 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciR: A Controllable Benchmark for Scientific Reasoning in LLMs
Jun 11, 2026Three paradigmatic forms of inference recur across scientific reasoning: deduction, induction, and causal abduction. Reliably evaluating LLMs on these in scientific settings is currently out of reach: scientific benchmarks built on human annotations are costly and lack mechanistic ground truth, while synthetic logical-reasoning benchmarks do not resemble real scientific documents. We introduce SciR, a benchmark that combines multi-paradigm reasoning with controllable scientific rendering, anchored on three paradigmatic scientific problems. Tasks are generated from formal objects (deduction tree, inductive rule hypothesis, causal graph) to guarantee verifiable answers, then rendered into multi-document scientific discourse via per-track domain-tuned genres. The construction lets us independently vary two difficulty axes: how hard it is to extract the key information needed for inference, and how hard the principled inference itself is. We test six models. Both axes hurt every model, and their effects compound. The rendering even hurts neurosymbolic pipelines, which hand inference to a verified solver. The two axes yield a per-model extraction-vs-inference profile: for instance, reasoning models like deepseek-r1 mostly surpass non-reasoning instruct models on the inference axis. To our knowledge, SciR is the first multi-paradigm scientific-reasoning benchmark with parametric control on both extraction and inference difficulty.
Principles of Concept Representation in Sentence Encoders
Jun 05, 2026What makes a sentence encoder produce good concept representations? We approach this through the lens of representational compositionality: an encoder supports a concept family only when its latent space admits a low-distortion realization of the corresponding semantic operator. This framing predicts both where current encoders succeed and where they are structurally mismatched to their supervision. Through a controlled ablation over encoder conditions trained on 3.3 million synonym and definition pairs from WordNet and Wiktionary, evaluated on three decontaminated splits and a modifier-labeled noun-phrase benchmark, we identify four principles. Fine-tuning recalibrates the latent geometry rather than expanding it (P1). Semantic signal concentrates in the final transformer layer before concept-specific training begins, making cross-layer pooling redundant (P2). Hard negatives improve discrimination and stress-test robustness without improving retrieval ranking, showing that calibration and ranking are independently addressable (P3). Finally, the effectiveness of supervision depends on the composition type of the target concept. Extensional training helps intersective and subsective families while degrading relational and intensional ones, exposing a structural limitation of current training paradigms (P4). We release two new evaluation datasets: a DBpedia semantic-gap benchmark and a modifier-labeled NP paraphrase suite.
From Circuit Evidence to Mechanistic Theory: An Inductive Logic Approach
May 20, 2026Mechanistic interpretability produces circuit-level causal analyses of neural network behaviour, but discovered circuits often remain isolated experimental artefacts: there is no shared formal representation for what circuits compute, how they relate, or when two findings provide evidence for the same mechanism. This work provides a formal infrastructure for cumulative mechanistic science by treating circuit interpretation as inductive theory construction. Each circuit is characterised at two levels: a Causal Functional Signature (CFS), which grounds component behaviour in causal attribution evidence and token role profiles, and an architectural signature $τ_{\mathrm{arch}}$, learned by inductive logic programming (ILP) from scale-invariant structural predicates. Together, these constitute a formal coherence layer that makes mechanistic claims explicit, comparable via $θ$-subsumption, and portable across model scales. CFS reveals qualitatively distinct computational strategies across task types, including attention-mediated copying versus MLP-mediated binding. ILP signatures achieve substantially better structural separation than graph kernel and feature-vector baselines, and support principled transfer across model scales and architecture families.
FormalScience: Scalable Human-in-the-Loop Autoformalisation of Science with Agentic Code Generation in Lean
Apr 24, 2026Formalising informal mathematical reasoning into formally verifiable code is a significant challenge for large language models. In scientific fields such as physics, domain-specific machinery (\textit{e.g.} Dirac notation, vector calculus) imposes additional formalisation challenges that modern LLMs and agentic approaches have yet to tackle. To aid autoformalisation in scientific domains, we present FormalScience; a domain-agnostic human-in-the-loop agentic pipeline that enables a single domain expert (without deep formal language experience) to produce \textit{syntactically correct} and \textit{semantically aligned} formal proofs of informal reasoning for low economic cost. Applying FormalScience to physics, we construct FormalPhysics, a dataset of 200 university-level (LaTeX) physics problems and solutions (primarily quantum mechanics and electromagnetism), along with their Lean4 formal representations. Compared to existing formal math benchmarks, FormalPhysics achieves perfect formal validity and exhibits greater statement complexity. We evaluate open-source models and proprietary systems on a statement autoformalisation task on our dataset via zero-shot prompting, self-refinement with error feedback, and a novel multi-stage agentic approach, and explore autoformalisation limitations in modern LLM-based approaches. We provide the first systematic characterisation of semantic drift in physics autoformalisation in terms of concepts such as notational collapse and abstraction elevation which reveals what formal language verifies when full semantic preservation is unattainable. We release the codebase together with an interactive UI-based FormalScience system which facilitates autoformalisation and theorem proving in scientific domains beyond physics.https://github.com/jmeadows17/formal-science
Beyond Gold Standards: Epistemic Ensemble of LLM Judges for Formal Mathematical Reasoning
Jun 12, 2025Autoformalization plays a crucial role in formal mathematical reasoning by enabling the automatic translation of natural language statements into formal languages. While recent advances using large language models (LLMs) have shown promising results, methods for automatically evaluating autoformalization remain underexplored. As one moves to more complex domains (e.g., advanced mathematics), human evaluation requires significant time and domain expertise, especially as the complexity of the underlying statements and background knowledge increases. LLM-as-a-judge presents a promising approach for automating such evaluation. However, existing methods typically employ coarse-grained and generic evaluation criteria, which limit their effectiveness for advanced formal mathematical reasoning, where quality hinges on nuanced, multi-granular dimensions. In this work, we take a step toward addressing this gap by introducing a systematic, automatic method to evaluate autoformalization tasks. The proposed method is based on an epistemically and formally grounded ensemble (EFG) of LLM judges, defined on criteria encompassing logical preservation (LP), mathematical consistency (MC), formal validity (FV), and formal quality (FQ), resulting in a transparent assessment that accounts for different contributing factors. We validate the proposed framework to serve as a proxy for autoformalization assessment within the domain of formal mathematics. Overall, our experiments demonstrate that the EFG ensemble of LLM judges is a suitable emerging proxy for evaluation, more strongly correlating with human assessments than a coarse-grained model, especially when assessing formal qualities. These findings suggest that LLM-as-judges, especially when guided by a well-defined set of atomic properties, could offer a scalable, interpretable, and reliable support for evaluating formal mathematical reasoning.
Formalizing Complex Mathematical Statements with LLMs: A Study on Mathematical Definitions
Feb 17, 2025


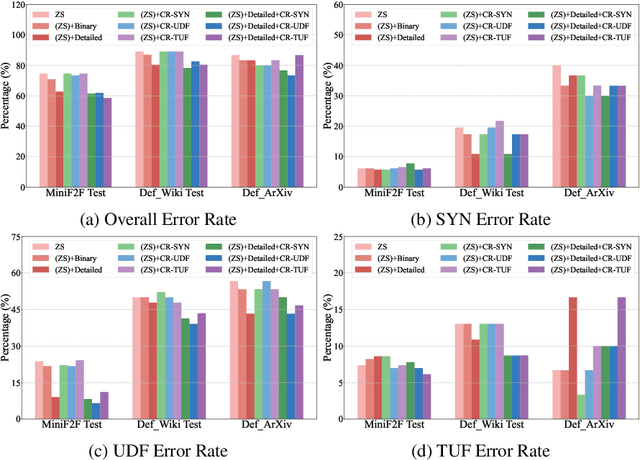
Thanks to their linguistic capabilities, LLMs offer an opportunity to bridge the gap between informal mathematics and formal languages through autoformalization. However, it is still unclear how well LLMs generalize to sophisticated and naturally occurring mathematical statements. To address this gap, we investigate the task of autoformalizing real-world mathematical definitions -- a critical component of mathematical discourse. Specifically, we introduce two novel resources for autoformalisation, collecting definitions from Wikipedia (Def_Wiki) and arXiv papers (Def_ArXiv). We then systematically evaluate a range of LLMs, analyzing their ability to formalize definitions into Isabelle/HOL. Furthermore, we investigate strategies to enhance LLMs' performance including refinement through external feedback from Proof Assistants, and formal definition grounding, where we guide LLMs through relevant contextual elements from formal mathematical libraries. Our findings reveal that definitions present a greater challenge compared to existing benchmarks, such as miniF2F. In particular, we found that LLMs still struggle with self-correction, and aligning with relevant mathematical libraries. At the same time, structured refinement methods and definition grounding strategies yield notable improvements of up to 16% on self-correction capabilities and 43% on the reduction of undefined errors, highlighting promising directions for enhancing LLM-based autoformalization in real-world scenarios.
Integrating Expert Knowledge into Logical Programs via LLMs
Feb 17, 2025This paper introduces ExKLoP, a novel framework designed to evaluate how effectively Large Language Models (LLMs) integrate expert knowledge into logical reasoning systems. This capability is especially valuable in engineering, where expert knowledge-such as manufacturer-recommended operational ranges-can be directly embedded into automated monitoring systems. By mirroring expert verification steps, tasks like range checking and constraint validation help ensure system safety and reliability. Our approach systematically evaluates LLM-generated logical rules, assessing both syntactic fluency and logical correctness in these critical validation tasks. We also explore the models capacity for self-correction via an iterative feedback loop based on code execution outcomes. ExKLoP presents an extensible dataset comprising 130 engineering premises, 950 prompts, and corresponding validation points. It enables comprehensive benchmarking while allowing control over task complexity and scalability of experiments. We leverage the synthetic data creation methodology to conduct extensive empirical evaluation on a diverse set of LLMs including Llama3, Gemma, Mixtral, Mistral, and Qwen. Results reveal that while models generate nearly perfect syntactically correct code, they frequently exhibit logical errors in translating expert knowledge. Furthermore, iterative self-correction yields only marginal improvements (up to 3%). Overall, ExKLoP serves as a robust evaluation platform that streamlines the selection of effective models for self-correcting systems while clearly delineating the types of errors encountered. The complete implementation, along with all relevant data, is available at GitHub.
Diffusion Twigs with Loop Guidance for Conditional Graph Generation
Oct 31, 2024



We introduce a novel score-based diffusion framework named Twigs that incorporates multiple co-evolving flows for enriching conditional generation tasks. Specifically, a central or trunk diffusion process is associated with a primary variable (e.g., graph structure), and additional offshoot or stem processes are dedicated to dependent variables (e.g., graph properties or labels). A new strategy, which we call loop guidance, effectively orchestrates the flow of information between the trunk and the stem processes during sampling. This approach allows us to uncover intricate interactions and dependencies, and unlock new generative capabilities. We provide extensive experiments to demonstrate strong performance gains of the proposed method over contemporary baselines in the context of conditional graph generation, underscoring the potential of Twigs in challenging generative tasks such as inverse molecular design and molecular optimization.
SylloBio-NLI: Evaluating Large Language Models on Biomedical Syllogistic Reasoning
Oct 18, 2024



Syllogistic reasoning is crucial for Natural Language Inference (NLI). This capability is particularly significant in specialized domains such as biomedicine, where it can support automatic evidence interpretation and scientific discovery. This paper presents SylloBio-NLI, a novel framework that leverages external ontologies to systematically instantiate diverse syllogistic arguments for biomedical NLI. We employ SylloBio-NLI to evaluate Large Language Models (LLMs) on identifying valid conclusions and extracting supporting evidence across 28 syllogistic schemes instantiated with human genome pathways. Extensive experiments reveal that biomedical syllogistic reasoning is particularly challenging for zero-shot LLMs, which achieve an average accuracy between 70% on generalized modus ponens and 23% on disjunctive syllogism. At the same time, we found that few-shot prompting can boost the performance of different LLMs, including Gemma (+14%) and LLama-3 (+43%). However, a deeper analysis shows that both techniques exhibit high sensitivity to superficial lexical variations, highlighting a dependency between reliability, models' architecture, and pre-training regime. Overall, our results indicate that, while in-context examples have the potential to elicit syllogistic reasoning in LLMs, existing models are still far from achieving the robustness and consistency required for safe biomedical NLI applications.
Graph Neural Flows for Unveiling Systemic Interactions Among Irregularly Sampled Time Series
Oct 17, 2024



Interacting systems are prevalent in nature. It is challenging to accurately predict the dynamics of the system if its constituent components are analyzed independently. We develop a graph-based model that unveils the systemic interactions of time series observed at irregular time points, by using a directed acyclic graph to model the conditional dependencies (a form of causal notation) of the system components and learning this graph in tandem with a continuous-time model that parameterizes the solution curves of ordinary differential equations (ODEs). Our technique, a graph neural flow, leads to substantial enhancements over non-graph-based methods, as well as graph-based methods without the modeling of conditional dependencies. We validate our approach on several tasks, including time series classification and forecasting, to demonstrate its efficacy.