 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Edge Probing Tasks Reveal Linguistic Knowledge in QA Models?
Paper and Code
Sep 18, 2021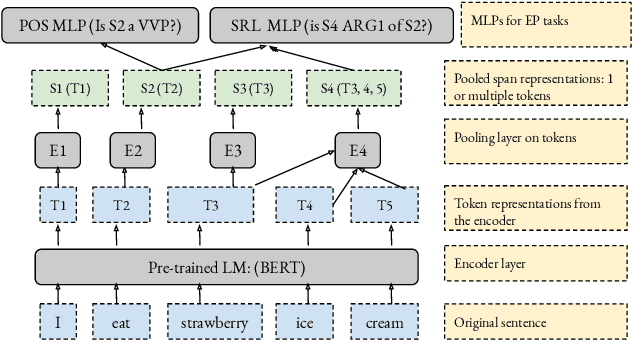
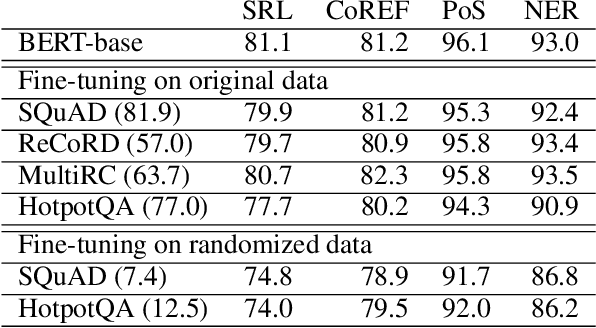
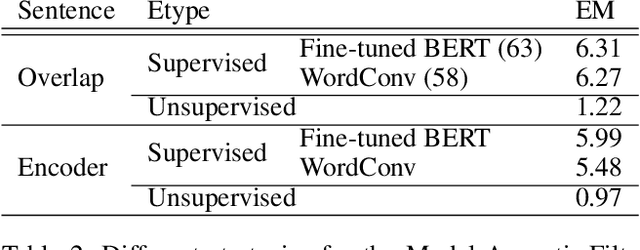
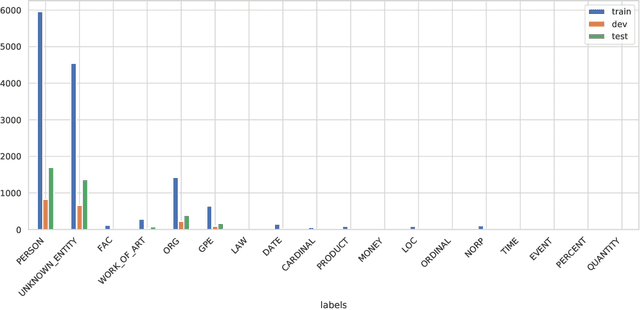
There have been many efforts to try to understand what gram-matical knowledge (e.g., ability to understand the part of speech of a token) is encoded in large pre-trained language models (LM). This is done through 'Edge Probing' (EP) tests: simple ML models that predict the grammatical properties ofa span (whether it has a particular part of speech) using only the LM's token representations. However, most NLP applications use fine-tuned LMs. Here, we ask: if a LM is fine-tuned, does the encoding of linguistic information in it change, as measured by EP tests? Conducting experiments on multiple question-answering (QA) datasets, we answer that question negatively: the EP test results do not change significantly when the fine-tuned QA model performs well or in adversarial situations where the model is forced to learn wrong correlations. However, a critical analysis of the EP task datasets reveals that EP models may rely on spurious correlations to make predictions. This indicates even if fine-tuning changes the encoding of such knowledge, the EP tests might fail to measure it.