistencies due to cross-lingual variations in the retrieved content. To address these issues, we propose Crosslingual RAG (CrossRAG), a method that translates retrieved documents into a common language (e.g., English) before generating the response. Our experiments show that CrossRAG significantly enhances performance on knowledge-intensive tasks, benefiting both high-resource and low-resource languages.
XL-Instruct: Synthetic Data for Cross-Lingual Open-Ended Generation
Mar 29, 2025Cross-lingual open-ended generation -- i.e. generating responses in a desired language different from that of the user's query -- is an important yet understudied problem. We introduce XL-AlpacaEval, a new benchmark for evaluating cross-lingual generation capabilities in Large Language Models (LLMs), and propose XL-Instruct, a high-quality synthetic data generation method. Fine-tuning with just 8K XL-Instruct-generated instructions significantly improves model performance, increasing the win rate against GPT-4o-Mini from 7.4% to 21.5%, and improving on several fine-grained quality metrics. Additionally, models fine-tuned on XL-Instruct exhibit strong zero-shot transfer to both English-only and multilingual generation tasks. Given its consistent gains across the board, we strongly recommend incorporating XL-Instruct in the post-training pipeline of future multilingual LLMs. To facilitate further research, we will publicly and freely release the XL-Instruct and XL-AlpacaEval datasets, which constitute two of the few cross-lingual resources currently available in the literature.
Generalizing From Short to Long: Effective Data Synthesis for Long-Context Instruction Tuning
Feb 21, 2025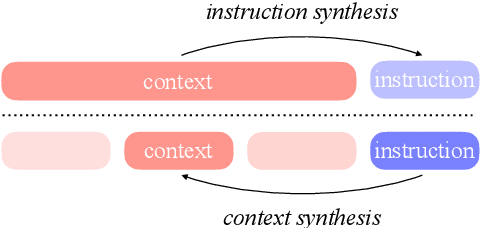

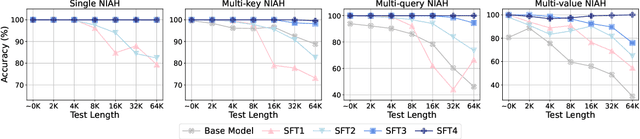
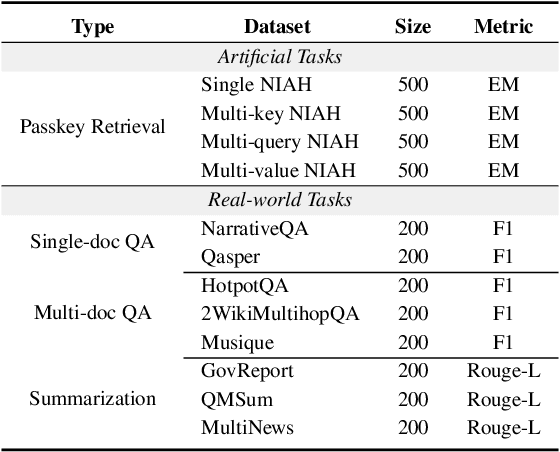
Long-context modelling for large language models (LLMs) has been a key area of recent research because many real world use cases require reasoning over longer inputs such as documents. The focus of research into modelling long context has been on how to model position and there has been little investigation into other important aspects of language modelling such as instruction tuning. Long context training examples are challenging and expensive to create and use. In this paper, we investigate how to design instruction data for the post-training phase of a long context pre-trained model: how much and what type of context is needed for optimal and efficient post-training. Our controlled study reveals that models instruction-tuned on short contexts can effectively generalize to longer ones, while also identifying other critical factors such as instruction difficulty and context composition. Based on these findings, we propose context synthesis, a novel data synthesis framework that leverages off-the-shelf LLMs to generate extended background contexts for high-quality instruction-answer pairs. Experiment results on the document-level benchmark (LongBench) demonstrate that our proposed approach outperforms previous instruction synthesis approaches and comes close to the performance of human-annotated long-context instruction data. The project will be available at: https://github.com/NJUNLP/context-synthesis.