 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFood Noise & False Safety: A Systematic Evaluation of How LLMs Fail to Adapt to Eating Disorder Queries with Clinician Feedback
Jun 01, 2026Recent evidence shows that people with eating disorders (EDs) are increasingly seeking guidance, advice, and emotional support from Large Language Model (LLM)-based chat systems. Although these systems are not designed to provide clinical advice, their perceived expertise, neutrality and accessibility make them a frequent, albeit risky, source of support. This paper investigates potential patterns of interaction between users with EDs and LLMs, focusing on the potential harms arising from models that uncritically adapt to, and facilitate unsafe or self-harming user requests. We find, in consultation with clinical ED experts, that specific linguistic cues in prompts increase the likelihood of unsafe responses and, through systematically varying the degree of potential risk present in the user prompt, report the extent to which LLMs uncritically adapt to problematic, and potentially dangerous user inputs.
Animate, or Inanimate, That is the Question for Large Language Models
Aug 12, 2024The cognitive essence of humans is deeply intertwined with the concept of animacy, which plays an essential role in shaping their memory, vision, and multi-layered language understanding. Although animacy appears in language via nuanced constraints on verbs and adjectives, it is also learned and refined through extralinguistic information. Similarly, we assume that the LLMs' limited abilities to understand natural language when processing animacy are motivated by the fact that these models are trained exclusively on text. Hence, the question this paper aims to answer arises: can LLMs, in their digital wisdom, process animacy in a similar way to what humans would do? We then propose a systematic analysis via prompting approaches. In particular, we probe different LLMs by prompting them using animate, inanimate, usual, and stranger contexts. Results reveal that, although LLMs have been trained predominantly on textual data, they exhibit human-like behavior when faced with typical animate and inanimate entities in alignment with earlier studies. Hence, LLMs can adapt to understand unconventional situations by recognizing oddities as animated without needing to interface with unspoken cognitive triggers humans rely on to break down animations.
When Large Language Models contradict humans? Large Language Models' Sycophantic Behaviour
Nov 15, 2023



Large Language Models (LLMs) have been demonstrating the ability to solve complex tasks by delivering answers that are positively evaluated by humans due in part to the intensive use of human feedback that refines responses. However, the suggestibility transmitted through human feedback increases the inclination to produce responses that correspond to the user's beliefs or misleading prompts as opposed to true facts, a behaviour known as sycophancy. This phenomenon decreases the bias, robustness, and, consequently, their reliability. In this paper, we shed light on the suggestibility of LLMs to sycophantic behaviour, demonstrating these tendencies via human-influenced prompts over different tasks. Our investigation reveals that LLMs show sycophantic tendencies when responding to queries involving subjective opinions and statements that should elicit a contrary response based on facts, demonstrating a lack of robustness.
Empowering Cross-lingual Abilities of Instruction-tuned Large Language Models by Translation-following demonstrations
Aug 27, 2023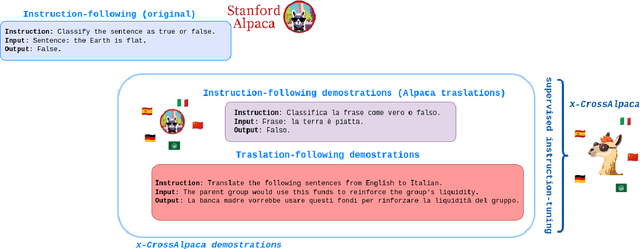
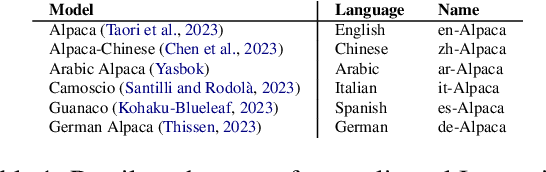
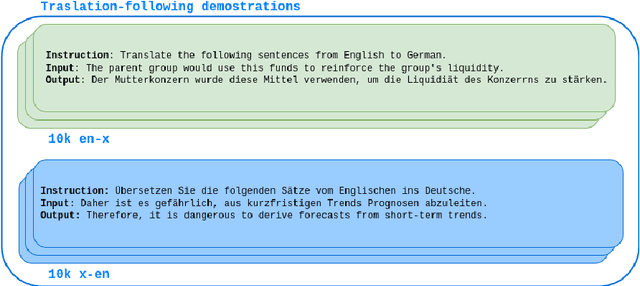
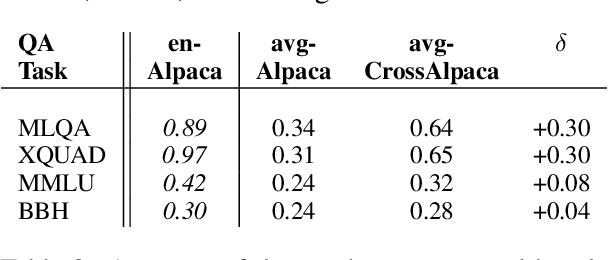
The language ability of Large Language Models (LLMs) is often unbalanced towards English because of the imbalance in the distribution of the pre-training data. This disparity is demanded in further fine-tuning and affecting the cross-lingual abilities of LLMs. In this paper, we propose to empower Instructiontuned LLMs (It-LLMs) in languages other than English by building semantic alignment between them. Hence, we propose CrossAlpaca, an It-LLM with cross-lingual instruction-following and Translation-following demonstrations to improve semantic alignment between languages. We validate our approach on the multilingual Question Answering (QA) benchmarks XQUAD and MLQA and adapted versions of MMLU and BBH. Our models, tested over six different languages, outperform the It-LLMs tuned on monolingual data. The final results show that instruction tuning on non-English data is not enough and that semantic alignment can be further improved by Translation-following demonstrations.