 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated, LLM enabled extraction of synthesis details for reticular materials from scientific literature
Nov 05, 2024



Automated knowledge extraction from scientific literature can potentially accelerate materials discovery. We have investigated an approach for extracting synthesis protocols for reticular materials from scientific literature using large language models (LLMs). To that end, we introduce a Knowledge Extraction Pipeline (KEP) that automatizes LLM-assisted paragraph classification and information extraction. By applying prompt engineering with in-context learning (ICL) to a set of open-source LLMs, we demonstrate that LLMs can retrieve chemical information from PDF documents, without the need for fine-tuning or training and at a reduced risk of hallucination. By comparing the performance of five open-source families of LLMs in both paragraph classification and information extraction tasks, we observe excellent model performance even if only few example paragraphs are included in the ICL prompts. The results show the potential of the KEP approach for reducing human annotations and data curation efforts in automated scientific knowledge extraction.
Towards a Brazilian History Knowledge Graph
Mar 28, 2024

This short paper describes the first steps in a project to construct a knowledge graph for Brazilian history based on the Brazilian Dictionary of Historical Biographies (DHBB) and Wikipedia/Wikidata. We contend that large repositories of Brazilian-named entities (people, places, organizations, and political events and movements) would be beneficial for extracting information from Portuguese texts. We show that many of the terms/entities described in the DHBB do not have corresponding concepts (or Q items) in Wikidata, the largest structured database of entities associated with Wikipedia. We describe previous work on extracting information from the DHBB and outline the steps to construct a Wikidata-based historical knowledge graph.
PriMeSRL-Eval: A Practical Quality Metric for Semantic Role Labeling Systems Evaluation
Oct 12, 2022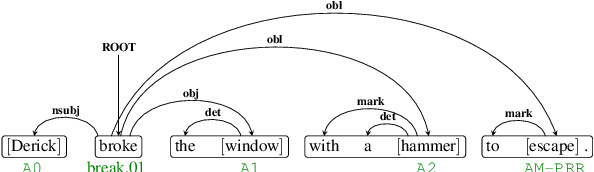
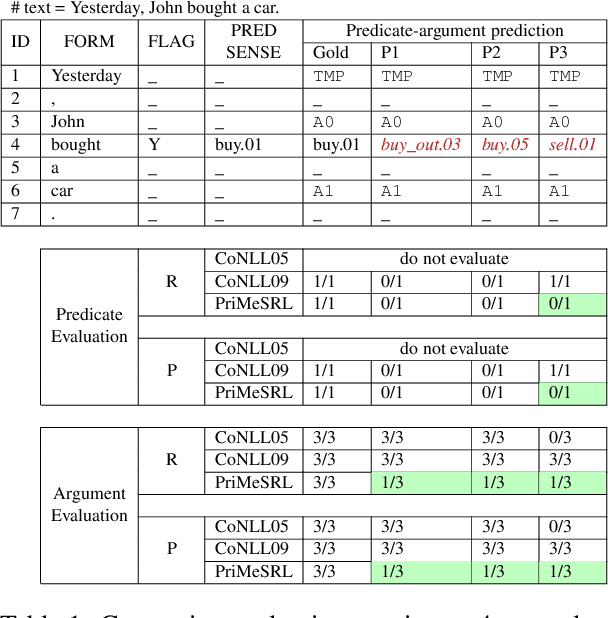
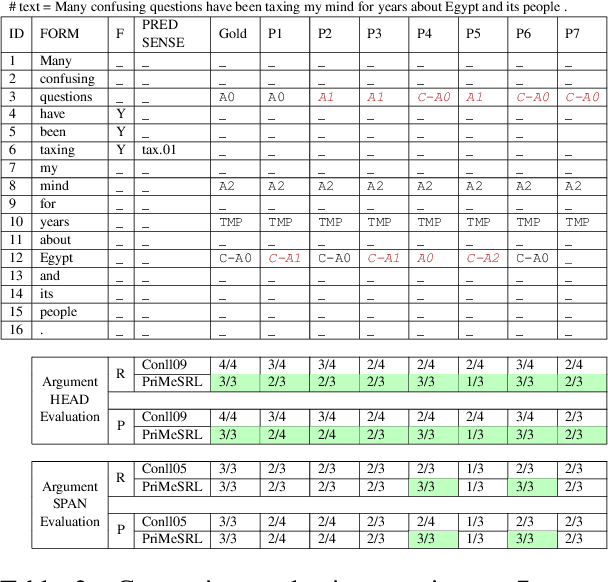
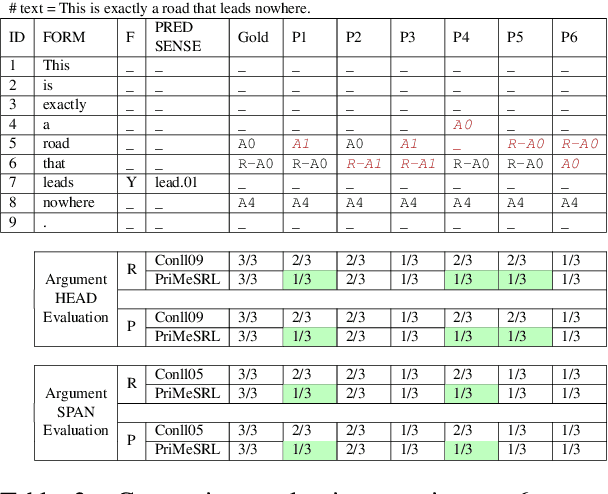
Semantic role labeling (SRL) identifies the predicate-argument structure in a sentence. This task is usually accomplished in four steps: predicate identification, predicate sense disambiguation, argument identification, and argument classification. Errors introduced at one step propagate to later steps. Unfortunately, the existing SRL evaluation scripts do not consider the full effect of this error propagation aspect. They either evaluate arguments independent of predicate sense (CoNLL09) or do not evaluate predicate sense at all (CoNLL05), yielding an inaccurate SRL model performance on the argument classification task. In this paper, we address key practical issues with existing evaluation scripts and propose a more strict SRL evaluation metric PriMeSRL. We observe that by employing PriMeSRL, the quality evaluation of all SoTA SRL models drops significantly, and their relative rankings also change. We also show that PriMeSRLsuccessfully penalizes actual failures in SoTA SRL models.
Linguistic Legal Concept Extraction in Portuguese
Oct 22, 2018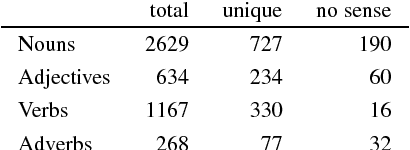
This work investigates legal concepts and their expression in Portuguese, concentrating on the "Order of Attorneys of Brazil" Bar exam. Using a corpus formed by a collection of multiple-choice questions, three norms related to the Ethics part of the OAB exam, language resources (Princeton WordNet and OpenWordNet-PT) and tools (AntConc and Freeling), we began to investigate the concepts and words missing from our repertory of concepts and words in Portuguese, the knowledge base OpenWordNet-PT. We add these concepts and words to OpenWordNet-PT and hence obtain a representation of these texts that is "contained" in the lexical knowledge base.
Passing the Brazilian OAB Exam: data preparation and some experiments
Dec 14, 2017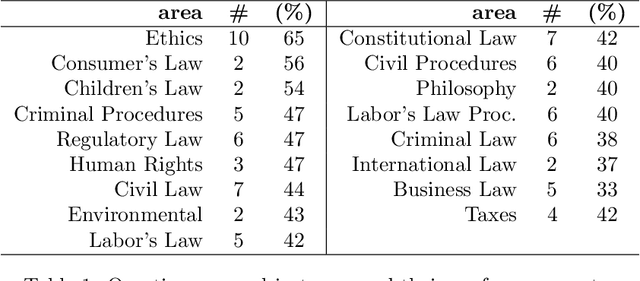
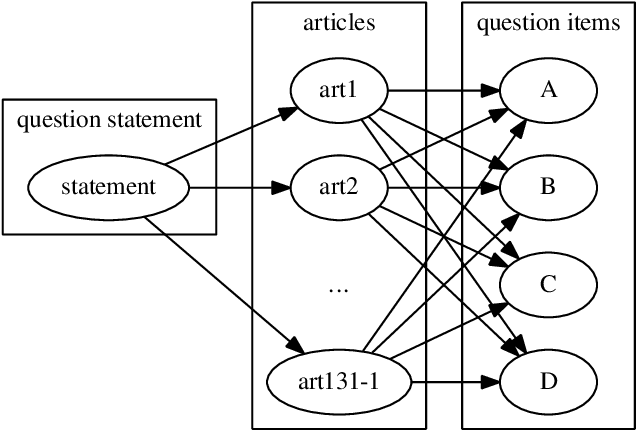
In Brazil, all legal professionals must demonstrate their knowledge of the law and its application by passing the OAB exams, the national bar exams. The OAB exams therefore provide an excellent benchmark for the performance of legal information systems since passing the exam would arguably signal that the system has acquired capacity of legal reasoning comparable to that of a human lawyer. This article describes the construction of a new data set and some preliminary experiments on it, treating the problem of finding the justification for the answers to questions. The results provide a baseline performance measure against which to evaluate future improvements. We discuss the reasons to the poor performance and propose next steps.
* Extended version of the paper published in the Proceedings of JURIX 2017 (http://ebooks.iospress.nl/ISBN/978-1-61499-838-9)
Proceedings of the LexSem+Logics Workshop 2016
Aug 14, 2016Lexical semantics continues to play an important role in driving research directions in NLP, with the recognition and understanding of context becoming increasingly important in delivering successful outcomes in NLP tasks. Besides traditional processing areas such as word sense and named entity disambiguation, the creation and maintenance of dictionaries, annotated corpora and resources have become cornerstones of lexical semantics research and produced a wealth of contextual information that NLP processes can exploit. New efforts both to link and construct from scratch such information - as Linked Open Data or by way of formal tools coming from logic, ontologies and automated reasoning - have increased the interoperability and accessibility of resources for lexical and computational semantics, even in those languages for which they have previously been limited. LexSem+Logics 2016 combines the 1st Workshop on Lexical Semantics for Lesser-Resources Languages and the 3rd Workshop on Logics and Ontologies. The accepted papers in our program covered topics across these two areas, including: the encoding of plurals in Wordnets, the creation of a thesaurus from multiple sources based on semantic similarity metrics, and the use of cross-lingual treebanks and annotations for universal part-of-speech tagging. We also welcomed talks from two distinguished speakers: on Portuguese lexical knowledge bases (different approaches, results and their application in NLP tasks) and on new strategies for open information extraction (the capture of verb-based propositions from massive text corpora).