 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Semantic Spaces of Explanations via Invertible Neural Networks
Paper and Code
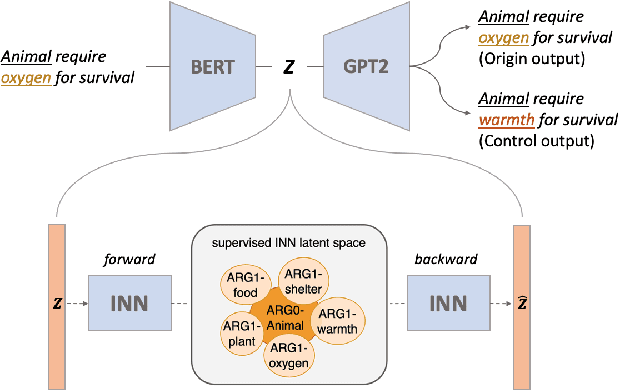

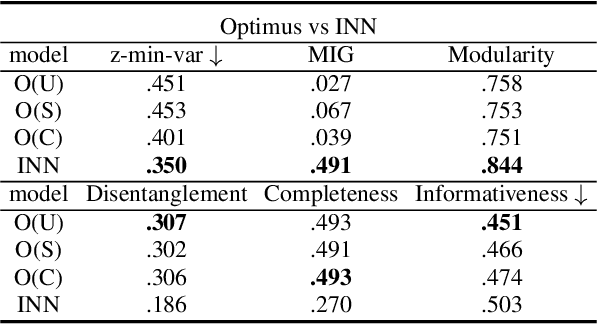
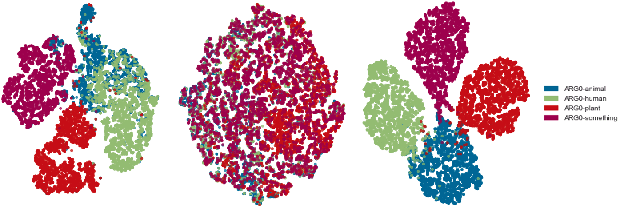
Disentangling sentence representations over continuous spaces can be a critical process in improving interpretability and semantic control by localising explicit generative factors. Such process confers to neural-based language models some of the advantages that are characteristic of symbolic models, while keeping their flexibility. This work presents a methodology for disentangling the hidden space of a BERT-GPT2 autoencoder by transforming it into a more separable semantic space with the support of a flow-based invertible neural network (INN). Experimental results indicate that the INN can transform the distributed hidden space into a better semantically disentangled latent space, resulting in better interpretability and controllability, when compared to recent state-of-the-art models.