 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Eval: Agentic and Automated Evaluation for Embodied Brain
Feb 02, 2026Current embodied VLM evaluation relies on static, expert-defined, manually annotated benchmarks that exhibit severe redundancy and coverage imbalance. This labor intensive paradigm drains computational and annotation resources, inflates costs, and distorts model rankings, ultimately stifling iterative development. To address this, we propose Agentic Automatic Evaluation (A2Eval), the first agentic framework that automates benchmark curation and evaluation through two collaborative agents. The Data Agent autonomously induces capability dimensions and assembles a balanced, compact evaluation suite, while the Eval Agent synthesizes and validates executable evaluation pipelines, enabling fully autonomous, high-fidelity assessment. Evaluated across 10 benchmarks and 13 models, A2Eval compresses evaluation suites by 85%, reduces overall computational costs by 77%, and delivers a 4.6x speedup while preserving evaluation quality. Crucially, A2Eval corrects systematic ranking biases, improves human alignment to Spearman's rho=0.85, and maintains high ranking fidelity (Kendall's tau=0.81), establishing a new standard for high-fidelity, low-cost embodied assessment. Our code and data will be public soon.
Formal Semantic Control over Language Models
Jan 31, 2026This thesis advances semantic representation learning to render language representations or models more semantically and geometrically interpretable, and to enable localised, quasi-symbolic, compositional control through deliberate shaping of their latent space geometry. We pursue this goal within a VAE framework, exploring two complementary research directions: (i) Sentence-level learning and control: disentangling and manipulating specific semantic features in the latent space to guide sentence generation, with explanatory text serving as the testbed; and (ii) Reasoning-level learning and control: isolating and steering inference behaviours in the latent space to control NLI. In this direction, we focus on Explanatory NLI tasks, in which two premises (explanations) are provided to infer a conclusion. The overarching objective is to move toward language models whose internal semantic representations can be systematically interpreted, precisely structured, and reliably directed. We introduce a set of novel theoretical frameworks and practical methodologies, together with corresponding experiments, to demonstrate that our approaches enhance both the interpretability and controllability of latent spaces for natural language across the thesis.
Learning to Disentangle Latent Reasoning Rules with Language VAEs: A Systematic Study
Jun 24, 2025Incorporating explicit reasoning rules within the latent space of language models (LMs) offers a promising pathway to enhance generalisation, interpretability, and controllability. While current Transformer-based language models have shown strong performance on Natural Language Inference (NLI) tasks, they often rely on memorisation rather than rule-based inference. This work investigates how reasoning rules can be explicitly embedded and memorised within the LMs through Language Variational Autoencoders (VAEs). We propose a complete pipeline for learning reasoning rules within Transformer-based language VAEs. This pipeline encompasses three rule-based reasoning tasks, a supporting theoretical framework, and a practical end-to-end architecture. The experiment illustrates the following findings: Disentangled reasoning: Under explicit signal supervision, reasoning rules - viewed as functional mappings - can be disentangled within the encoder's parametric space. This separation results in distinct clustering of rules in the output feature space. Prior knowledge injection: injecting reasoning information into the Query enables the model to more effectively retrieve the stored value Value from memory based on Key. This approach offers a simple method for integrating prior knowledge into decoder-only language models. Performance bottleneck: In mathematical reasoning tasks using Qwen2.5(0.5B), increasing sample count doesn't improve performance beyond a point. Moreover, ffn layers are better than attention layers at preserving the separation of reasoning rules in the model's parameters.
Improving Semantic Control in Discrete Latent Spaces with Transformer Quantized Variational Autoencoders
Feb 01, 2024Achieving precise semantic control over the latent spaces of Variational AutoEncoders (VAEs) holds significant value for downstream tasks in NLP as the underlying generative mechanisms could be better localised, explained and improved upon. Recent research, however, has struggled to achieve consistent results, primarily due to the inevitable loss of semantic information in the variational bottleneck and limited control over the decoding mechanism. To overcome these challenges, we investigate discrete latent spaces in Vector Quantized Variational AutoEncoders (VQVAEs) to improve semantic control and generation in Transformer-based VAEs. In particular, We propose T5VQVAE, a novel model that leverages the controllability of VQVAEs to guide the self-attention mechanism in T5 at the token-level, exploiting its full generalization capabilities. Experimental results indicate that T5VQVAE outperforms existing state-of-the-art VAE models, including Optimus, in terms of controllability and preservation of semantic information across different tasks such as auto-encoding of sentences and mathematical expressions, text transfer, and inference. Moreover, T5VQVAE exhibits improved inference capabilities, suggesting potential applications for downstream natural language and symbolic reasoning tasks.
LlaMaVAE: Guiding Large Language Model Generation via Continuous Latent Sentence Spaces
Dec 20, 2023Deep generative neural networks, such as Variational AutoEncoders (VAEs), offer an opportunity to better understand and control language models from the perspective of sentence-level latent spaces. To combine the controllability of VAE latent spaces with the state-of-the-art performance of recent large language models (LLMs), we present in this work LlaMaVAE, which combines expressive encoder and decoder models (sentenceT5 and LlaMA) with a VAE architecture, aiming to provide better text generation control to LLMs. In addition, to conditionally guide the VAE generation, we investigate a new approach based on flow-based invertible neural networks (INNs) named Invertible CVAE. Experimental results reveal that LlaMaVAE can outperform the previous state-of-the-art VAE language model, Optimus, across various tasks, including language modelling, semantic textual similarity and definition modelling. Qualitative analysis on interpolation and traversal experiments also indicates an increased degree of semantic clustering and geometric consistency, which enables better generation control.
Graph-Induced Syntactic-Semantic Spaces in Transformer-Based Variational AutoEncoders
Nov 14, 2023The injection of syntactic information in Variational AutoEncoders (VAEs) has been shown to result in an overall improvement of performances and generalisation. An effective strategy to achieve such a goal is to separate the encoding of distributional semantic features and syntactic structures into heterogeneous latent spaces via multi-task learning or dual encoder architectures. However, existing works employing such techniques are limited to LSTM-based VAEs. In this paper, we investigate latent space separation methods for structural syntactic injection in Transformer-based VAE architectures (i.e., Optimus). Specifically, we explore how syntactic structures can be leveraged in the encoding stage through the integration of graph-based and sequential models, and how multiple, specialised latent representations can be injected into the decoder's attention mechanism via low-rank operators. Our empirical evaluation, carried out on natural language sentences and mathematical expressions, reveals that the proposed end-to-end VAE architecture can result in a better overall organisation of the latent space, alleviating the information loss occurring in standard VAE setups, resulting in enhanced performances on language modelling and downstream generation tasks.
Towards Controllable Natural Language Inference through Lexical Inference Types
Aug 07, 2023



Explainable natural language inference aims to provide a mechanism to produce explanatory (abductive) inference chains which ground claims to their supporting premises. A recent corpus called EntailmentBank strives to advance this task by explaining the answer to a question using an entailment tree \cite{dalvi2021explaining}. They employ the T5 model to directly generate the tree, which can explain how the answer is inferred. However, it lacks the ability to explain and control the generation of intermediate steps, which is crucial for the multi-hop inference process. % One recent corpus, EntailmentBank, aims to push this task forward by explaining an answer to a question according to an entailment tree \cite{dalvi2021explaining}. They employ T5 to generate the tree directly, which can explain how the answer is inferred but cannot explain how the intermediate is generated, which is essential to the multi-hop inference process. In this work, we focus on proposing a controlled natural language inference architecture for multi-premise explanatory inference. To improve control and enable explanatory analysis over the generation, we define lexical inference types based on Abstract Meaning Representation (AMR) graph and modify the architecture of T5 to learn a latent sentence representation (T5 bottleneck) conditioned on said type information. We also deliver a dataset of approximately 5000 annotated explanatory inference steps, with well-grounded lexical-symbolic operations. Experimental results indicate that the inference typing induced at the T5 bottleneck can help T5 to generate a conclusion under explicit control.
Learning Disentangled Semantic Spaces of Explanations via Invertible Neural Networks
May 02, 2023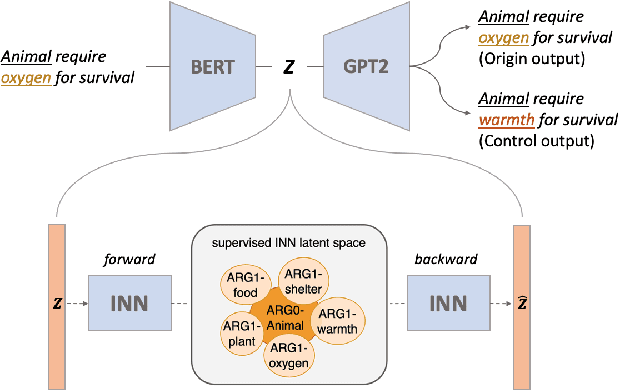

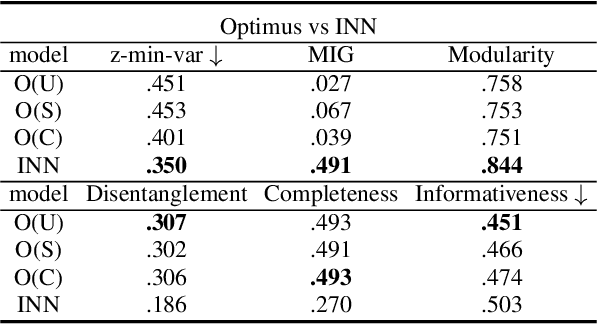
Disentangling sentence representations over continuous spaces can be a critical process in improving interpretability and semantic control by localising explicit generative factors. Such process confers to neural-based language models some of the advantages that are characteristic of symbolic models, while keeping their flexibility. This work presents a methodology for disentangling the hidden space of a BERT-GPT2 autoencoder by transforming it into a more separable semantic space with the support of a flow-based invertible neural network (INN). Experimental results indicate that the INN can transform the distributed hidden space into a better semantically disentangled latent space, resulting in better interpretability and controllability, when compared to recent state-of-the-art models.
Quasi-symbolic explanatory NLI via disentanglement: A geometrical examination
Oct 12, 2022
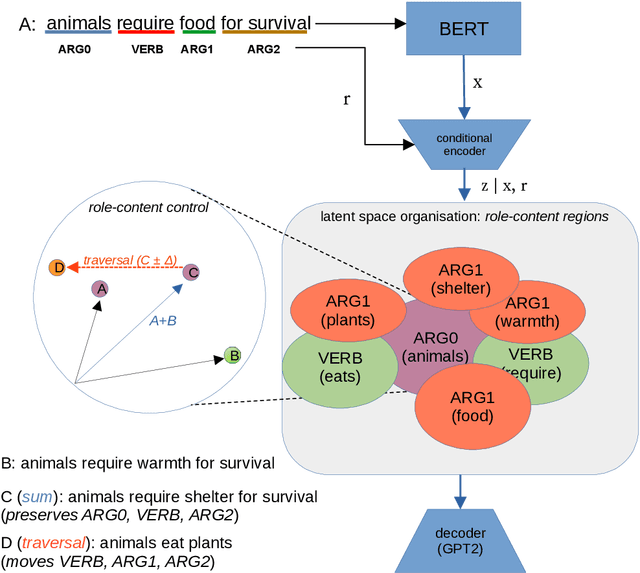
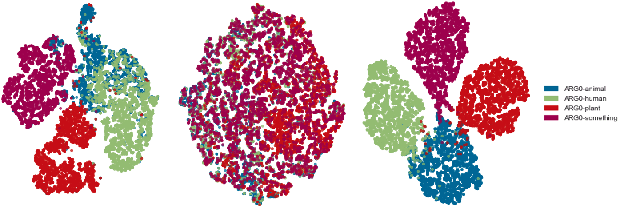
Disentangling the encodings of neural models is a fundamental aspect for improving interpretability, semantic control, and understanding downstream task performance in Natural Language Processing. The connection points between disentanglement and downstream tasks, however, remains underexplored from a explanatory standpoint. This work presents a methodology for assessment of geometrical properties of the resulting latent space w.r.t. vector operations and semantic disentanglement in quantitative and qualitative terms, based on a VAE-based supervised framework. Empirical results indicate that the role-contents of explanations, such as \textit{ARG0-animal}, are disentangled in the latent space, which provides us a chance for controlling the explanation generation by manipulating the traversal of vector over latent space.
Learning Disentangled Representations for Natural Language Definitions
Sep 22, 2022



Disentangling the encodings of neural models is a fundamental aspect for improving interpretability, semantic control and downstream task performance in Natural Language Processing. Currently, most disentanglement methods are unsupervised or rely on synthetic datasets with known generative factors. We argue that recurrent syntactic and semantic regularities in textual data can be used to provide the models with both structural biases and generative factors. We leverage the semantic structures present in a representative and semantically dense category of sentence types, definitional sentences, for training a Variational Autoencoder to learn disentangled representations. Our experimental results show that the proposed model outperforms unsupervised baselines on several qualitative and quantitative benchmarks for disentanglement, and it also improves the results in the downstream task of definition modeling.