 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Mathematical Concepts with Large Language Models
Aug 29, 2023



We extract mathematical concepts from mathematical text using generative large language models (LLMs) like ChatGPT, contributing to the field of automatic term extraction (ATE) and mathematical text processing, and also to the study of LLMs themselves. Our work builds on that of others in that we aim for automatic extraction of terms (keywords) in one mathematical field, category theory, using as a corpus the 755 abstracts from a snapshot of the online journal "Theory and Applications of Categories", circa 2020. Where our study diverges from previous work is in (1) providing a more thorough analysis of what makes mathematical term extraction a difficult problem to begin with; (2) paying close attention to inter-annotator disagreements; (3) providing a set of guidelines which both human and machine annotators could use to standardize the extraction process; (4) introducing a new annotation tool to help humans with ATE, applicable to any mathematical field and even beyond mathematics; (5) using prompts to ChatGPT as part of the extraction process, and proposing best practices for such prompts; and (6) raising the question of whether ChatGPT could be used as an annotator on the same level as human experts. Our overall findings are that the matter of mathematical ATE is an interesting field which can benefit from participation by LLMs, but LLMs themselves cannot at this time surpass human performance on it.
NeuralLog: Natural Language Inference with Joint Neural and Logical Reasoning
Jun 10, 2021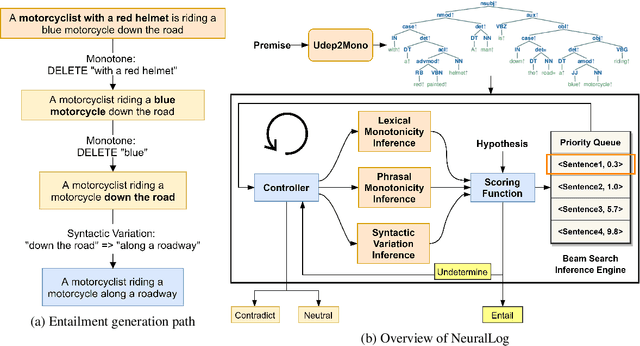
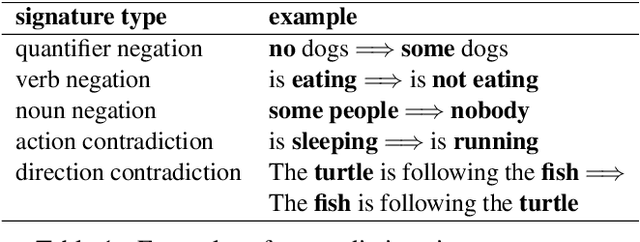
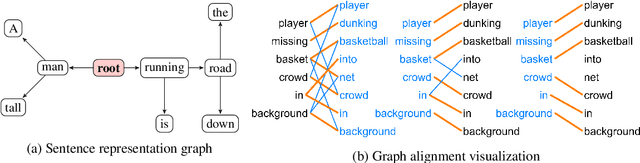

Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference (NLI). And at this time, symbolic approaches to NLI are receiving less attention. Both approaches (symbolic and DL) have their advantages and weaknesses. However, currently, no method combines them in a system to solve the task of NLI. To merge symbolic and deep learning methods, we propose an inference framework called NeuralLog, which utilizes both a monotonicity-based logical inference engine and a neural network language model for phrase alignment. Our framework models the NLI task as a classic search problem and uses the beam search algorithm to search for optimal inference paths. Experiments show that our joint logic and neural inference system improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.
OCNLI: Original Chinese Natural Language Inference
Oct 12, 2020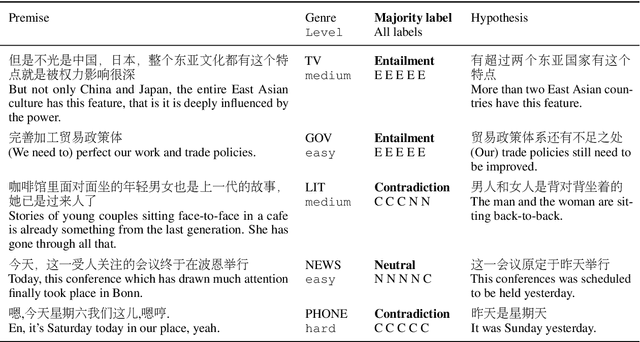
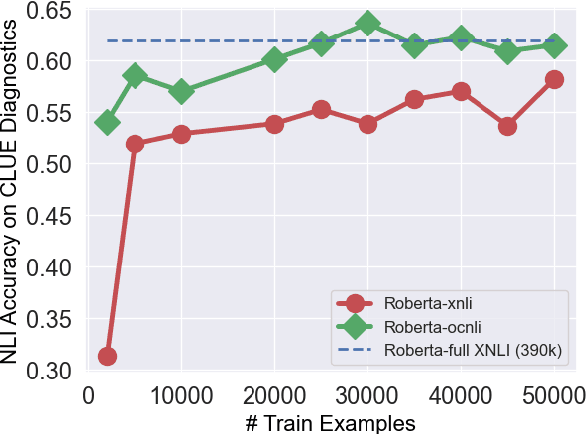
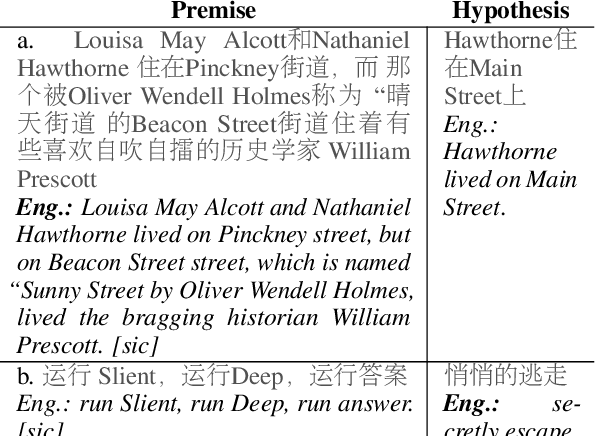

Despite the tremendous recent progress on natural language inference (NLI), driven largely by large-scale investment in new datasets (e.g., SNLI, MNLI) and advances in modeling, most progress has been limited to English due to a lack of reliable datasets for most of the world's languages. In this paper, we present the first large-scale NLI dataset (consisting of ~56,000 annotated sentence pairs) for Chinese called the Original Chinese Natural Language Inference dataset (OCNLI). Unlike recent attempts at extending NLI to other languages, our dataset does not rely on any automatic translation or non-expert annotation. Instead, we elicit annotations from native speakers specializing in linguistics. We follow closely the annotation protocol used for MNLI, but create new strategies for eliciting diverse hypotheses. We establish several baseline results on our dataset using state-of-the-art pre-trained models for Chinese, and find even the best performing models to be far outpaced by human performance (~12% absolute performance gap), making it a challenging new resource that we hope will help to accelerate progress in Chinese NLU. To the best of our knowledge, this is the first human-elicited MNLI-style corpus for a non-English language.
MonaLog: a Lightweight System for Natural Language Inference Based on Monotonicity
Oct 19, 2019


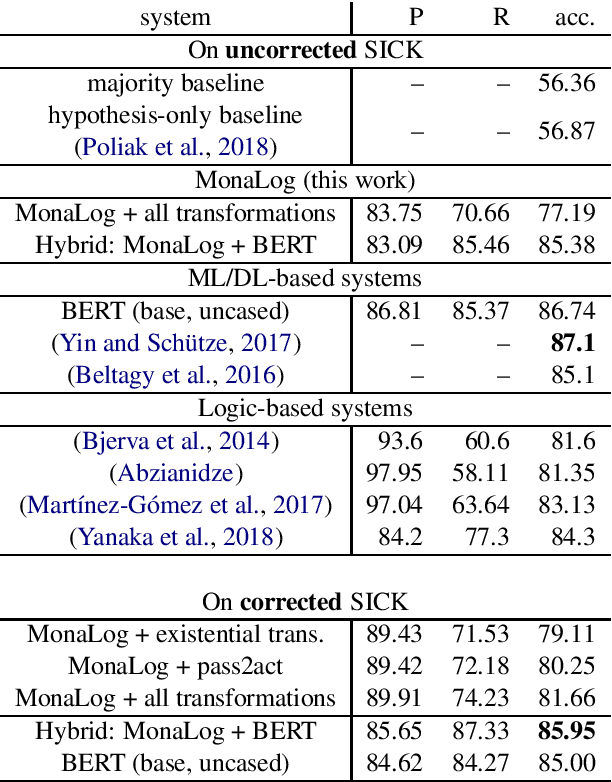
We present a new logic-based inference engine for natural language inference (NLI) called MonaLog, which is based on natural logic and the monotonicity calculus. In contrast to existing logic-based approaches, our system is intentionally designed to be as lightweight as possible, and operates using a small set of well-known (surface-level) monotonicity facts about quantifiers, lexical items and tokenlevel polarity information. Despite its simplicity, we find our approach to be competitive with other logic-based NLI models on the SICK benchmark. We also use MonaLog in combination with the current state-of-the-art model BERT in a variety of settings, including for compositional data augmentation. We show that MonaLog is capable of generating large amounts of high-quality training data for BERT, improving its accuracy on SICK.
Probing Natural Language Inference Models through Semantic Fragments
Sep 16, 2019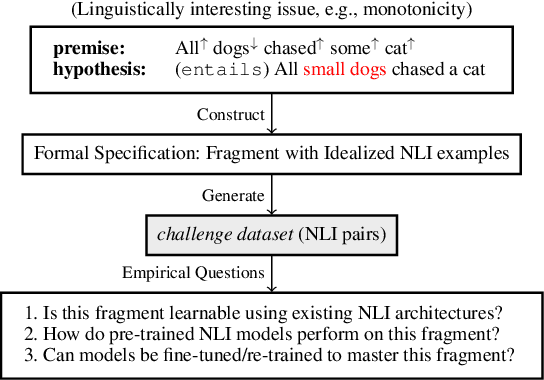



Do state-of-the-art models for language understanding already have, or can they easily learn, abilities such as boolean coordination, quantification, conditionals, comparatives, and monotonicity reasoning (i.e., reasoning about word substitutions in sentential contexts)? While such phenomena are involved in natural language inference (NLI) and go beyond basic linguistic understanding, it is unclear the extent to which they are captured in existing NLI benchmarks and effectively learned by models. To investigate this, we propose the use of semantic fragments---systematically generated datasets that each target a different semantic phenomenon---for probing, and efficiently improving, such capabilities of linguistic models. This approach to creating challenge datasets allows direct control over the semantic diversity and complexity of the targeted linguistic phenomena, and results in a more precise characterization of a model's linguistic behavior. Our experiments, using a library of 8 such semantic fragments, reveal two remarkable findings: (a) State-of-the-art models, including BERT, that are pre-trained on existing NLI benchmark datasets perform poorly on these new fragments, even though the phenomena probed here are central to the NLI task. (b) On the other hand, with only a few minutes of additional fine-tuning---with a carefully selected learning rate and a novel variation of "inoculation"---a BERT-based model can master all of these logic and monotonicity fragments while retaining its performance on established NLI benchmarks.
Exploring the Landscape of Relational Syllogistic Logics
Sep 03, 2018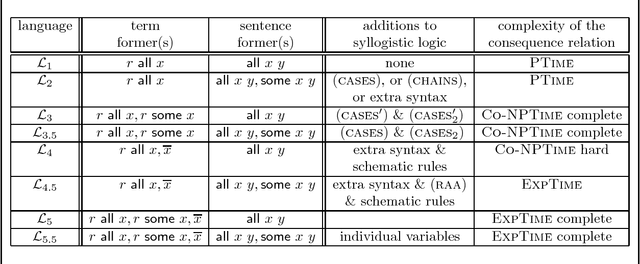


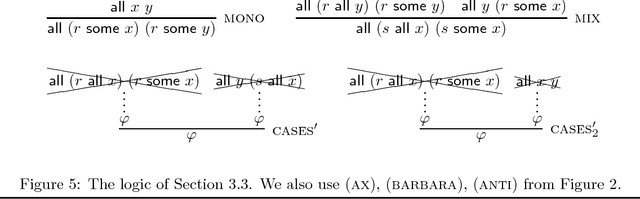
This paper explores relational syllogistic logics, a family of logical systems related to reasoning about relations in extensions of the classical syllogistic. These are all decidable logical systems. We prove completeness theorems and complexity results for a natural subfamily of relational syllogistic logics, parametrized by constructors for terms and for sentences.
Logics for the Relational Syllogistic
Aug 04, 2008



The Aristotelian syllogistic cannot account for the validity of many inferences involving relational facts. In this paper, we investigate the prospects for providing a relational syllogistic. We identify several fragments based on (a) whether negation is permitted on all nouns, including those in the subject of a sentence; and (b) whether the subject noun phrase may contain a relative clause. The logics we present are extensions of the classical syllogistic, and we pay special attention to the question of whether reductio ad absurdum is needed. Thus our main goal is to derive results on the existence (or non-existence) of syllogistic proof systems for relational fragments. We also determine the computational complexity of all our fragments.