 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical Entities: Corpora and Benchmarks
Jun 17, 2024Mathematics is a highly specialized domain with its own unique set of challenges. Despite this, there has been relatively little research on natural language processing for mathematical texts, and there are few mathematical language resources aimed at NLP. In this paper, we aim to provide annotated corpora that can be used to study the language of mathematics in different contexts, ranging from fundamental concepts found in textbooks to advanced research mathematics. We preprocess the corpora with a neural parsing model and some manual intervention to provide part-of-speech tags, lemmas, and dependency trees. In total, we provide 182397 sentences across three corpora. We then aim to test and evaluate several noteworthy natural language processing models using these corpora, to show how well they can adapt to the domain of mathematics and provide useful tools for exploring mathematical language. We evaluate several neural and symbolic models against benchmarks that we extract from the corpus metadata to show that terminology extraction and definition extraction do not easily generalize to mathematics, and that additional work is needed to achieve good performance on these metrics. Finally, we provide a learning assistant that grants access to the content of these corpora in a context-sensitive manner, utilizing text search and entity linking. Though our corpora and benchmarks provide useful metrics for evaluating mathematical language processing, further work is necessary to adapt models to mathematics in order to provide more effective learning assistants and apply NLP methods to different mathematical domains.
Towards a Brazilian History Knowledge Graph
Mar 28, 2024

This short paper describes the first steps in a project to construct a knowledge graph for Brazilian history based on the Brazilian Dictionary of Historical Biographies (DHBB) and Wikipedia/Wikidata. We contend that large repositories of Brazilian-named entities (people, places, organizations, and political events and movements) would be beneficial for extracting information from Portuguese texts. We show that many of the terms/entities described in the DHBB do not have corresponding concepts (or Q items) in Wikidata, the largest structured database of entities associated with Wikipedia. We describe previous work on extracting information from the DHBB and outline the steps to construct a Wikidata-based historical knowledge graph.
MathGloss: Building mathematical glossaries from text
Nov 21, 2023MathGloss is a project to create a knowledge graph (KG) for undergraduate mathematics from text, automatically, using modern natural language processing (NLP) tools and resources already available on the web. MathGloss is a linked database of undergraduate concepts in mathematics. So far, it combines five resources: (i) Wikidata, a collaboratively edited, multilingual knowledge graph hosted by the Wikimedia Foundation, (ii) terms covered in mathematics courses at the University of Chicago, (iii) the syllabus of the French undergraduate mathematics curriculum which includes hyperlinks to the automated theorem prover Lean 4, (iv) MuLiMa, a multilingual dictionary of mathematics curated by mathematicians, and (v) the nLab, a wiki for category theory also curated by mathematicians. MathGloss's goal is to bring together resources for learning mathematics and to allow every mathematician to tailor their learning to their own preferences. Moreover, by organizing different resources for learning undergraduate mathematics alongside those for learning formal mathematics, we hope to make it easier for mathematicians and formal tools (theorem provers, computer algebra systems, etc) experts to "understand" each other and break down some of the barriers to formal math.
Extracting Mathematical Concepts with Large Language Models
Aug 29, 2023



We extract mathematical concepts from mathematical text using generative large language models (LLMs) like ChatGPT, contributing to the field of automatic term extraction (ATE) and mathematical text processing, and also to the study of LLMs themselves. Our work builds on that of others in that we aim for automatic extraction of terms (keywords) in one mathematical field, category theory, using as a corpus the 755 abstracts from a snapshot of the online journal "Theory and Applications of Categories", circa 2020. Where our study diverges from previous work is in (1) providing a more thorough analysis of what makes mathematical term extraction a difficult problem to begin with; (2) paying close attention to inter-annotator disagreements; (3) providing a set of guidelines which both human and machine annotators could use to standardize the extraction process; (4) introducing a new annotation tool to help humans with ATE, applicable to any mathematical field and even beyond mathematics; (5) using prompts to ChatGPT as part of the extraction process, and proposing best practices for such prompts; and (6) raising the question of whether ChatGPT could be used as an annotator on the same level as human experts. Our overall findings are that the matter of mathematical ATE is an interesting field which can benefit from participation by LLMs, but LLMs themselves cannot at this time surpass human performance on it.
Parmesan: mathematical concept extraction for education
Jul 17, 2023Mathematics is a highly specialized domain with its own unique set of challenges that has seen limited study in natural language processing. However, mathematics is used in a wide variety of fields and multidisciplinary research in many different domains often relies on an understanding of mathematical concepts. To aid researchers coming from other fields, we develop a prototype system for searching for and defining mathematical concepts in context, focusing on the field of category theory. This system, Parmesan, depends on natural language processing components including concept extraction, relation extraction, definition extraction, and entity linking. In developing this system, we show that existing techniques cannot be applied directly to the category theory domain, and suggest hybrid techniques that do perform well, though we expect the system to evolve over time. We also provide two cleaned mathematical corpora that power the prototype system, which are based on journal articles and wiki pages, respectively. The corpora have been annotated with dependency trees, lemmas, and part-of-speech tags.
Extracting Mathematical Concepts from Text
Aug 29, 2022

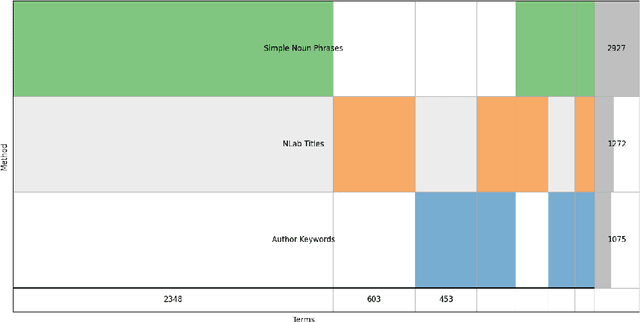
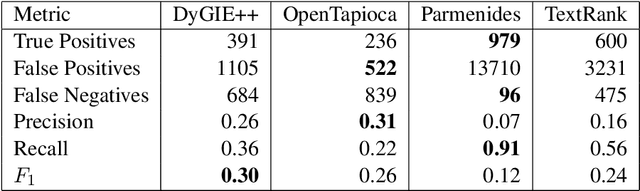
We investigate different systems for extracting mathematical entities from English texts in the mathematical field of category theory as a first step for constructing a mathematical knowledge graph. We consider four different term extractors and compare their results. This small experiment showcases some of the issues with the construction and evaluation of terms extracted from noisy domain text. We also make available two open corpora in research mathematics, in particular in category theory: a small corpus of 755 abstracts from the journal TAC (3188 sentences), and a larger corpus from the nLab community wiki (15,000 sentences).
Deriving Theorems in Implicational Linear Logic, Declaratively
Sep 22, 2020The problem we want to solve is how to generate all theorems of a given size in the implicational fragment of propositional intuitionistic linear logic. We start by filtering for linearity the proof terms associated by our Prolog-based theorem prover for Implicational Intuitionistic Logic. This works, but using for each formula a PSPACE-complete algorithm limits it to very small formulas. We take a few walks back and forth over the bridge between proof terms and theorems, provided by the Curry-Howard isomorphism, and derive step-by-step an efficient algorithm requiring a low polynomial effort per generated theorem. The resulting Prolog program runs in O(N) space for terms of size N and generates in a few hours 7,566,084,686 theorems in the implicational fragment of Linear Intuitionistic Logic together with their proof terms in normal form. As applications, we generate datasets for correctness and scalability testing of linear logic theorem provers and training data for neural networks working on theorem proving challenges. The results in the paper, organized as a literate Prolog program, are fully replicable. Keywords: combinatorial generation of provable formulas of a given size, intuitionistic and linear logic theorem provers, theorems of the implicational fragment of propositional linear intuitionistic logic, Curry-Howard isomorphism, efficient generation of linear lambda terms in normal form, Prolog programs for lambda term generation and theorem proving.
* In Proceedings ICLP 2020, arXiv:2009.09158
Linguistic Legal Concept Extraction in Portuguese
Oct 22, 2018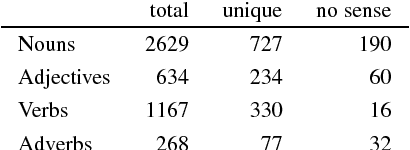
This work investigates legal concepts and their expression in Portuguese, concentrating on the "Order of Attorneys of Brazil" Bar exam. Using a corpus formed by a collection of multiple-choice questions, three norms related to the Ethics part of the OAB exam, language resources (Princeton WordNet and OpenWordNet-PT) and tools (AntConc and Freeling), we began to investigate the concepts and words missing from our repertory of concepts and words in Portuguese, the knowledge base OpenWordNet-PT. We add these concepts and words to OpenWordNet-PT and hence obtain a representation of these texts that is "contained" in the lexical knowledge base.
Proceedings of the LexSem+Logics Workshop 2016
Aug 14, 2016Lexical semantics continues to play an important role in driving research directions in NLP, with the recognition and understanding of context becoming increasingly important in delivering successful outcomes in NLP tasks. Besides traditional processing areas such as word sense and named entity disambiguation, the creation and maintenance of dictionaries, annotated corpora and resources have become cornerstones of lexical semantics research and produced a wealth of contextual information that NLP processes can exploit. New efforts both to link and construct from scratch such information - as Linked Open Data or by way of formal tools coming from logic, ontologies and automated reasoning - have increased the interoperability and accessibility of resources for lexical and computational semantics, even in those languages for which they have previously been limited. LexSem+Logics 2016 combines the 1st Workshop on Lexical Semantics for Lesser-Resources Languages and the 3rd Workshop on Logics and Ontologies. The accepted papers in our program covered topics across these two areas, including: the encoding of plurals in Wordnets, the creation of a thesaurus from multiple sources based on semantic similarity metrics, and the use of cross-lingual treebanks and annotations for universal part-of-speech tagging. We also welcomed talks from two distinguished speakers: on Portuguese lexical knowledge bases (different approaches, results and their application in NLP tasks) and on new strategies for open information extraction (the capture of verb-based propositions from massive text corpora).