 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Navigational Approach for Comprehensive RAG via Traversal over Proposition Graphs
Jan 08, 2026Standard RAG pipelines based on chunking excel at simple factual retrieval but fail on complex multi-hop queries due to a lack of structural connectivity. Conversely, initial strategies that interleave retrieval with reasoning often lack global corpus awareness, while Knowledge Graph (KG)-based RAG performs strongly on complex multi-hop tasks but suffers on fact-oriented single-hop queries. To bridge this gap, we propose a novel RAG framework: ToPG (Traversal over Proposition Graphs). ToPG models its knowledge base as a heterogeneous graph of propositions, entities, and passages, effectively combining the granular fact density of propositions with graph connectivity. We leverage this structure using iterative Suggestion-Selection cycles, where the Suggestion phase enables a query-aware traversal of the graph, and the Selection phase provides LLM feedback to prune irrelevant propositions and seed the next iteration. Evaluated on three distinct QA tasks (Simple, Complex, and Abstract QA), ToPG demonstrates strong performance across both accuracy- and quality-based metrics. Overall, ToPG shows that query-aware graph traversal combined with factual granularity is a critical component for efficient structured RAG systems. ToPG is available at https://github.com/idiap/ToPG.
Accelerating Antibiotic Discovery with Large Language Models and Knowledge Graphs
Mar 20, 2025The discovery of novel antibiotics is critical to address the growing antimicrobial resistance (AMR). However, pharmaceutical industries face high costs (over $1 billion), long timelines, and a high failure rate, worsened by the rediscovery of known compounds. We propose an LLM-based pipeline that acts as an alarm system, detecting prior evidence of antibiotic activity to prevent costly rediscoveries. The system integrates organism and chemical literature into a Knowledge Graph (KG), ensuring taxonomic resolution, synonym handling, and multi-level evidence classification. We tested the pipeline on a private list of 73 potential antibiotic-producing organisms, disclosing 12 negative hits for evaluation. The results highlight the effectiveness of the pipeline for evidence reviewing, reducing false negatives, and accelerating decision-making. The KG for negative hits and the user interface for interactive exploration will be made publicly available.
An LLM-based Knowledge Synthesis and Scientific Reasoning Framework for Biomedical Discovery
Jun 26, 2024
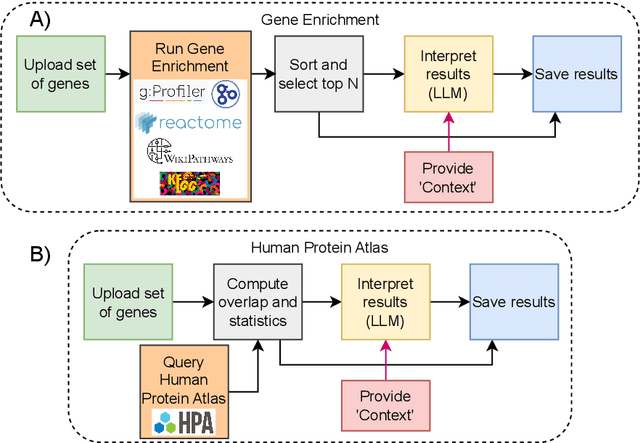
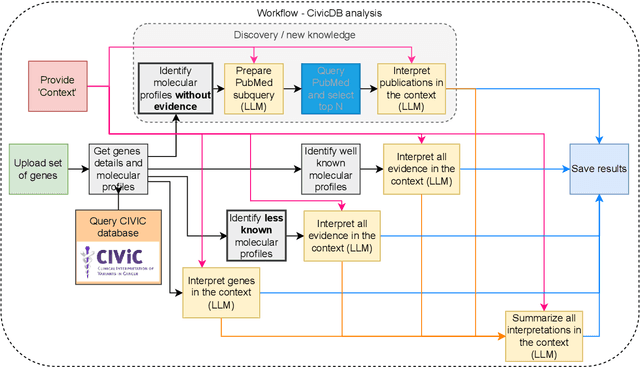
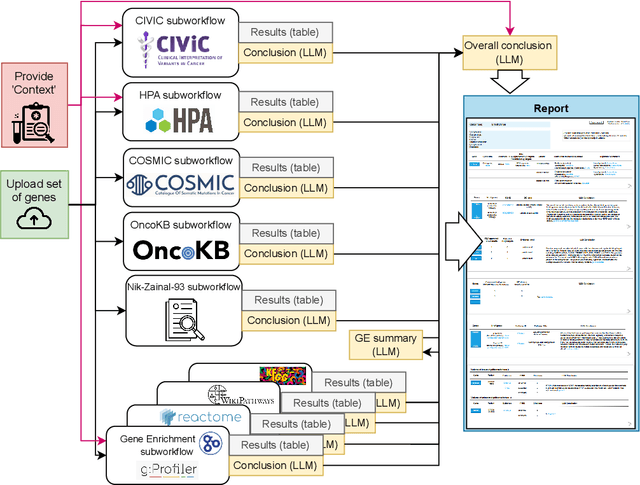
We present BioLunar, developed using the Lunar framework, as a tool for supporting biological analyses, with a particular emphasis on molecular-level evidence enrichment for biomarker discovery in oncology. The platform integrates Large Language Models (LLMs) to facilitate complex scientific reasoning across distributed evidence spaces, enhancing the capability for harmonizing and reasoning over heterogeneous data sources. Demonstrating its utility in cancer research, BioLunar leverages modular design, reusable data access and data analysis components, and a low-code user interface, enabling researchers of all programming levels to construct LLM-enabled scientific workflows. By facilitating automatic scientific discovery and inference from heterogeneous evidence, BioLunar exemplifies the potential of the integration between LLMs, specialised databases and biomedical tools to support expert-level knowledge synthesis and discovery.
Relation Extraction in underexplored biomedical domains: A diversity-optimised sampling and synthetic data generation approach
Nov 10, 2023The sparsity of labelled data is an obstacle to the development of Relation Extraction models and the completion of databases in various biomedical areas. While being of high interest in drug-discovery, the natural-products literature, reporting the identification of potential bioactive compounds from organisms, is a concrete example of such an overlooked topic. To mark the start of this new task, we created the first curated evaluation dataset and extracted literature items from the LOTUS database to build training sets. To this end, we developed a new sampler inspired by diversity metrics in ecology, named Greedy Maximum Entropy sampler, or GME-sampler (https://github.com/idiap/gme-sampler). The strategic optimization of both balance and diversity of the selected items in the evaluation set is important given the resource-intensive nature of manual curation. After quantifying the noise in the training set, in the form of discrepancies between the input abstracts text and the expected output labels, we explored different strategies accordingly. Framing the task as an end-to-end Relation Extraction, we evaluated the performance of standard fine-tuning as a generative task and few-shot learning with open Large Language Models (LLaMA 7B-65B). In addition to their evaluation in few-shot settings, we explore the potential of open Large Language Models (Vicuna-13B) as synthetic data generator and propose a new workflow for this purpose. All evaluated models exhibited substantial improvements when fine-tuned on synthetic abstracts rather than the original noisy data. We provide our best performing (f1-score=59.0) BioGPT-Large model for end-to-end RE of natural-products relationships along with all the generated synthetic data and the evaluation dataset. See more details at https://github.com/idiap/abroad-re.
Large Language Models, scientific knowledge and factuality: A systematic analysis in antibiotic discovery
May 28, 2023Inferring over and extracting information from Large Language Models (LLMs) trained on a large corpus of scientific literature can potentially drive a new era in biomedical research, reducing the barriers for accessing existing medical evidence. This work examines the potential of LLMs for dialoguing with biomedical background knowledge, using the context of antibiotic discovery as an exemplar motivational scenario. The context of biomedical discovery from natural products entails understanding the relational evidence between an organism, an associated chemical and its associated antibiotic properties. We provide a systematic assessment on the ability of LLMs to encode and express these relations, verifying for fluency, prompt-alignment, semantic coherence, factual knowledge and specificity of generated responses. The systematic analysis is applied to nine state-of-the-art models (including ChatGPT and GPT-4) in two prompting-based tasks: chemical compound definition generation and chemical compound-fungus relation determination. Results show that while recent models have improved in fluency, factual accuracy is still low and models are biased towards over-represented entities. The ability of LLMs to serve as biomedical knowledge bases is questioned, and the need for additional systematic evaluation frameworks is highlighted. The best performing GPT-4 produced a factual definition for 70% of chemical compounds and 43.6% factual relations to fungi, whereas the best open source model BioGPT-large 30% of the compounds and 30% of the relations for the best-performing prompt. The results show that while LLMs are currently not fit for purpose to be used as biomedical factual knowledge bases, there is a promising emerging property in the direction of factuality as the models become domain specialised, scale-up in size and level of human feedback.