 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Cross-stitched Multi-modal Encoders
Apr 20, 2022



In this paper, we propose a novel architecture for multi-modal speech and text input. We combine pretrained speech and text encoders using multi-headed cross-modal attention and jointly fine-tune on the target problem. The resultant architecture can be used for continuous token-level classification or utterance-level prediction acting on simultaneous text and speech. The resultant encoder efficiently captures both acoustic-prosodic and lexical information. We compare the benefits of multi-headed attention-based fusion for multi-modal utterance-level classification against a simple concatenation of pre-pooled, modality-specific representations. Our model architecture is compact, resource efficient, and can be trained on a single consumer GPU card.
Seq-2-Seq based Refinement of ASR Output for Spoken Name Capture
Mar 29, 2022
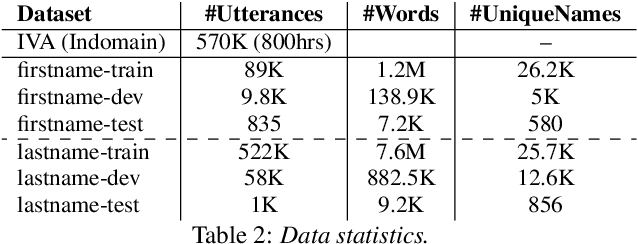

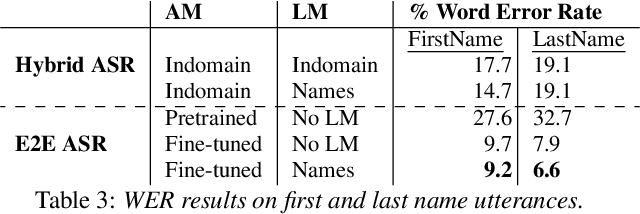
Person name capture from human speech is a difficult task in human-machine conversations. In this paper, we propose a novel approach to capture the person names from the caller utterances in response to the prompt "say and spell your first/last name". Inspired from work on spell correction, disfluency removal and text normalization, we propose a lightweight Seq-2-Seq system which generates a name spell from a varying user input. Our proposed method outperforms the strong baseline which is based on LM-driven rule-based approach.
Multiple Word Embeddings for Increased Diversity of Representation
Oct 09, 2020

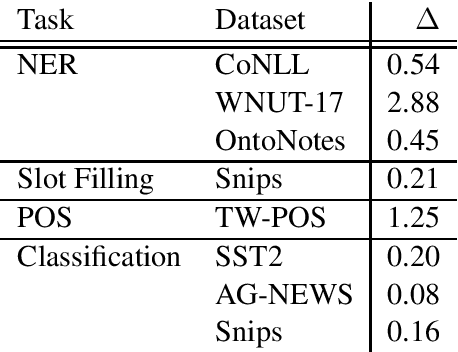

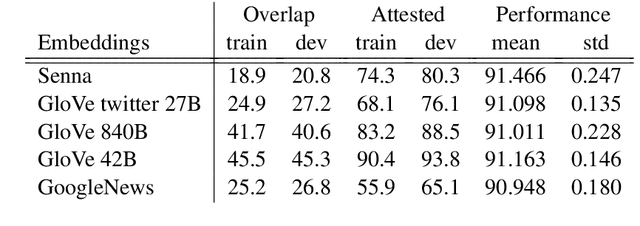
Most state-of-the-art models in natural language processing (NLP) are neural models built on top of large, pre-trained, contextual language models that generate representations of words in context and are fine-tuned for the task at hand. The improvements afforded by these "contextual embeddings" come with a high computational cost. In this work, we explore a simple technique that substantially and consistently improves performance over a strong baseline with negligible increase in run time. We concatenate multiple pre-trained embeddings to strengthen our representation of words. We show that this concatenation technique works across many tasks, datasets, and model types. We analyze aspects of pre-trained embedding similarity and vocabulary coverage and find that the representational diversity between different pre-trained embeddings is the driving force of why this technique works. We provide open source implementations of our models in both TensorFlow and PyTorch.
Constrained Decoding for Computationally Efficient Named Entity Recognition Taggers
Oct 09, 2020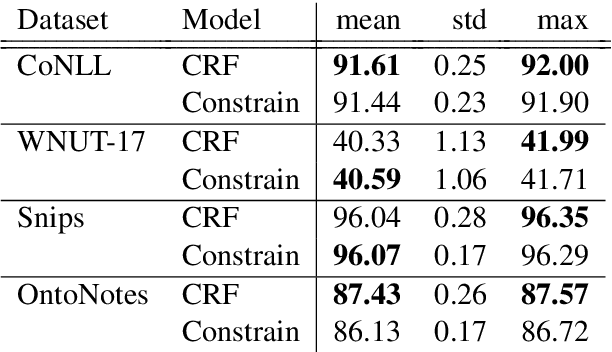
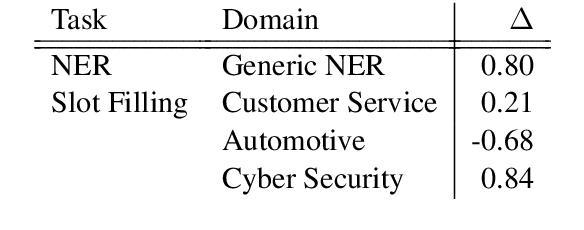

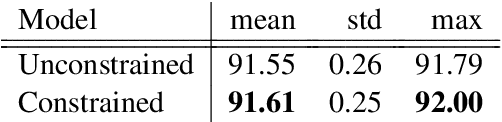
Current state-of-the-art models for named entity recognition (NER) are neural models with a conditional random field (CRF) as the final layer. Entities are represented as per-token labels with a special structure in order to decode them into spans. Current work eschews prior knowledge of how the span encoding scheme works and relies on the CRF learning which transitions are illegal and which are not to facilitate global coherence. We find that by constraining the output to suppress illegal transitions we can train a tagger with a cross-entropy loss twice as fast as a CRF with differences in F1 that are statistically insignificant, effectively eliminating the need for a CRF. We analyze the dynamics of tag co-occurrence to explain when these constraints are most effective and provide open source implementations of our tagger in both PyTorch and TensorFlow.
Computationally Efficient NER Taggers with Combined Embeddings and Constrained Decoding
Jan 05, 2020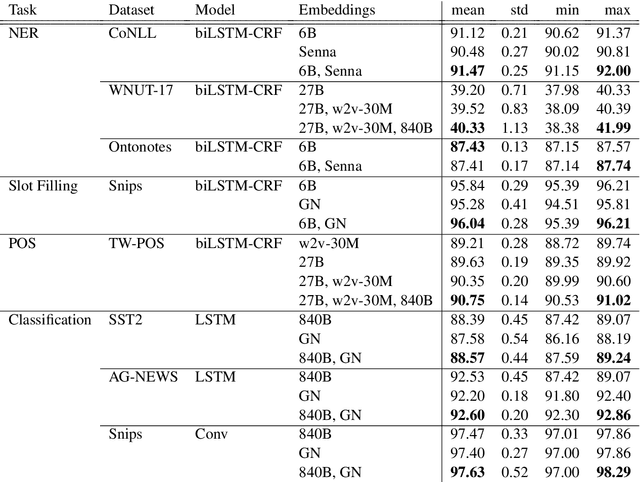
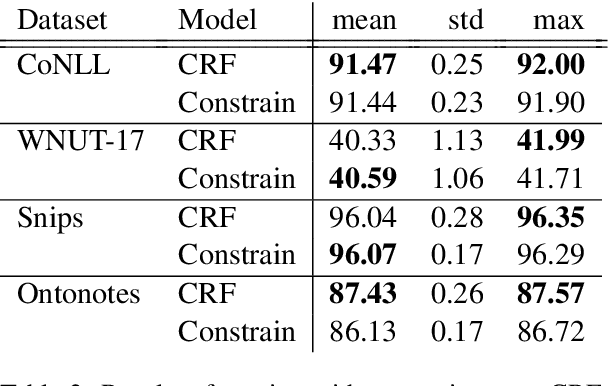
Current State-of-the-Art models in Named Entity Recognition (NER) are neural models with a Conditional Random Field (CRF) as the final network layer, and pre-trained "contextual embeddings". The CRF layer is used to facilitate global coherence between labels, and the contextual embeddings provide a better representation of words in context. However, both of these improvements come at a high computational cost. In this work, we explore two simple techniques that substantially improve NER performance over a strong baseline with negligible cost. First, we use multiple pre-trained embeddings as word representations via concatenation. Second, we constrain the tagger, trained using a cross-entropy loss, during decoding to eliminate illegal transitions. While training a tagger on CoNLL 2003 we find a $786$\% speed-up over a contextual embeddings-based tagger without sacrificing strong performance. We also show that the concatenation technique works across multiple tasks and datasets. We analyze aspects of similarity and coverage between pre-trained embeddings and the dynamics of tag co-occurrence to explain why these techniques work. We provide an open source implementation of our tagger using these techniques in three popular deep learning frameworks --- TensorFlow, Pytorch, and DyNet.
An Effective Label Noise Model for DNN Text Classification
Mar 18, 2019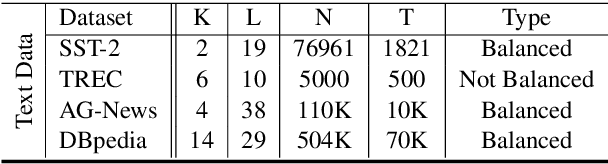
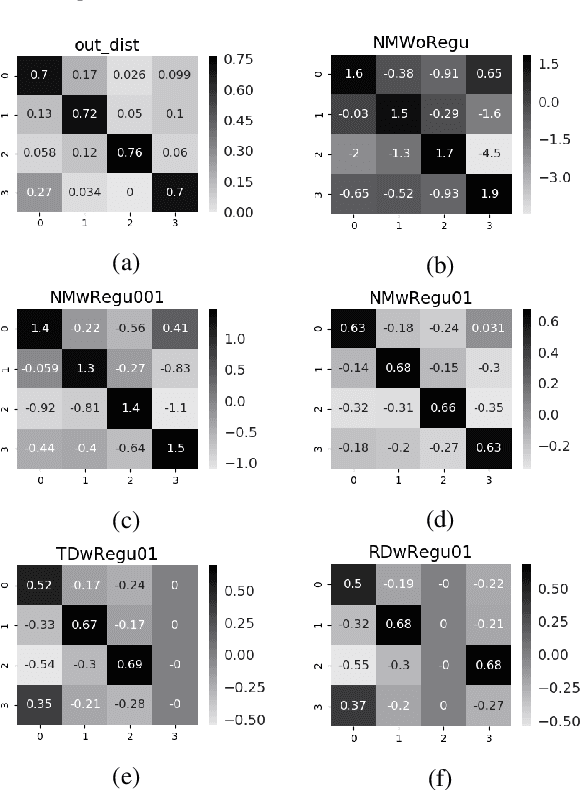
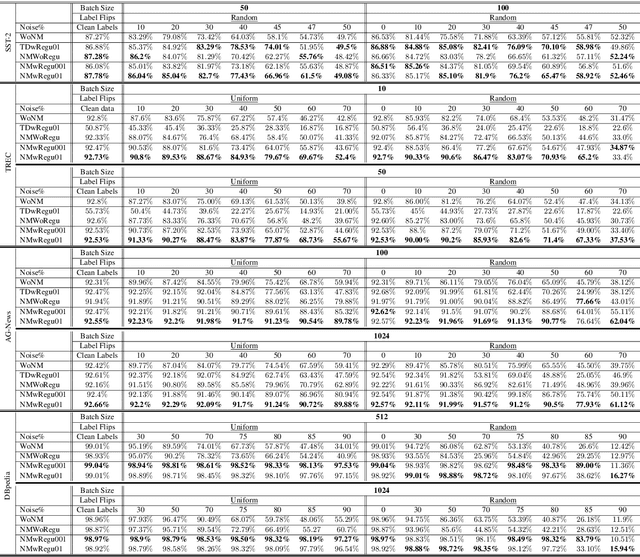
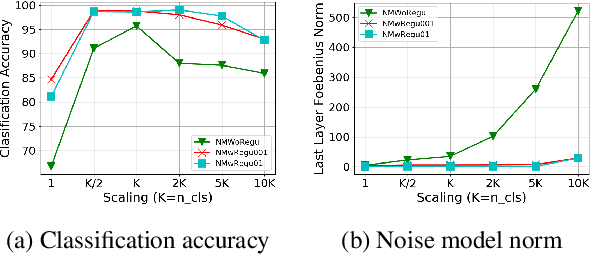
Because large, human-annotated datasets suffer from labeling errors, it is crucial to be able to train deep neural networks in the presence of label noise. While training image classification models with label noise have received much attention, training text classification models have not. In this paper, we propose an approach to training deep networks that is robust to label noise. This approach introduces a non-linear processing layer (noise model) that models the statistics of the label noise into a convolutional neural network (CNN) architecture. The noise model and the CNN weights are learned jointly from noisy training data, which prevents the model from overfitting to erroneous labels. Through extensive experiments on several text classification datasets, we show that this approach enables the CNN to learn better sentence representations and is robust even to extreme label noise. We find that proper initialization and regularization of this noise model is critical. Further, by contrast to results focusing on large batch sizes for mitigating label noise for image classification, we find that altering the batch size does not have much effect on classification performance.