 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
BAGELS: Benchmarking the Automated Generation and Extraction of Limitations from Scholarly Text
May 22, 2025In scientific research, limitations refer to the shortcomings, constraints, or weaknesses within a study. Transparent reporting of such limitations can enhance the quality and reproducibility of research and improve public trust in science. However, authors often a) underreport them in the paper text and b) use hedging strategies to satisfy editorial requirements at the cost of readers' clarity and confidence. This underreporting behavior, along with an explosion in the number of publications, has created a pressing need to automatically extract or generate such limitations from scholarly papers. In this direction, we present a complete architecture for the computational analysis of research limitations. Specifically, we create a dataset of limitations in ACL, NeurIPS, and PeerJ papers by extracting them from papers' text and integrating them with external reviews; we propose methods to automatically generate them using a novel Retrieval Augmented Generation (RAG) technique; we create a fine-grained evaluation framework for generated limitations; and we provide a meta-evaluation for the proposed evaluation techniques.
Do Large Language Models Know Conflict? Investigating Parametric vs. Non-Parametric Knowledge of LLMs for Conflict Forecasting
May 14, 2025Large Language Models (LLMs) have shown impressive performance across natural language tasks, but their ability to forecast violent conflict remains underexplored. We investigate whether LLMs possess meaningful parametric knowledge-encoded in their pretrained weights-to predict conflict escalation and fatalities without external data. This is critical for early warning systems, humanitarian planning, and policy-making. We compare this parametric knowledge with non-parametric capabilities, where LLMs access structured and unstructured context from conflict datasets (e.g., ACLED, GDELT) and recent news reports via Retrieval-Augmented Generation (RAG). Incorporating external information could enhance model performance by providing up-to-date context otherwise missing from pretrained weights. Our two-part evaluation framework spans 2020-2024 across conflict-prone regions in the Horn of Africa and the Middle East. In the parametric setting, LLMs predict conflict trends and fatalities relying only on pretrained knowledge. In the non-parametric setting, models receive summaries of recent conflict events, indicators, and geopolitical developments. We compare predicted conflict trend labels (e.g., Escalate, Stable Conflict, De-escalate, Peace) and fatalities against historical data. Our findings highlight the strengths and limitations of LLMs for conflict forecasting and the benefits of augmenting them with structured external knowledge.
Towards Automated Situation Awareness: A RAG-Based Framework for Peacebuilding Reports
May 14, 2025Timely and accurate situation awareness is vital for decision-making in humanitarian response, conflict monitoring, and early warning and early action. However, the manual analysis of vast and heterogeneous data sources often results in delays, limiting the effectiveness of interventions. This paper introduces a dynamic Retrieval-Augmented Generation (RAG) system that autonomously generates situation awareness reports by integrating real-time data from diverse sources, including news articles, conflict event databases, and economic indicators. Our system constructs query-specific knowledge bases on demand, ensuring timely, relevant, and accurate insights. To ensure the quality of generated reports, we propose a three-level evaluation framework that combines semantic similarity metrics, factual consistency checks, and expert feedback. The first level employs automated NLP metrics to assess coherence and factual accuracy. The second level involves human expert evaluation to verify the relevance and completeness of the reports. The third level utilizes LLM-as-a-Judge, where large language models provide an additional layer of assessment to ensure robustness. The system is tested across multiple real-world scenarios, demonstrating its effectiveness in producing coherent, insightful, and actionable reports. By automating report generation, our approach reduces the burden on human analysts and accelerates decision-making processes. To promote reproducibility and further research, we openly share our code and evaluation tools with the community via GitHub.
FutureGen: LLM-RAG Approach to Generate the Future Work of Scientific Article
Mar 20, 2025
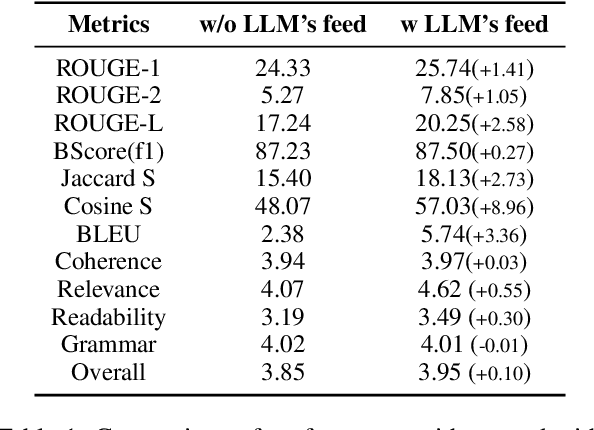
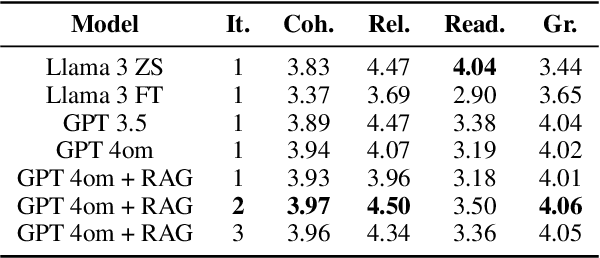
The future work section of a scientific article outlines potential research directions by identifying gaps and limitations of a current study. This section serves as a valuable resource for early-career researchers seeking unexplored areas and experienced researchers looking for new projects or collaborations. In this study, we generate future work suggestions from key sections of a scientific article alongside related papers and analyze how the trends have evolved. We experimented with various Large Language Models (LLMs) and integrated Retrieval-Augmented Generation (RAG) to enhance the generation process. We incorporate a LLM feedback mechanism to improve the quality of the generated content and propose an LLM-as-a-judge approach for evaluation. Our results demonstrated that the RAG-based approach with LLM feedback outperforms other methods evaluated through qualitative and quantitative metrics. Moreover, we conduct a human evaluation to assess the LLM as an extractor and judge. The code and dataset for this project are here, code: HuggingFace
Explaining Interactions Between Text Spans
Oct 20, 2023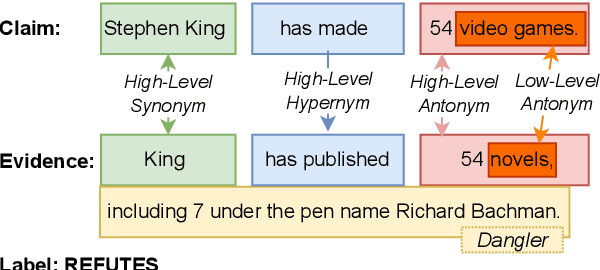
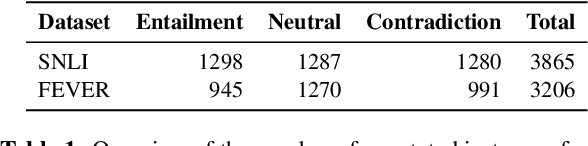
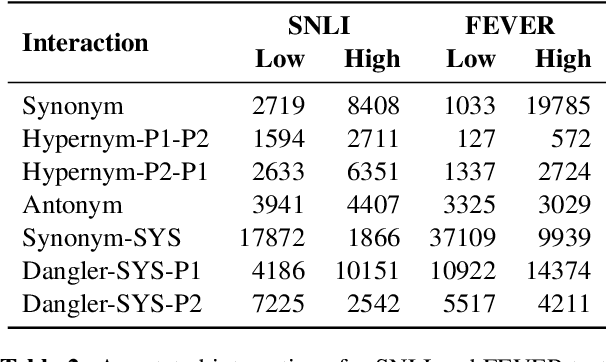
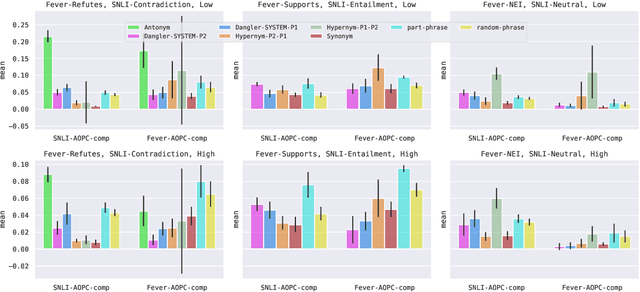
Reasoning over spans of tokens from different parts of the input is essential for natural language understanding (NLU) tasks such as fact-checking (FC), machine reading comprehension (MRC) or natural language inference (NLI). However, existing highlight-based explanations primarily focus on identifying individual important tokens or interactions only between adjacent tokens or tuples of tokens. Most notably, there is a lack of annotations capturing the human decision-making process w.r.t. the necessary interactions for informed decision-making in such tasks. To bridge this gap, we introduce SpanEx, a multi-annotator dataset of human span interaction explanations for two NLU tasks: NLI and FC. We then investigate the decision-making processes of multiple fine-tuned large language models in terms of the employed connections between spans in separate parts of the input and compare them to the human reasoning processes. Finally, we present a novel community detection based unsupervised method to extract such interaction explanations from a model's inner workings.
Implications of Annotation Artifacts in Edge Probing Test Datasets
Oct 20, 2023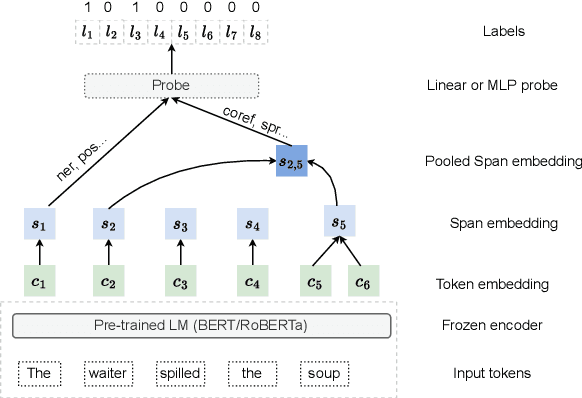
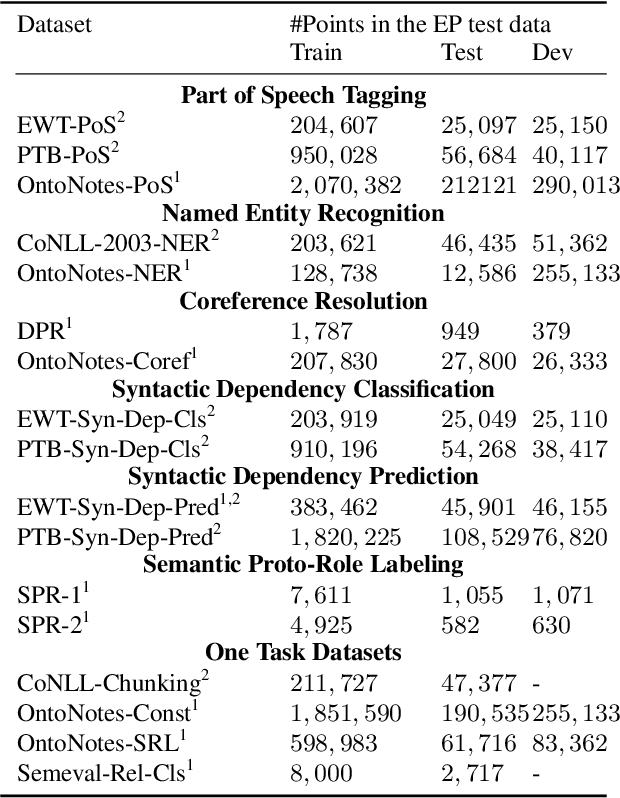
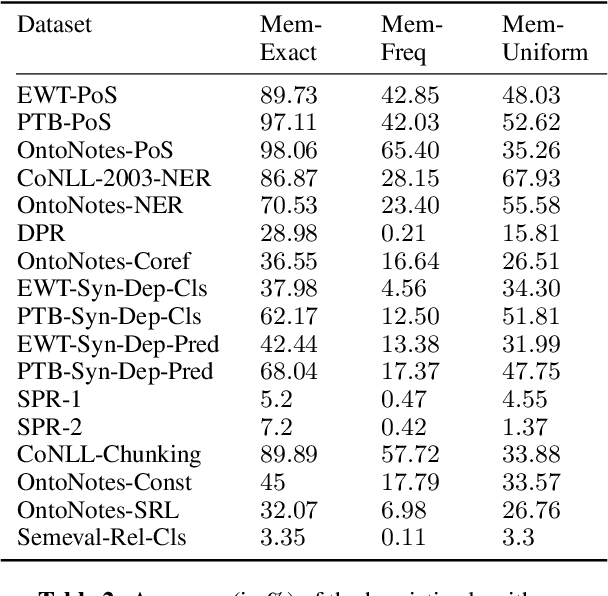
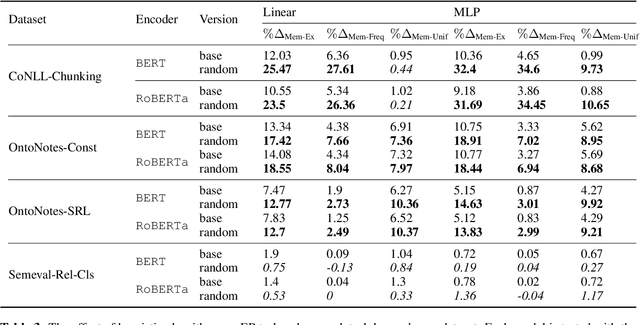
Edge probing tests are classification tasks that test for grammatical knowledge encoded in token representations coming from contextual encoders such as large language models (LLMs). Many LLM encoders have shown high performance in EP tests, leading to conjectures about their ability to encode linguistic knowledge. However, a large body of research claims that the tests necessarily do not measure the LLM's capacity to encode knowledge, but rather reflect the classifiers' ability to learn the problem. Much of this criticism stems from the fact that often the classifiers have very similar accuracy when an LLM vs a random encoder is used. Consequently, several modifications to the tests have been suggested, including information theoretic probes. We show that commonly used edge probing test datasets have various biases including memorization. When these biases are removed, the LLM encoders do show a significant difference from the random ones, even with the simple non-information theoretic probes.
Machine Reading, Fast and Slow: When Do Models "Understand" Language?
Sep 15, 2022



Two of the most fundamental challenges in Natural Language Understanding (NLU) at present are: (a) how to establish whether deep learning-based models score highly on NLU benchmarks for the 'right' reasons; and (b) to understand what those reasons would even be. We investigate the behavior of reading comprehension models with respect to two linguistic 'skills': coreference resolution and comparison. We propose a definition for the reasoning steps expected from a system that would be 'reading slowly', and compare that with the behavior of five models of the BERT family of various sizes, observed through saliency scores and counterfactual explanations. We find that for comparison (but not coreference) the systems based on larger encoders are more likely to rely on the 'right' information, but even they struggle with generalization, suggesting that they still learn specific lexical patterns rather than the general principles of comparison.
Can Edge Probing Tasks Reveal Linguistic Knowledge in QA Models?
Sep 18, 2021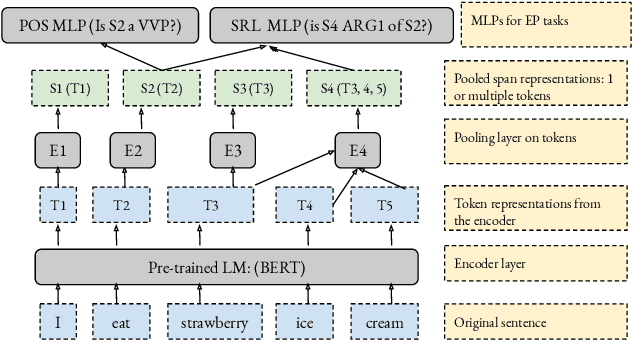
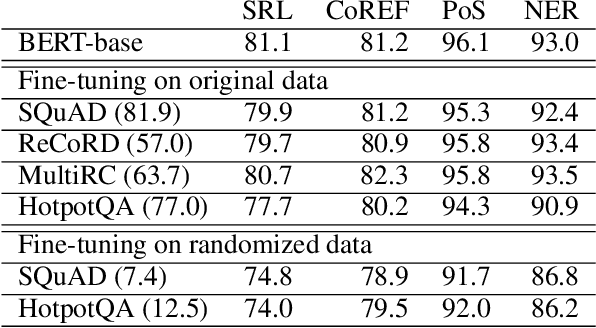
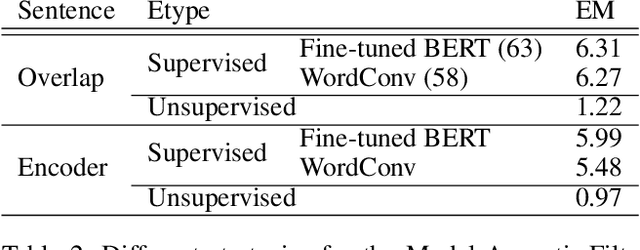
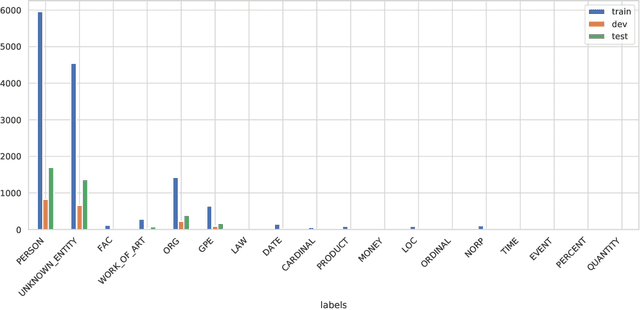
There have been many efforts to try to understand what gram-matical knowledge (e.g., ability to understand the part of speech of a token) is encoded in large pre-trained language models (LM). This is done through 'Edge Probing' (EP) tests: simple ML models that predict the grammatical properties ofa span (whether it has a particular part of speech) using only the LM's token representations. However, most NLP applications use fine-tuned LMs. Here, we ask: if a LM is fine-tuned, does the encoding of linguistic information in it change, as measured by EP tests? Conducting experiments on multiple question-answering (QA) datasets, we answer that question negatively: the EP test results do not change significantly when the fine-tuned QA model performs well or in adversarial situations where the model is forced to learn wrong correlations. However, a critical analysis of the EP task datasets reveals that EP models may rely on spurious correlations to make predictions. This indicates even if fine-tuning changes the encoding of such knowledge, the EP tests might fail to measure it.
Intent Features for Rich Natural Language Understanding
Apr 21, 2021
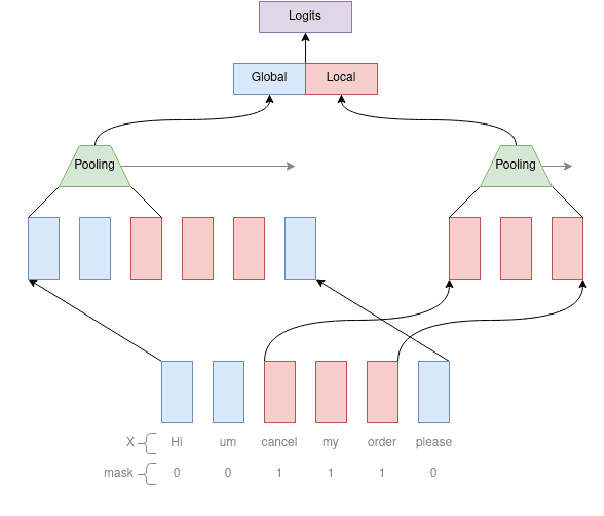

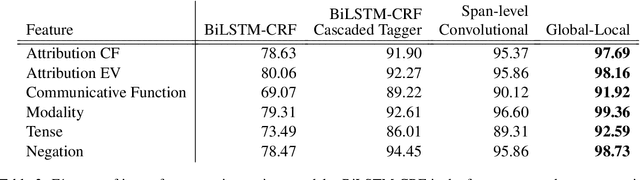
Complex natural language understanding modules in dialog systems have a richer understanding of user utterances, and thus are critical in providing a better user experience. However, these models are often created from scratch, for specific clients and use cases, and require the annotation of large datasets. This encourages the sharing of annotated data across multiple clients. To facilitate this we introduce the idea of intent features: domain and topic agnostic properties of intents that can be learned from the syntactic cues only, and hence can be shared. We introduce a new neural network architecture, the Global-Local model, that shows significant improvement over strong baselines for identifying these features in a deployed, multi-intent natural language understanding module, and, more generally, in a classification setting where a part of an utterance has to be classified utilizing the whole context.