 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplications of Annotation Artifacts in Edge Probing Test Datasets
Paper and Code
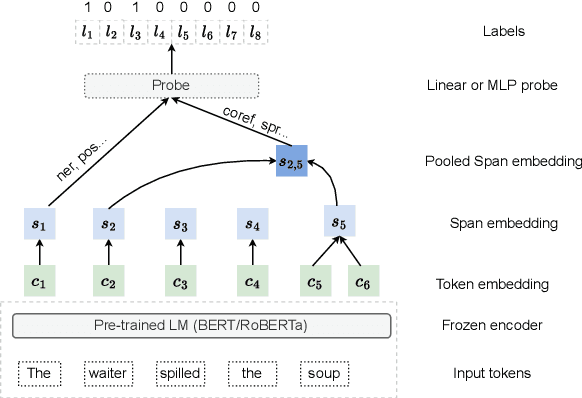
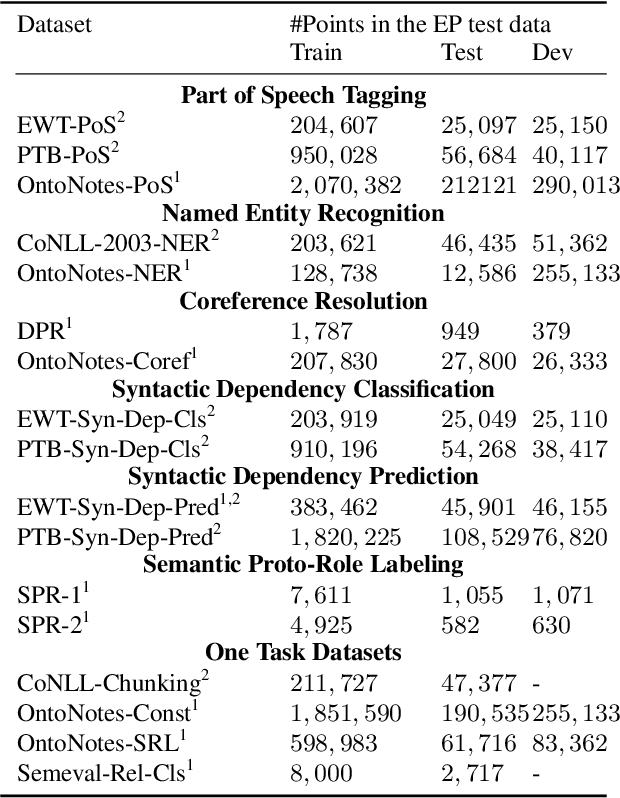
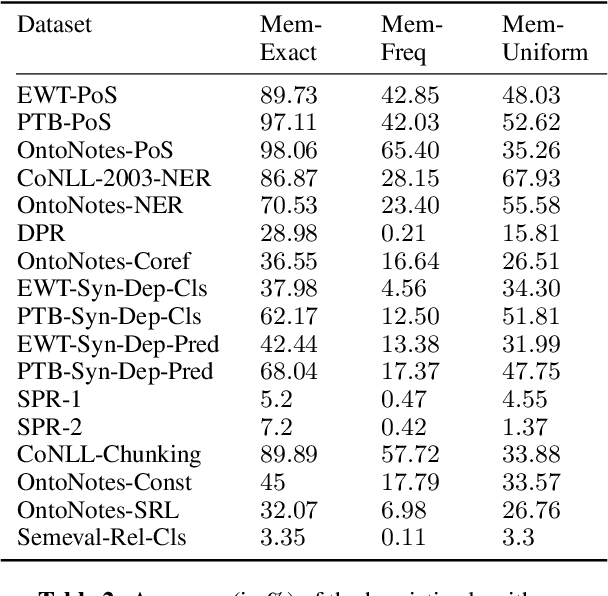
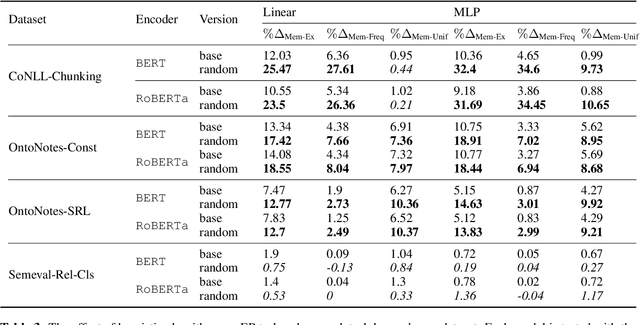
Edge probing tests are classification tasks that test for grammatical knowledge encoded in token representations coming from contextual encoders such as large language models (LLMs). Many LLM encoders have shown high performance in EP tests, leading to conjectures about their ability to encode linguistic knowledge. However, a large body of research claims that the tests necessarily do not measure the LLM's capacity to encode knowledge, but rather reflect the classifiers' ability to learn the problem. Much of this criticism stems from the fact that often the classifiers have very similar accuracy when an LLM vs a random encoder is used. Consequently, several modifications to the tests have been suggested, including information theoretic probes. We show that commonly used edge probing test datasets have various biases including memorization. When these biases are removed, the LLM encoders do show a significant difference from the random ones, even with the simple non-information theoretic probes.