 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Path of Least Resistance: Guiding LLM Reasining Trajectories with Prefix Consensus
Jan 29, 2026Large language models achieve strong reasoning performance, but inference strategies such as Self-Consistency (SC) are computationally expensive, as they fully expand all reasoning traces. We introduce PoLR (Path of Least Resistance), the first inference-time method to leverage prefix consistency for compute-efficient reasoning. PoLR clusters short prefixes of reasoning traces, identifies the dominant cluster, and expands all paths in that cluster, preserving the accuracy benefits of SC while substantially reducing token usage and latency. Our theoretical analysis, framed via mutual information and entropy, explains why early reasoning steps encode strong signals predictive of final correctness. Empirically, PoLR consistently matches or exceeds SC across GSM8K, MATH500, AIME24/25, and GPQA-DIAMOND, reducing token usage by up to 60% and wall-clock latency by up to 50%. Moreover, PoLR is fully complementary to adaptive inference methods (e.g., Adaptive Consistency, Early-Stopping SC) and can serve as a drop-in pre-filter, making SC substantially more efficient and scalable without requiring model fine-tuning.
Balancing Continuous Pre-Training and Instruction Fine-Tuning: Optimizing Instruction-Following in LLMs
Oct 14, 2024

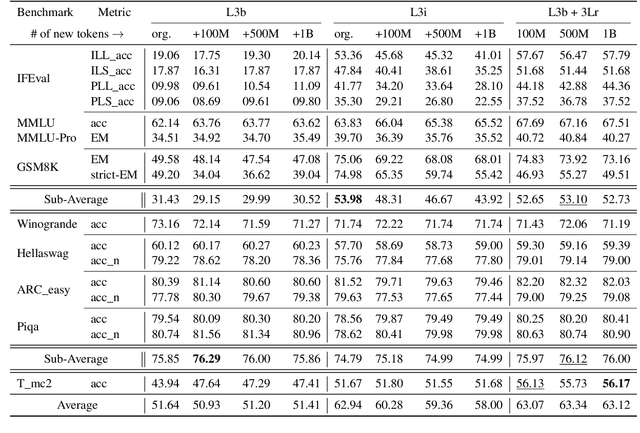
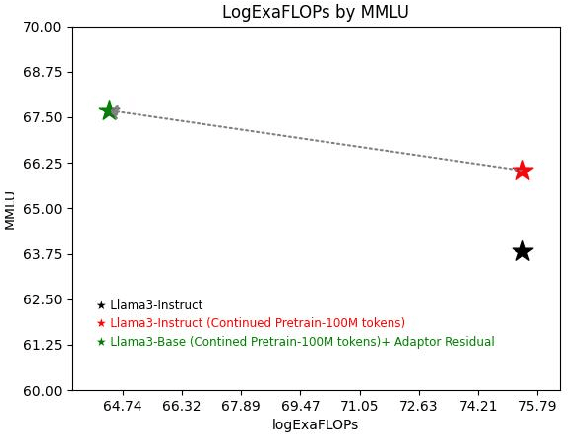
Large Language Models (LLMs) for public use require continuous pre-training to remain up-to-date with the latest data. The models also need to be fine-tuned with specific instructions to maintain their ability to follow instructions accurately. Typically, LLMs are released in two versions: the Base LLM, pre-trained on diverse data, and the instruction-refined LLM, additionally trained with specific instructions for better instruction following. The question arises as to which model should undergo continuous pre-training to maintain its instruction-following abilities while also staying current with the latest data. In this study, we delve into the intricate relationship between continuous pre-training and instruction fine-tuning of the LLMs and investigate the impact of continuous pre-training on the instruction following abilities of both the base and its instruction finetuned model. Further, the instruction fine-tuning process is computationally intense and requires a substantial number of hand-annotated examples for the model to learn effectively. This study aims to find the most compute-efficient strategy to gain up-to-date knowledge and instruction-following capabilities without requiring any instruction data and fine-tuning. We empirically prove our findings on the LLaMa 3, 3.1 and Qwen 2, 2.5 family of base and instruction models, providing a comprehensive exploration of our hypotheses across varying sizes of pre-training data corpus and different LLMs settings.
Beyond Labels: Empowering Human with Natural Language Explanations through a Novel Active-Learning Architecture
May 22, 2023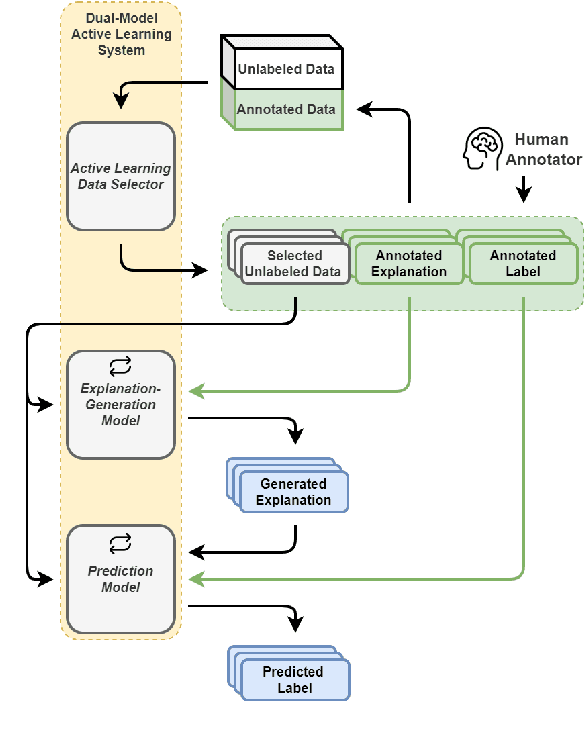
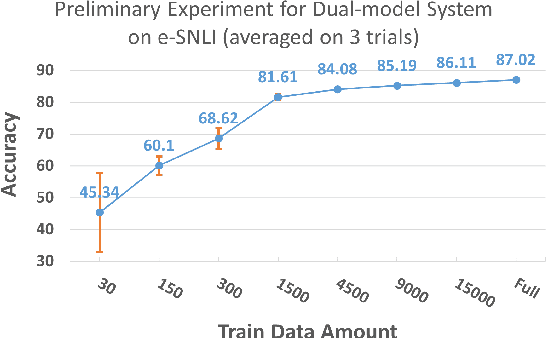

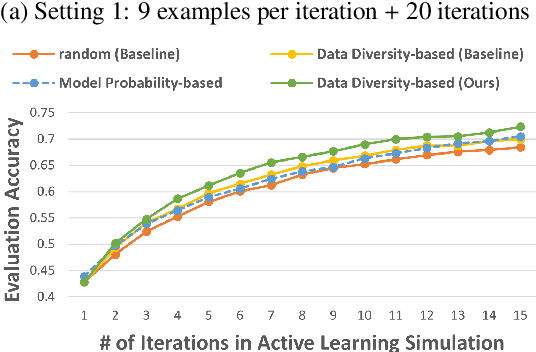
Data annotation is a costly task; thus, researchers have proposed low-scenario learning techniques like Active-Learning (AL) to support human annotators; Yet, existing AL works focus only on the label, but overlook the natural language explanation of a data point, despite that real-world humans (e.g., doctors) often need both the labels and the corresponding explanations at the same time. This work proposes a novel AL architecture to support and reduce human annotations of both labels and explanations in low-resource scenarios. Our AL architecture incorporates an explanation-generation model that can explicitly generate natural language explanations for the prediction model and for assisting humans' decision-making in real-world. For our AL framework, we design a data diversity-based AL data selection strategy that leverages the explanation annotations. The automated AL simulation evaluations demonstrate that our data selection strategy consistently outperforms traditional data diversity-based strategy; furthermore, human evaluation demonstrates that humans prefer our generated explanations to the SOTA explanation-generation system.
When to Use What: An In-Depth Comparative Empirical Analysis of OpenIE Systems for Downstream Applications
Nov 15, 2022



Open Information Extraction (OpenIE) has been used in the pipelines of various NLP tasks. Unfortunately, there is no clear consensus on which models to use in which tasks. Muddying things further is the lack of comparisons that take differing training sets into account. In this paper, we present an application-focused empirical survey of neural OpenIE models, training sets, and benchmarks in an effort to help users choose the most suitable OpenIE systems for their applications. We find that the different assumptions made by different models and datasets have a statistically significant effect on performance, making it important to choose the most appropriate model for one's applications. We demonstrate the applicability of our recommendations on a downstream Complex QA application.
PriMeSRL-Eval: A Practical Quality Metric for Semantic Role Labeling Systems Evaluation
Oct 12, 2022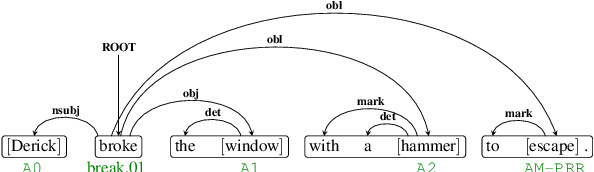
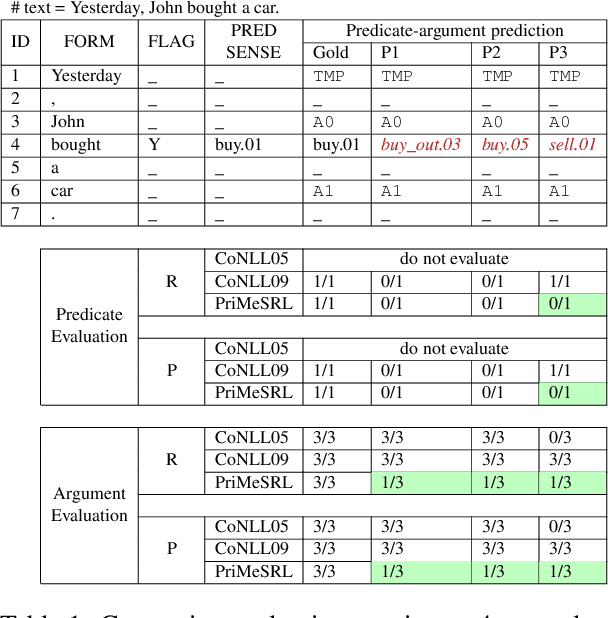
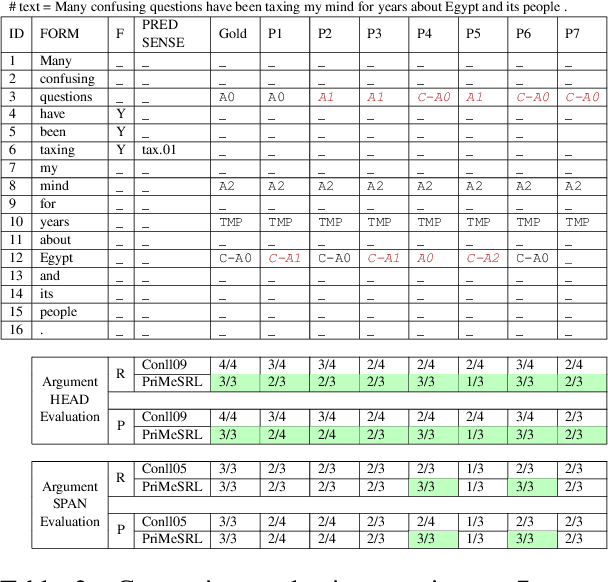
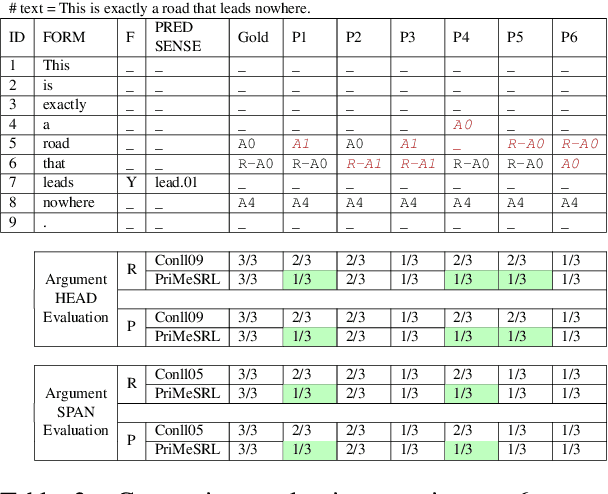
Semantic role labeling (SRL) identifies the predicate-argument structure in a sentence. This task is usually accomplished in four steps: predicate identification, predicate sense disambiguation, argument identification, and argument classification. Errors introduced at one step propagate to later steps. Unfortunately, the existing SRL evaluation scripts do not consider the full effect of this error propagation aspect. They either evaluate arguments independent of predicate sense (CoNLL09) or do not evaluate predicate sense at all (CoNLL05), yielding an inaccurate SRL model performance on the argument classification task. In this paper, we address key practical issues with existing evaluation scripts and propose a more strict SRL evaluation metric PriMeSRL. We observe that by employing PriMeSRL, the quality evaluation of all SoTA SRL models drops significantly, and their relative rankings also change. We also show that PriMeSRLsuccessfully penalizes actual failures in SoTA SRL models.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
OPAD: An Optimized Policy-based Active Learning Framework for Document Content Analysis
Oct 07, 2021
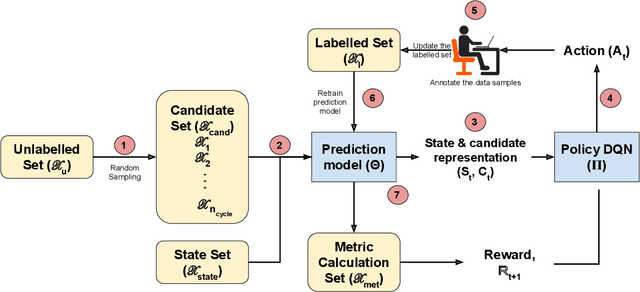
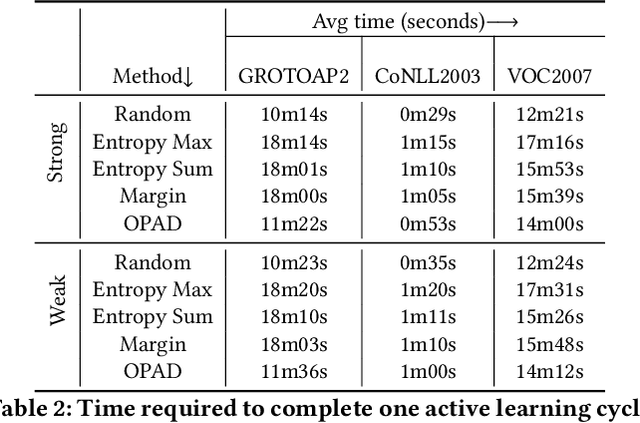
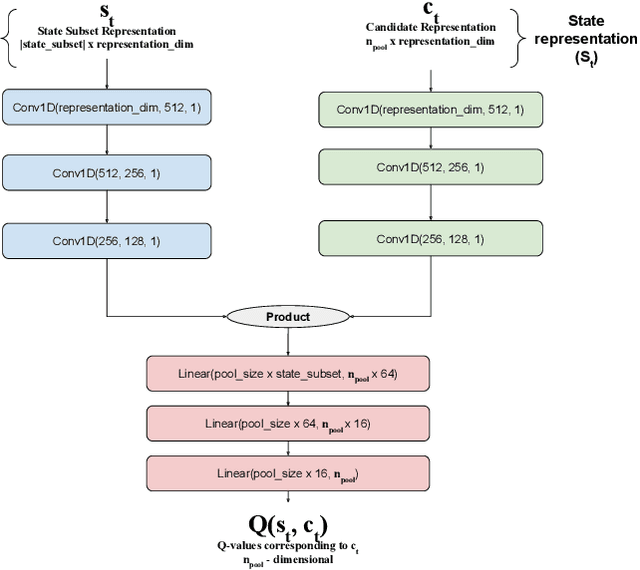
Documents are central to many business systems, and include forms, reports, contracts, invoices or purchase orders. The information in documents is typically in natural language, but can be organized in various layouts and formats. There have been recent spurt of interest in understanding document content with novel deep learning architectures. However, document understanding tasks need dense information annotations, which are costly to scale and generalize. Several active learning techniques have been proposed to reduce the overall budget of annotation while maintaining the performance of the underlying deep learning model. However, most of these techniques work only for classification problems. But content detection is a more complex task, and has been scarcely explored in active learning literature. In this paper, we propose \textit{OPAD}, a novel framework using reinforcement policy for active learning in content detection tasks for documents. The proposed framework learns the acquisition function to decide the samples to be selected while optimizing performance metrics that the tasks typically have. Furthermore, we extend to weak labelling scenarios to further reduce the cost of annotation significantly. We propose novel rewards to account for class imbalance and user feedback in the annotation interface, to improve the active learning method. We show superior performance of the proposed \textit{OPAD} framework for active learning for various tasks related to document understanding like layout parsing, object detection and named entity recognition. Ablation studies for human feedback and class imbalance rewards are presented, along with a comparison of annotation times for different approaches.
Improved Semantic Role Labeling using Parameterized Neighborhood Memory Adaptation
Nov 29, 2020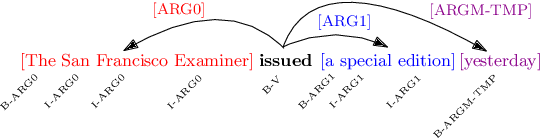
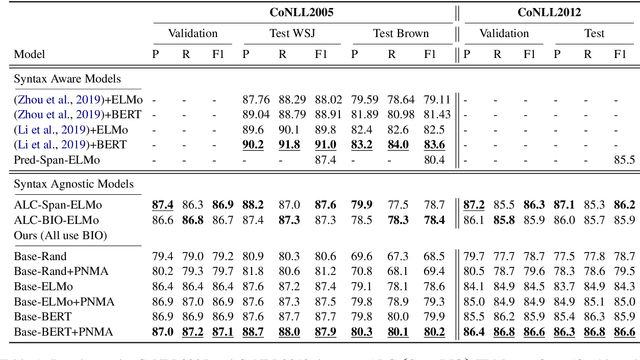
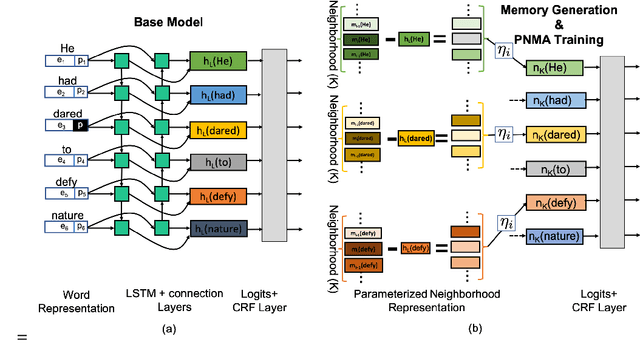
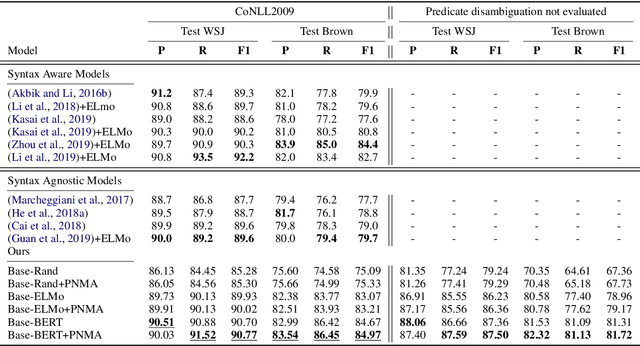
Deep neural models achieve some of the best results for semantic role labeling. Inspired by instance-based learning that utilizes nearest neighbors to handle low-frequency context-specific training samples, we investigate the use of memory adaptation techniques in deep neural models. We propose a parameterized neighborhood memory adaptive (PNMA) method that uses a parameterized representation of the nearest neighbors of tokens in a memory of activations and makes predictions based on the most similar samples in the training data. We empirically show that PNMA consistently improves the SRL performance of the base model irrespective of types of word embeddings. Coupled with contextualized word embeddings derived from BERT, PNMA improves over existing models for both span and dependency semantic parsing datasets, especially on out-of-domain text, reaching F1 scores of 80.2, and 84.97 on CoNLL2005, and CoNLL2009 datasets, respectively.
CLAR: A Cross-Lingual Argument Regularizer for Semantic Role Labeling
Nov 09, 2020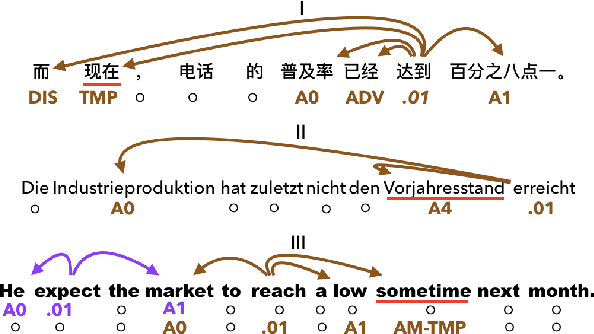



Semantic role labeling (SRL) identifies predicate-argument structure(s) in a given sentence. Although different languages have different argument annotations, polyglot training, the idea of training one model on multiple languages, has previously been shown to outperform monolingual baselines, especially for low resource languages. In fact, even a simple combination of data has been shown to be effective with polyglot training by representing the distant vocabularies in a shared representation space. Meanwhile, despite the dissimilarity in argument annotations between languages, certain argument labels do share common semantic meaning across languages (e.g. adjuncts have more or less similar semantic meaning across languages). To leverage such similarity in annotation space across languages, we propose a method called Cross-Lingual Argument Regularizer (CLAR). CLAR identifies such linguistic annotation similarity across languages and exploits this information to map the target language arguments using a transformation of the space on which source language arguments lie. By doing so, our experimental results show that CLAR consistently improves SRL performance on multiple languages over monolingual and polyglot baselines for low resource languages.
An Effective Label Noise Model for DNN Text Classification
Mar 18, 2019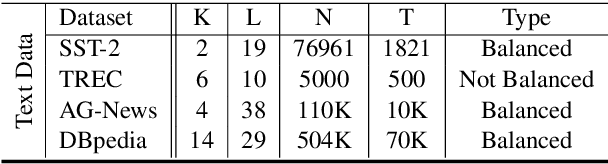
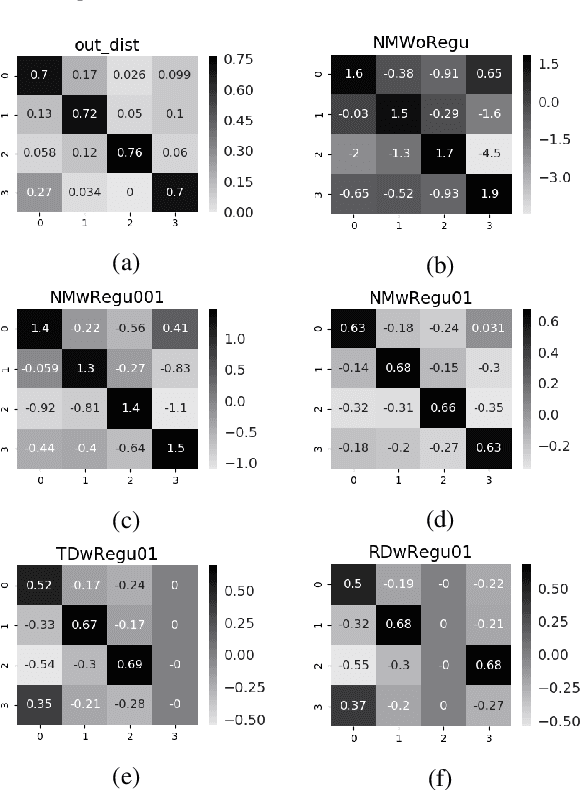
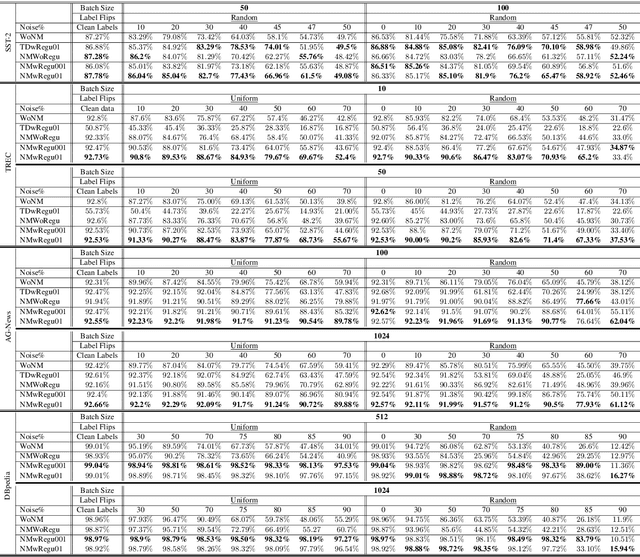
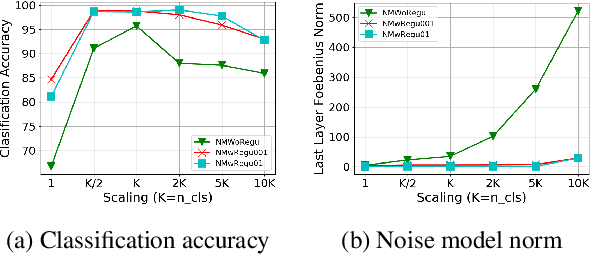
Because large, human-annotated datasets suffer from labeling errors, it is crucial to be able to train deep neural networks in the presence of label noise. While training image classification models with label noise have received much attention, training text classification models have not. In this paper, we propose an approach to training deep networks that is robust to label noise. This approach introduces a non-linear processing layer (noise model) that models the statistics of the label noise into a convolutional neural network (CNN) architecture. The noise model and the CNN weights are learned jointly from noisy training data, which prevents the model from overfitting to erroneous labels. Through extensive experiments on several text classification datasets, we show that this approach enables the CNN to learn better sentence representations and is robust even to extreme label noise. We find that proper initialization and regularization of this noise model is critical. Further, by contrast to results focusing on large batch sizes for mitigating label noise for image classification, we find that altering the batch size does not have much effect on classification performance.