 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Word Embeddings for Increased Diversity of Representation
Oct 09, 2020

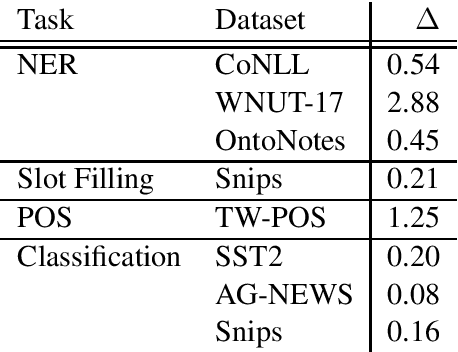

Most state-of-the-art models in natural language processing (NLP) are neural models built on top of large, pre-trained, contextual language models that generate representations of words in context and are fine-tuned for the task at hand. The improvements afforded by these "contextual embeddings" come with a high computational cost. In this work, we explore a simple technique that substantially and consistently improves performance over a strong baseline with negligible increase in run time. We concatenate multiple pre-trained embeddings to strengthen our representation of words. We show that this concatenation technique works across many tasks, datasets, and model types. We analyze aspects of pre-trained embedding similarity and vocabulary coverage and find that the representational diversity between different pre-trained embeddings is the driving force of why this technique works. We provide open source implementations of our models in both TensorFlow and PyTorch.
Constrained Decoding for Computationally Efficient Named Entity Recognition Taggers
Oct 09, 2020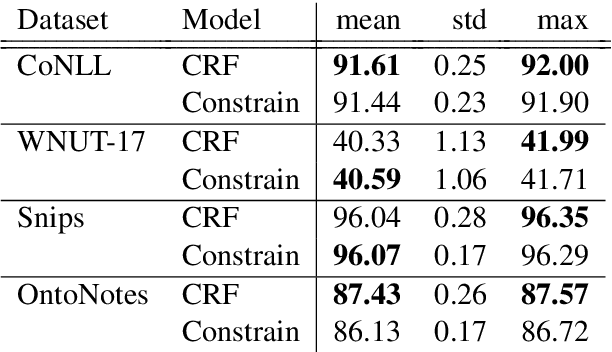
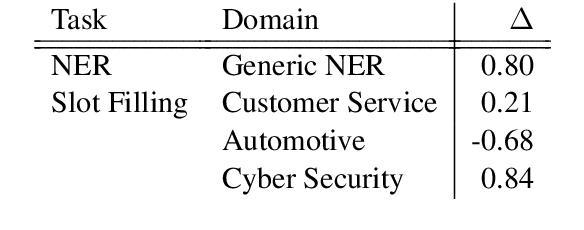

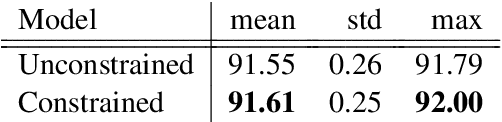
Current state-of-the-art models for named entity recognition (NER) are neural models with a conditional random field (CRF) as the final layer. Entities are represented as per-token labels with a special structure in order to decode them into spans. Current work eschews prior knowledge of how the span encoding scheme works and relies on the CRF learning which transitions are illegal and which are not to facilitate global coherence. We find that by constraining the output to suppress illegal transitions we can train a tagger with a cross-entropy loss twice as fast as a CRF with differences in F1 that are statistically insignificant, effectively eliminating the need for a CRF. We analyze the dynamics of tag co-occurrence to explain when these constraints are most effective and provide open source implementations of our tagger in both PyTorch and TensorFlow.
Computationally Efficient NER Taggers with Combined Embeddings and Constrained Decoding
Jan 05, 2020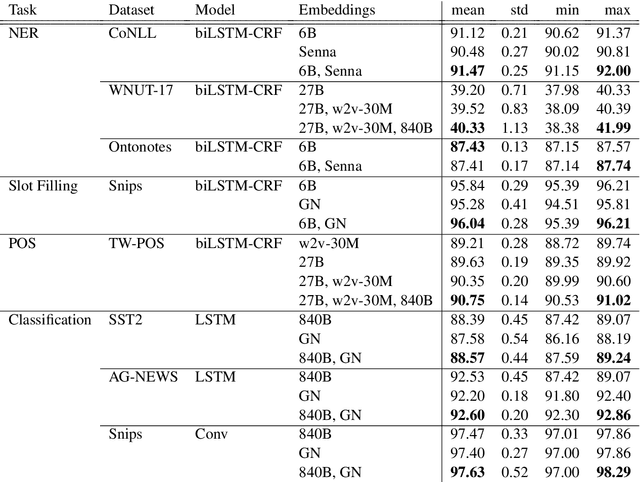
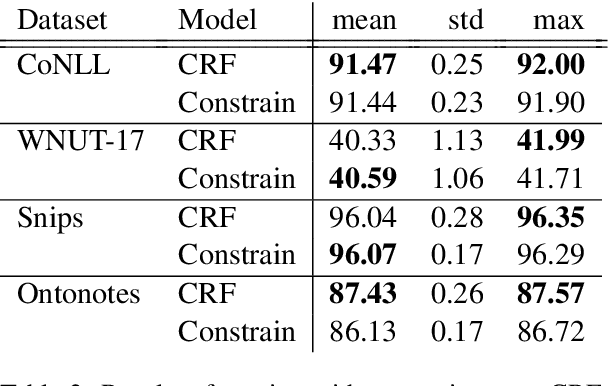
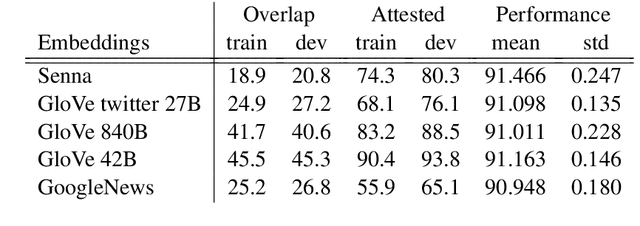
Current State-of-the-Art models in Named Entity Recognition (NER) are neural models with a Conditional Random Field (CRF) as the final network layer, and pre-trained "contextual embeddings". The CRF layer is used to facilitate global coherence between labels, and the contextual embeddings provide a better representation of words in context. However, both of these improvements come at a high computational cost. In this work, we explore two simple techniques that substantially improve NER performance over a strong baseline with negligible cost. First, we use multiple pre-trained embeddings as word representations via concatenation. Second, we constrain the tagger, trained using a cross-entropy loss, during decoding to eliminate illegal transitions. While training a tagger on CoNLL 2003 we find a $786$\% speed-up over a contextual embeddings-based tagger without sacrificing strong performance. We also show that the concatenation technique works across multiple tasks and datasets. We analyze aspects of similarity and coverage between pre-trained embeddings and the dynamics of tag co-occurrence to explain why these techniques work. We provide an open source implementation of our tagger using these techniques in three popular deep learning frameworks --- TensorFlow, Pytorch, and DyNet.