 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Satisfiability: Exploring the Problem Distribution and Evaluating Transformer-based Language Models
Aug 23, 2025Efforts to apply transformer-based language models (TLMs) to the problem of reasoning in natural language have enjoyed ever-increasing success in recent years. The most fundamental task in this area to which nearly all others can be reduced is that of determining satisfiability. However, from a logical point of view, satisfiability problems vary along various dimensions, which may affect TLMs' ability to learn how to solve them. The problem instances of satisfiability in natural language can belong to different computational complexity classes depending on the language fragment in which they are expressed. Although prior research has explored the problem of natural language satisfiability, the above-mentioned point has not been discussed adequately. Hence, we investigate how problem instances from varying computational complexity classes and having different grammatical constructs impact TLMs' ability to learn rules of inference. Furthermore, to faithfully evaluate TLMs, we conduct an empirical study to explore the distribution of satisfiability problems.
* The paper was accepted to the 62nd Association for Computational Linguistics (ACL 2024), where it won the Best Paper Award
Improving Semantic Control in Discrete Latent Spaces with Transformer Quantized Variational Autoencoders
Feb 01, 2024Achieving precise semantic control over the latent spaces of Variational AutoEncoders (VAEs) holds significant value for downstream tasks in NLP as the underlying generative mechanisms could be better localised, explained and improved upon. Recent research, however, has struggled to achieve consistent results, primarily due to the inevitable loss of semantic information in the variational bottleneck and limited control over the decoding mechanism. To overcome these challenges, we investigate discrete latent spaces in Vector Quantized Variational AutoEncoders (VQVAEs) to improve semantic control and generation in Transformer-based VAEs. In particular, We propose T5VQVAE, a novel model that leverages the controllability of VQVAEs to guide the self-attention mechanism in T5 at the token-level, exploiting its full generalization capabilities. Experimental results indicate that T5VQVAE outperforms existing state-of-the-art VAE models, including Optimus, in terms of controllability and preservation of semantic information across different tasks such as auto-encoding of sentences and mathematical expressions, text transfer, and inference. Moreover, T5VQVAE exhibits improved inference capabilities, suggesting potential applications for downstream natural language and symbolic reasoning tasks.
LlaMaVAE: Guiding Large Language Model Generation via Continuous Latent Sentence Spaces
Dec 20, 2023Deep generative neural networks, such as Variational AutoEncoders (VAEs), offer an opportunity to better understand and control language models from the perspective of sentence-level latent spaces. To combine the controllability of VAE latent spaces with the state-of-the-art performance of recent large language models (LLMs), we present in this work LlaMaVAE, which combines expressive encoder and decoder models (sentenceT5 and LlaMA) with a VAE architecture, aiming to provide better text generation control to LLMs. In addition, to conditionally guide the VAE generation, we investigate a new approach based on flow-based invertible neural networks (INNs) named Invertible CVAE. Experimental results reveal that LlaMaVAE can outperform the previous state-of-the-art VAE language model, Optimus, across various tasks, including language modelling, semantic textual similarity and definition modelling. Qualitative analysis on interpolation and traversal experiments also indicates an increased degree of semantic clustering and geometric consistency, which enables better generation control.
Graph-Induced Syntactic-Semantic Spaces in Transformer-Based Variational AutoEncoders
Nov 14, 2023



The injection of syntactic information in Variational AutoEncoders (VAEs) has been shown to result in an overall improvement of performances and generalisation. An effective strategy to achieve such a goal is to separate the encoding of distributional semantic features and syntactic structures into heterogeneous latent spaces via multi-task learning or dual encoder architectures. However, existing works employing such techniques are limited to LSTM-based VAEs. In this paper, we investigate latent space separation methods for structural syntactic injection in Transformer-based VAE architectures (i.e., Optimus). Specifically, we explore how syntactic structures can be leveraged in the encoding stage through the integration of graph-based and sequential models, and how multiple, specialised latent representations can be injected into the decoder's attention mechanism via low-rank operators. Our empirical evaluation, carried out on natural language sentences and mathematical expressions, reveals that the proposed end-to-end VAE architecture can result in a better overall organisation of the latent space, alleviating the information loss occurring in standard VAE setups, resulting in enhanced performances on language modelling and downstream generation tasks.
Towards Controllable Natural Language Inference through Lexical Inference Types
Aug 07, 2023



Explainable natural language inference aims to provide a mechanism to produce explanatory (abductive) inference chains which ground claims to their supporting premises. A recent corpus called EntailmentBank strives to advance this task by explaining the answer to a question using an entailment tree \cite{dalvi2021explaining}. They employ the T5 model to directly generate the tree, which can explain how the answer is inferred. However, it lacks the ability to explain and control the generation of intermediate steps, which is crucial for the multi-hop inference process. % One recent corpus, EntailmentBank, aims to push this task forward by explaining an answer to a question according to an entailment tree \cite{dalvi2021explaining}. They employ T5 to generate the tree directly, which can explain how the answer is inferred but cannot explain how the intermediate is generated, which is essential to the multi-hop inference process. In this work, we focus on proposing a controlled natural language inference architecture for multi-premise explanatory inference. To improve control and enable explanatory analysis over the generation, we define lexical inference types based on Abstract Meaning Representation (AMR) graph and modify the architecture of T5 to learn a latent sentence representation (T5 bottleneck) conditioned on said type information. We also deliver a dataset of approximately 5000 annotated explanatory inference steps, with well-grounded lexical-symbolic operations. Experimental results indicate that the inference typing induced at the T5 bottleneck can help T5 to generate a conclusion under explicit control.
Learning Disentangled Semantic Spaces of Explanations via Invertible Neural Networks
May 02, 2023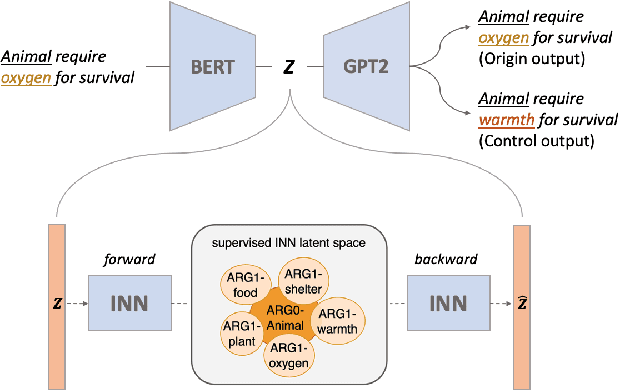

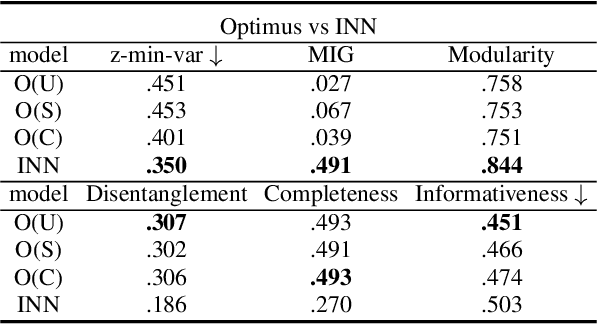
Disentangling sentence representations over continuous spaces can be a critical process in improving interpretability and semantic control by localising explicit generative factors. Such process confers to neural-based language models some of the advantages that are characteristic of symbolic models, while keeping their flexibility. This work presents a methodology for disentangling the hidden space of a BERT-GPT2 autoencoder by transforming it into a more separable semantic space with the support of a flow-based invertible neural network (INN). Experimental results indicate that the INN can transform the distributed hidden space into a better semantically disentangled latent space, resulting in better interpretability and controllability, when compared to recent state-of-the-art models.
Can Transformers Reason in Fragments of Natural Language?
Nov 10, 2022State-of-the-art deep-learning-based approaches to Natural Language Processing (NLP) are credited with various capabilities that involve reasoning with natural language texts. In this paper we carry out a large-scale empirical study investigating the detection of formally valid inferences in controlled fragments of natural language for which the satisfiability problem becomes increasingly complex. We find that, while transformer-based language models perform surprisingly well in these scenarios, a deeper analysis re-veals that they appear to overfit to superficial patterns in the data rather than acquiring the logical principles governing the reasoning in these fragments.
Quasi-symbolic explanatory NLI via disentanglement: A geometrical examination
Oct 12, 2022
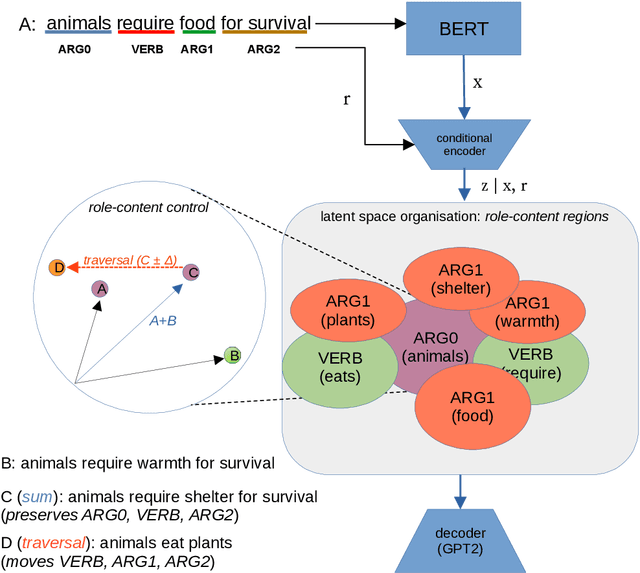
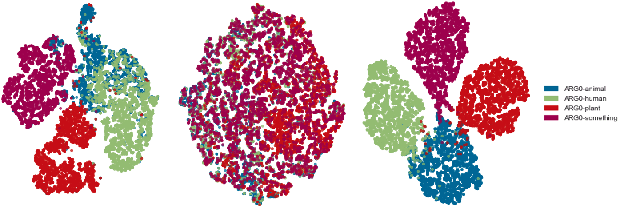
Disentangling the encodings of neural models is a fundamental aspect for improving interpretability, semantic control, and understanding downstream task performance in Natural Language Processing. The connection points between disentanglement and downstream tasks, however, remains underexplored from a explanatory standpoint. This work presents a methodology for assessment of geometrical properties of the resulting latent space w.r.t. vector operations and semantic disentanglement in quantitative and qualitative terms, based on a VAE-based supervised framework. Empirical results indicate that the role-contents of explanations, such as \textit{ARG0-animal}, are disentangled in the latent space, which provides us a chance for controlling the explanation generation by manipulating the traversal of vector over latent space.
Do Natural Language Explanations Represent Valid Logical Arguments? Verifying Entailment in Explainable NLI Gold Standards
May 15, 2021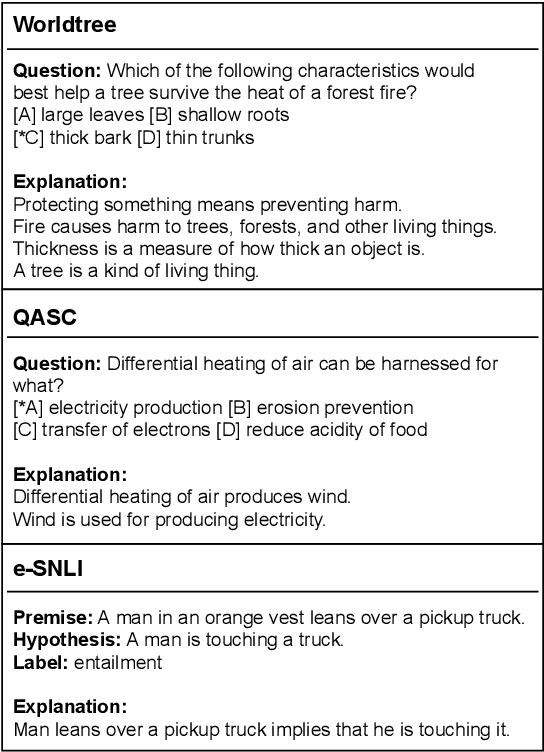

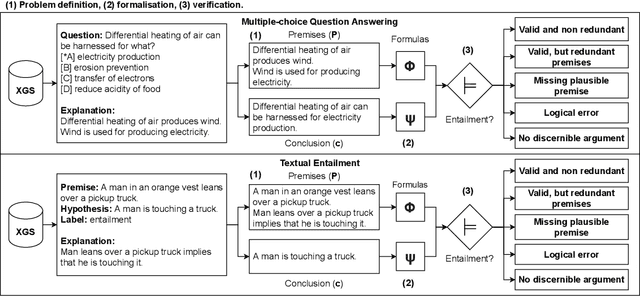

An emerging line of research in Explainable NLP is the creation of datasets enriched with human-annotated explanations and rationales, used to build and evaluate models with step-wise inference and explanation generation capabilities. While human-annotated explanations are used as ground-truth for the inference, there is a lack of systematic assessment of their consistency and rigour. In an attempt to provide a critical quality assessment of Explanation Gold Standards (XGSs) for NLI, we propose a systematic annotation methodology, named Explanation Entailment Verification (EEV), to quantify the logical validity of human-annotated explanations. The application of EEV on three mainstream datasets reveals the surprising conclusion that a majority of the explanations, while appearing coherent on the surface, represent logically invalid arguments, ranging from being incomplete to containing clearly identifiable logical errors. This conclusion confirms that the inferential properties of explanations are still poorly formalised and understood, and that additional work on this line of research is necessary to improve the way Explanation Gold Standards are constructed.
A Note on the Complexity of the Satisfiability Problem for Graded Modal Logics
May 19, 2009

Graded modal logic is the formal language obtained from ordinary (propositional) modal logic by endowing its modal operators with cardinality constraints. Under the familiar possible-worlds semantics, these augmented modal operators receive interpretations such as "It is true at no fewer than 15 accessible worlds that...", or "It is true at no more than 2 accessible worlds that...". We investigate the complexity of satisfiability for this language over some familiar classes of frames. This problem is more challenging than its ordinary modal logic counterpart--especially in the case of transitive frames, where graded modal logic lacks the tree-model property. We obtain tight complexity bounds for the problem of determining the satisfiability of a given graded modal logic formula over the classes of frames characterized by any combination of reflexivity, seriality, symmetry, transitivity and the Euclidean property.