 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstract Activation Spaces for Content-Invariant Reasoning in Large Language Models
Feb 02, 2026Large Language Models (LLMs) often struggle with deductive judgment in syllogistic reasoning, systematically conflating semantic plausibility with formal validity a phenomenon known as content effect. This bias persists even when models generate step-wise explanations, indicating that intermediate rationales may inherit the same semantic shortcuts that affect answers. Recent approaches propose mitigating this issue by increasing inference-time structural constraints, either by encouraging abstract intermediate representations or by intervening directly in the model's internal computations; however, reliably suppressing semantic interference remains an open challenge. To make formal deduction less sensitive to semantic content, we introduce a framework for abstraction-guided reasoning that explicitly separates structural inference from lexical semantics. We construct paired content-laden and abstract syllogisms and use the model's activations on abstract inputs to define an abstract reasoning space. We then learn lightweight Abstractors that, from content-conditioned residual-stream states, predict representations aligned with this space and integrate these predictions via multi-layer interventions during the forward pass. Using cross-lingual transfer as a test bed, we show that abstraction-aligned steering reduces content-driven errors and improves validity-sensitive performance. Our results position activation-level abstraction as a scalable mechanism for enhancing the robustness of formal reasoning in LLMs against semantic interference.
Protoknowledge Shapes Behaviour of LLMs in Downstream Tasks: Memorization and Generalization with Knowledge Graphs
May 21, 2025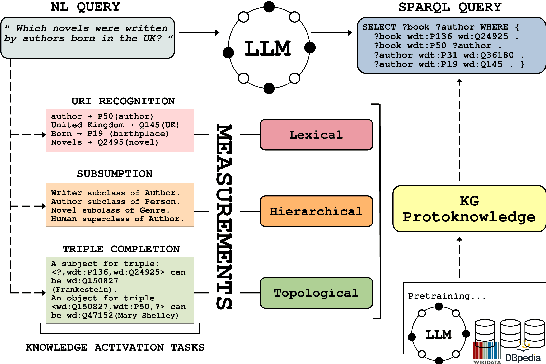



We introduce the concept of protoknowledge to formalize and measure how sequences of tokens encoding Knowledge Graphs are internalized during pretraining and utilized at inference time by Large Language Models (LLMs). Indeed, LLMs have demonstrated the ability to memorize vast amounts of token sequences during pretraining, and a central open question is how they leverage this memorization as reusable knowledge through generalization. We then categorize protoknowledge into lexical, hierarchical, and topological forms, varying on the type of knowledge that needs to be activated. We measure protoknowledge through Knowledge Activation Tasks (KATs), analyzing its general properties such as semantic bias. We then investigate the impact of protoknowledge on Text-to-SPARQL performance by varying prompting strategies depending on input conditions. To this end, we adopt a novel analysis framework that assesses whether model predictions align with the successful activation of the relevant protoknowledge for each query. This methodology provides a practical tool to explore Semantic-Level Data Contamination and serves as an effective strategy for Closed-Pretraining models.
Improving Multilingual Retrieval-Augmented Language Models through Dialectic Reasoning Argumentations
Apr 07, 2025Retrieval-augmented generation (RAG) is key to enhancing large language models (LLMs) to systematically access richer factual knowledge. Yet, using RAG brings intrinsic challenges, as LLMs must deal with potentially conflicting knowledge, especially in multilingual retrieval, where the heterogeneity of knowledge retrieved may deliver different outlooks. To make RAG more analytical, critical and grounded, we introduce Dialectic-RAG (DRAG), a modular approach guided by Argumentative Explanations, i.e., structured reasoning process that systematically evaluates retrieved information by comparing, contrasting, and resolving conflicting perspectives. Given a query and a set of multilingual related documents, DRAG selects and exemplifies relevant knowledge for delivering dialectic explanations that, by critically weighing opposing arguments and filtering extraneous content, clearly determine the final response. Through a series of in-depth experiments, we show the impact of our framework both as an in-context learning strategy and for constructing demonstrations to instruct smaller models. The final results demonstrate that DRAG significantly improves RAG approaches, requiring low-impact computational effort and providing robustness to knowledge perturbations.
Multilingual Retrieval-Augmented Generation for Knowledge-Intensive Task
Apr 04, 2025Retrieval-augmented generation (RAG) has become a cornerstone of contemporary NLP, enhancing large language models (LLMs) by allowing them to access richer factual contexts through in-context retrieval. While effective in monolingual settings, especially in English, its use in multilingual tasks remains unexplored. This paper investigates the effectiveness of RAG across multiple languages by proposing novel approaches for multilingual open-domain question-answering. We evaluate the performance of various multilingual RAG strategies, including question-translation (tRAG), which translates questions into English before retrieval, and Multilingual RAG (MultiRAG), where retrieval occurs directly across multiple languages. Our findings reveal that tRAG, while useful, suffers from limited coverage. In contrast, MultiRAG improves efficiency by enabling multilingual retrieval but introduces inconsistencies due to cross-lingual variations in the retrieved content. To address these issues, we propose Crosslingual RAG (CrossRAG), a method that translates retrieved documents into a common language (e.g., English) before generating the response. Our experiments show that CrossRAG significantly enhances performance on knowledge-intensive tasks, benefiting both high-resource and low-resource languages.
Improving Chain-of-Thought Reasoning via Quasi-Symbolic Abstractions
Feb 18, 2025Chain-of-Though (CoT) represents a common strategy for reasoning in Large Language Models (LLMs) by decomposing complex tasks into intermediate inference steps. However, explanations generated via CoT are susceptible to content biases that negatively affect their robustness and faithfulness. To mitigate existing limitations, recent work has proposed using logical formalisms coupled with external symbolic solvers. However, fully symbolic approaches possess the bottleneck of requiring a complete translation from natural language to formal languages, a process that affects efficiency and flexibility. To achieve a trade-off, this paper investigates methods to disentangle content from logical reasoning without a complete formalisation. In particular, we present QuaSAR (for Quasi-Symbolic Abstract Reasoning), a variation of CoT that guides LLMs to operate at a higher level of abstraction via quasi-symbolic explanations. Our framework leverages the capability of LLMs to formalise only relevant variables and predicates, enabling the coexistence of symbolic elements with natural language. We show the impact of QuaSAR for in-context learning and for constructing demonstrations to improve the reasoning capabilities of smaller models. Our experiments show that quasi-symbolic abstractions can improve CoT-based methods by up to 8% accuracy, enhancing robustness and consistency on challenging adversarial variations on both natural language (i.e. MMLU-Redux) and symbolic reasoning tasks (i.e., GSM-Symbolic).
MeMo: Towards Language Models with Associative Memory Mechanisms
Feb 18, 2025



Memorization is a fundamental ability of Transformer-based Large Language Models, achieved through learning. In this paper, we propose a paradigm shift by designing an architecture to memorize text directly, bearing in mind the principle that memorization precedes learning. We introduce MeMo, a novel architecture for language modeling that explicitly memorizes sequences of tokens in layered associative memories. By design, MeMo offers transparency and the possibility of model editing, including forgetting texts. We experimented with the MeMo architecture, showing the memorization power of the one-layer and the multi-layer configurations.
Eliciting Critical Reasoning in Retrieval-Augmented Language Models via Contrastive Explanations
Oct 30, 2024



Retrieval-augmented generation (RAG) has emerged as a critical mechanism in contemporary NLP to support Large Language Models(LLMs) in systematically accessing richer factual context. However, the integration of RAG mechanisms brings its inherent challenges, as LLMs need to deal with potentially noisy contexts. Recent studies have shown that LLMs still struggle to critically analyse RAG-based in-context information, a limitation that may lead to incorrect inferences and hallucinations. In this paper, we investigate how to elicit critical reasoning in RAG via contrastive explanations. In particular, we propose Contrastive-RAG (C-RAG), a framework that (i) retrieves relevant documents given a query, (ii) selects and exemplifies relevant passages, and (iii) generates explanations that explicitly contrast the relevance of the passages to (iv) support the final answer. We show the impact of C-RAG building contrastive reasoning demonstrations from LLMs to instruct smaller models for retrieval-augmented tasks. Extensive experiments demonstrate that C-RAG improves state-of-the-art RAG models while (a) requiring significantly fewer prompts and demonstrations and (b) being robust to perturbations in the retrieved documents.
Animate, or Inanimate, That is the Question for Large Language Models
Aug 12, 2024The cognitive essence of humans is deeply intertwined with the concept of animacy, which plays an essential role in shaping their memory, vision, and multi-layered language understanding. Although animacy appears in language via nuanced constraints on verbs and adjectives, it is also learned and refined through extralinguistic information. Similarly, we assume that the LLMs' limited abilities to understand natural language when processing animacy are motivated by the fact that these models are trained exclusively on text. Hence, the question this paper aims to answer arises: can LLMs, in their digital wisdom, process animacy in a similar way to what humans would do? We then propose a systematic analysis via prompting approaches. In particular, we probe different LLMs by prompting them using animate, inanimate, usual, and stranger contexts. Results reveal that, although LLMs have been trained predominantly on textual data, they exhibit human-like behavior when faced with typical animate and inanimate entities in alignment with earlier studies. Hence, LLMs can adapt to understand unconventional situations by recognizing oddities as animated without needing to interface with unspoken cognitive triggers humans rely on to break down animations.
Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
May 01, 2024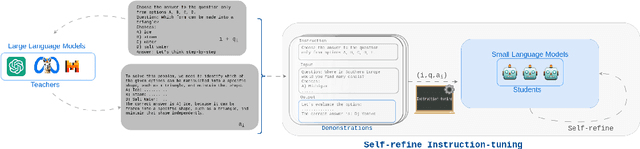
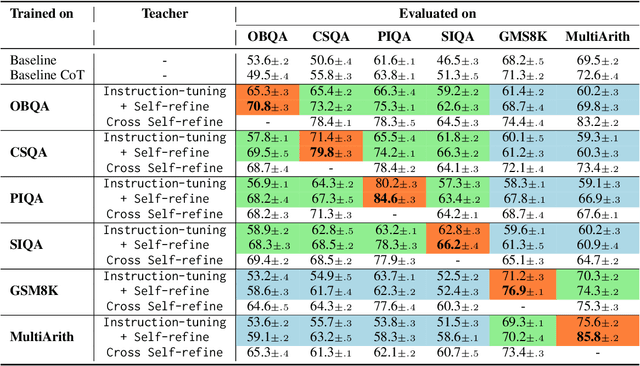
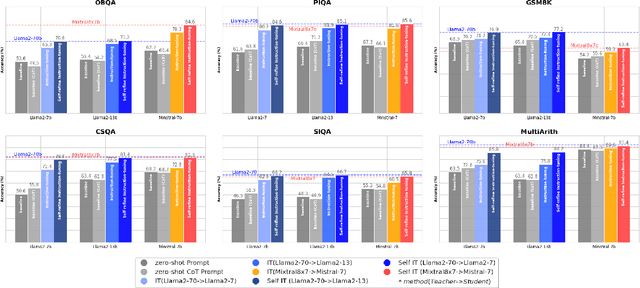

The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.
Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL Translation
Feb 12, 2024



Understanding textual description to generate code seems to be an achieved capability of instruction-following Large Language Models (LLMs) in zero-shot scenario. However, there is a severe possibility that this translation ability may be influenced by having seen target textual descriptions and the related code. This effect is known as Data Contamination. In this study, we investigate the impact of Data Contamination on the performance of GPT-3.5 in the Text-to-SQL code-generating tasks. Hence, we introduce a novel method to detect Data Contamination in GPTs and examine GPT-3.5's Text-to-SQL performances using the known Spider Dataset and our new unfamiliar dataset Termite. Furthermore, we analyze GPT-3.5's efficacy on databases with modified information via an adversarial table disconnection (ATD) approach, complicating Text-to-SQL tasks by removing structural pieces of information from the database. Our results indicate a significant performance drop in GPT-3.5 on the unfamiliar Termite dataset, even with ATD modifications, highlighting the effect of Data Contamination on LLMs in Text-to-SQL translation tasks.