 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-symbolic Syntactic Parsing: Shaping a Neural Network with the CYK Algorithm
May 29, 2026In this paper, we show the possibility of a direct injection of algorithms into neural network architecture. We focus on a complex algorithm, that is, Cocke-Youger-Kasami (CYK) for parsing context-free grammars in Chomsky Normal Form and we propose CYKNN, a simple recurrent neural network architecture for encoding the CYK algorithm in trainable matrix-vector multiplications.We experimented with a very simple grammar with 4 variations showing that our approach outperforms existing LLMs with more than 20B parameters with an in-context learning setting and smaller LLMs of the Qwen family fine-tuned with LoRA. Our attempt paves the way to a different approach to neuro-symbolic methodologies.
Protoknowledge Shapes Behaviour of LLMs in Downstream Tasks: Memorization and Generalization with Knowledge Graphs
May 21, 2025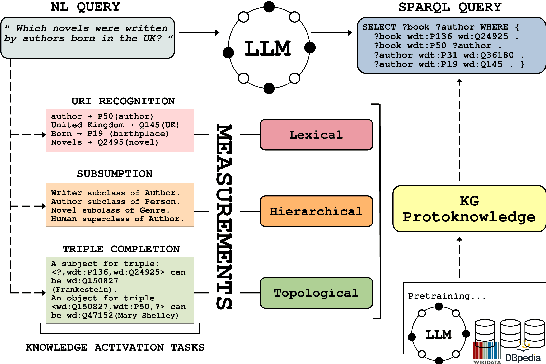



We introduce the concept of protoknowledge to formalize and measure how sequences of tokens encoding Knowledge Graphs are internalized during pretraining and utilized at inference time by Large Language Models (LLMs). Indeed, LLMs have demonstrated the ability to memorize vast amounts of token sequences during pretraining, and a central open question is how they leverage this memorization as reusable knowledge through generalization. We then categorize protoknowledge into lexical, hierarchical, and topological forms, varying on the type of knowledge that needs to be activated. We measure protoknowledge through Knowledge Activation Tasks (KATs), analyzing its general properties such as semantic bias. We then investigate the impact of protoknowledge on Text-to-SPARQL performance by varying prompting strategies depending on input conditions. To this end, we adopt a novel analysis framework that assesses whether model predictions align with the successful activation of the relevant protoknowledge for each query. This methodology provides a practical tool to explore Semantic-Level Data Contamination and serves as an effective strategy for Closed-Pretraining models.
Improving Multilingual Retrieval-Augmented Language Models through Dialectic Reasoning Argumentations
Apr 07, 2025Retrieval-augmented generation (RAG) is key to enhancing large language models (LLMs) to systematically access richer factual knowledge. Yet, using RAG brings intrinsic challenges, as LLMs must deal with potentially conflicting knowledge, especially in multilingual retrieval, where the heterogeneity of knowledge retrieved may deliver different outlooks. To make RAG more analytical, critical and grounded, we introduce Dialectic-RAG (DRAG), a modular approach guided by Argumentative Explanations, i.e., structured reasoning process that systematically evaluates retrieved information by comparing, contrasting, and resolving conflicting perspectives. Given a query and a set of multilingual related documents, DRAG selects and exemplifies relevant knowledge for delivering dialectic explanations that, by critically weighing opposing arguments and filtering extraneous content, clearly determine the final response. Through a series of in-depth experiments, we show the impact of our framework both as an in-context learning strategy and for constructing demonstrations to instruct smaller models. The final results demonstrate that DRAG significantly improves RAG approaches, requiring low-impact computational effort and providing robustness to knowledge perturbations.
MeMo: Towards Language Models with Associative Memory Mechanisms
Feb 18, 2025



Memorization is a fundamental ability of Transformer-based Large Language Models, achieved through learning. In this paper, we propose a paradigm shift by designing an architecture to memorize text directly, bearing in mind the principle that memorization precedes learning. We introduce MeMo, a novel architecture for language modeling that explicitly memorizes sequences of tokens in layered associative memories. By design, MeMo offers transparency and the possibility of model editing, including forgetting texts. We experimented with the MeMo architecture, showing the memorization power of the one-layer and the multi-layer configurations.
Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL Translation
Feb 12, 2024



Understanding textual description to generate code seems to be an achieved capability of instruction-following Large Language Models (LLMs) in zero-shot scenario. However, there is a severe possibility that this translation ability may be influenced by having seen target textual descriptions and the related code. This effect is known as Data Contamination. In this study, we investigate the impact of Data Contamination on the performance of GPT-3.5 in the Text-to-SQL code-generating tasks. Hence, we introduce a novel method to detect Data Contamination in GPTs and examine GPT-3.5's Text-to-SQL performances using the known Spider Dataset and our new unfamiliar dataset Termite. Furthermore, we analyze GPT-3.5's efficacy on databases with modified information via an adversarial table disconnection (ATD) approach, complicating Text-to-SQL tasks by removing structural pieces of information from the database. Our results indicate a significant performance drop in GPT-3.5 on the unfamiliar Termite dataset, even with ATD modifications, highlighting the effect of Data Contamination on LLMs in Text-to-SQL translation tasks.
Exploring Linguistic Properties of Monolingual BERTs with Typological Classification among Languages
May 03, 2023
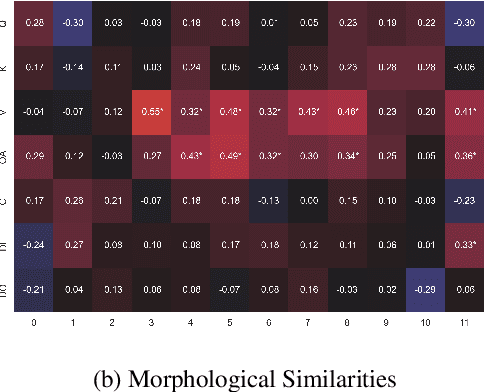
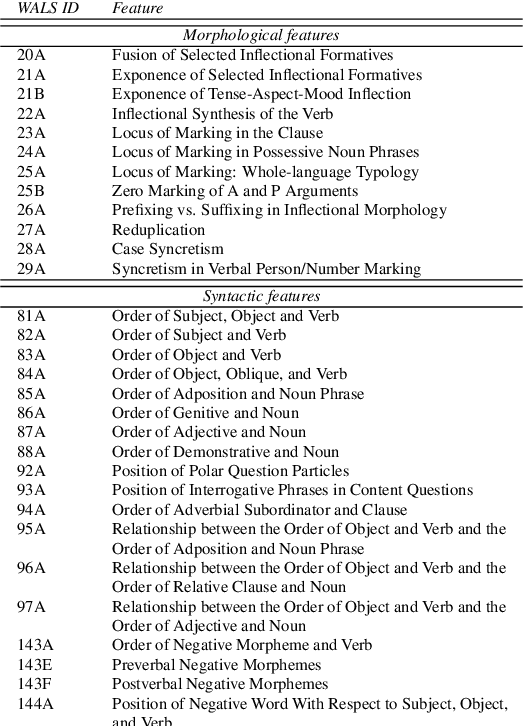
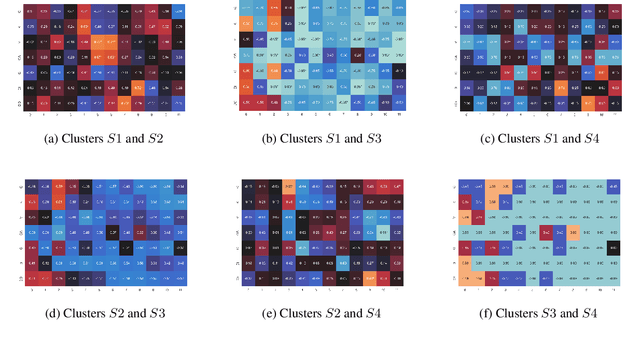
The overwhelming success of transformers is a real conundrum stimulating a compelling question: are these machines replicating some traditional linguistic models or discovering radically new theories? In this paper, we propose a novel standpoint to investigate this important question. Using typological similarities among languages, we aim to layer-wise compare transformers for different languages to observe whether these similarities emerge for particular layers. For this investigation, we propose to use Centered kernel alignment to measure similarity among weight matrices. We discovered that syntactic typological similarity is consistent with the similarity among weights in the middle layers. This finding confirms results obtained by syntactically probing BERT and, thus, gives an important confirmation that BERT is replicating traditional linguistic models.