 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Twigs with Loop Guidance for Conditional Graph Generation
Oct 31, 2024



We introduce a novel score-based diffusion framework named Twigs that incorporates multiple co-evolving flows for enriching conditional generation tasks. Specifically, a central or trunk diffusion process is associated with a primary variable (e.g., graph structure), and additional offshoot or stem processes are dedicated to dependent variables (e.g., graph properties or labels). A new strategy, which we call loop guidance, effectively orchestrates the flow of information between the trunk and the stem processes during sampling. This approach allows us to uncover intricate interactions and dependencies, and unlock new generative capabilities. We provide extensive experiments to demonstrate strong performance gains of the proposed method over contemporary baselines in the context of conditional graph generation, underscoring the potential of Twigs in challenging generative tasks such as inverse molecular design and molecular optimization.
Graph Neural Flows for Unveiling Systemic Interactions Among Irregularly Sampled Time Series
Oct 17, 2024Interacting systems are prevalent in nature. It is challenging to accurately predict the dynamics of the system if its constituent components are analyzed independently. We develop a graph-based model that unveils the systemic interactions of time series observed at irregular time points, by using a directed acyclic graph to model the conditional dependencies (a form of causal notation) of the system components and learning this graph in tandem with a continuous-time model that parameterizes the solution curves of ordinary differential equations (ODEs). Our technique, a graph neural flow, leads to substantial enhancements over non-graph-based methods, as well as graph-based methods without the modeling of conditional dependencies. We validate our approach on several tasks, including time series classification and forecasting, to demonstrate its efficacy.
MING: A Functional Approach to Learning Molecular Generative Models
Oct 16, 2024



Traditional molecule generation methods often rely on sequence or graph-based representations, which can limit their expressive power or require complex permutation-equivariant architectures. This paper introduces a novel paradigm for learning molecule generative models based on functional representations. Specifically, we propose Molecular Implicit Neural Generation (MING), a diffusion-based model that learns molecular distributions in function space. Unlike standard diffusion processes in data space, MING employs a novel functional denoising probabilistic process, which jointly denoises the information in both the function's input and output spaces by leveraging an expectation-maximization procedure for latent implicit neural representations of data. This approach allows for a simple yet effective model design that accurately captures underlying function distributions. Experimental results on molecule-related datasets demonstrate MING's superior performance and ability to generate plausible molecular samples, surpassing state-of-the-art data-space methods while offering a more streamlined architecture and significantly faster generation times.
Learning Disentangled Representations for Natural Language Definitions
Sep 22, 2022



Disentangling the encodings of neural models is a fundamental aspect for improving interpretability, semantic control and downstream task performance in Natural Language Processing. Currently, most disentanglement methods are unsupervised or rely on synthetic datasets with known generative factors. We argue that recurrent syntactic and semantic regularities in textual data can be used to provide the models with both structural biases and generative factors. We leverage the semantic structures present in a representative and semantically dense category of sentence types, definitional sentences, for training a Variational Autoencoder to learn disentangled representations. Our experimental results show that the proposed model outperforms unsupervised baselines on several qualitative and quantitative benchmarks for disentanglement, and it also improves the results in the downstream task of definition modeling.
Disentangling Generative Factors in Natural Language with Discrete Variational Autoencoders
Sep 15, 2021

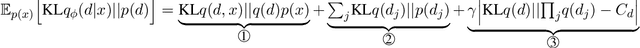

The ability of learning disentangled representations represents a major step for interpretable NLP systems as it allows latent linguistic features to be controlled. Most approaches to disentanglement rely on continuous variables, both for images and text. We argue that despite being suitable for image datasets, continuous variables may not be ideal to model features of textual data, due to the fact that most generative factors in text are discrete. We propose a Variational Autoencoder based method which models language features as discrete variables and encourages independence between variables for learning disentangled representations. The proposed model outperforms continuous and discrete baselines on several qualitative and quantitative benchmarks for disentanglement as well as on a text style transfer downstream application.