 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Multi-Site Clinical Data: A Federated Approach to Privacy-First Child Autism Behavior Analysis
Apr 03, 2026Automated recognition of autistic behaviors in children is essential for early intervention and objective clinical assessment. However, the development of robust models is severely hindered by strict privacy regulations (e.g., HIPAA) and the sensitive nature of pediatric data, which prevents the centralized aggregation of clinical datasets. Furthermore, individual clinical sites often suffer from data scarcity, making it difficult to learn generalized behavior patterns or tailor models to site-specific patient distributions. To address these challenges, we observe that Federated Learning (FL) can decouple model training from raw data access, enabling multi-site collaboration while maintaining strict data residency. In this paper, we present the first study exploring Federated Learning for pose-based child autism behavior recognition. Our framework employs a two-layer privacy protection mechanism: utilizing human skeletal abstraction to remove identifiable visual information from the raw RGB videos and FL to ensure sensitive pose data remains within the clinic. This approach leverages distributed clinical data to learn generalized representations while providing the flexibility for site-specific personalization. Experimental results on the MMASD benchmark demonstrate that our framework achieves high recognition accuracy, outperforming traditional federated baselines and providing a robust, privacy-first solution for multi-site clinical analysis.
KHMP: Frequency-Domain Kalman Refinement for High-Fidelity Human Motion Prediction
Mar 22, 2026Stochastic human motion prediction aims to generate diverse, plausible futures from observed sequences. Despite advances in generative modeling, existing methods often produce predictions corrupted by high-frequency jitter and temporal discontinuities. To address these challenges, we introduce KHMP, a novel framework featuring an adaptiveKalman filter applied in the DCT domain to generate high-fidelity human motion predictions. By treating high-frequency DCT coefficients as a frequency-indexed noisy signal, the Kalman filter recursively suppresses noise while preserving motion details. Notably, its noise parameters are dynamically adjusted based on estimated Signal-to-Noise Ratio (SNR), enabling aggressive denoising for jittery predictions and conservative filtering for clean motions. This refinement is complemented by training-time physical constraints (temporal smoothness and joint angle limits) that encode biomechanical principles into the generative model. Together, these innovations establish a new paradigm integrating adaptive signal processing with physics-informed learning. Experiments on the Human3.6M and HumanEva-I datasets demonstrate that KHMP achieves state-of-the-art accuracy, effectively mitigating jitter artifacts to produce smooth and physically plausible motions.
Communication-Efficient Federated AUC Maximization with Cyclic Client Participation
Jan 04, 2026Federated AUC maximization is a powerful approach for learning from imbalanced data in federated learning (FL). However, existing methods typically assume full client availability, which is rarely practical. In real-world FL systems, clients often participate in a cyclic manner: joining training according to a fixed, repeating schedule. This setting poses unique optimization challenges for the non-decomposable AUC objective. This paper addresses these challenges by developing and analyzing communication-efficient algorithms for federated AUC maximization under cyclic client participation. We investigate two key settings: First, we study AUC maximization with a squared surrogate loss, which reformulates the problem as a nonconvex-strongly-concave minimax optimization. By leveraging the Polyak-Łojasiewicz (PL) condition, we establish a state-of-the-art communication complexity of $\widetilde{O}(1/ε^{1/2})$ and iteration complexity of $\widetilde{O}(1/ε)$. Second, we consider general pairwise AUC losses. We establish a communication complexity of $O(1/ε^3)$ and an iteration complexity of $O(1/ε^4)$. Further, under the PL condition, these bounds improve to communication complexity of $\widetilde{O}(1/ε^{1/2})$ and iteration complexity of $\widetilde{O}(1/ε)$. Extensive experiments on benchmark tasks in image classification, medical imaging, and fraud detection demonstrate the superior efficiency and effectiveness of our proposed methods.
UniSTFormer: Unified Spatio-Temporal Lightweight Transformer for Efficient Skeleton-Based Action Recognition
Aug 12, 2025



Skeleton-based action recognition (SAR) has achieved impressive progress with transformer architectures. However, existing methods often rely on complex module compositions and heavy designs, leading to increased parameter counts, high computational costs, and limited scalability. In this paper, we propose a unified spatio-temporal lightweight transformer framework that integrates spatial and temporal modeling within a single attention module, eliminating the need for separate temporal modeling blocks. This approach reduces redundant computations while preserving temporal awareness within the spatial modeling process. Furthermore, we introduce a simplified multi-scale pooling fusion module that combines local and global pooling pathways to enhance the model's ability to capture fine-grained local movements and overarching global motion patterns. Extensive experiments on benchmark datasets demonstrate that our lightweight model achieves a superior balance between accuracy and efficiency, reducing parameter complexity by over 58% and lowering computational cost by over 60% compared to state-of-the-art transformer-based baselines, while maintaining competitive recognition performance.
BAGELS: Benchmarking the Automated Generation and Extraction of Limitations from Scholarly Text
May 22, 2025In scientific research, limitations refer to the shortcomings, constraints, or weaknesses within a study. Transparent reporting of such limitations can enhance the quality and reproducibility of research and improve public trust in science. However, authors often a) underreport them in the paper text and b) use hedging strategies to satisfy editorial requirements at the cost of readers' clarity and confidence. This underreporting behavior, along with an explosion in the number of publications, has created a pressing need to automatically extract or generate such limitations from scholarly papers. In this direction, we present a complete architecture for the computational analysis of research limitations. Specifically, we create a dataset of limitations in ACL, NeurIPS, and PeerJ papers by extracting them from papers' text and integrating them with external reviews; we propose methods to automatically generate them using a novel Retrieval Augmented Generation (RAG) technique; we create a fine-grained evaluation framework for generated limitations; and we provide a meta-evaluation for the proposed evaluation techniques.
FutureGen: LLM-RAG Approach to Generate the Future Work of Scientific Article
Mar 20, 2025
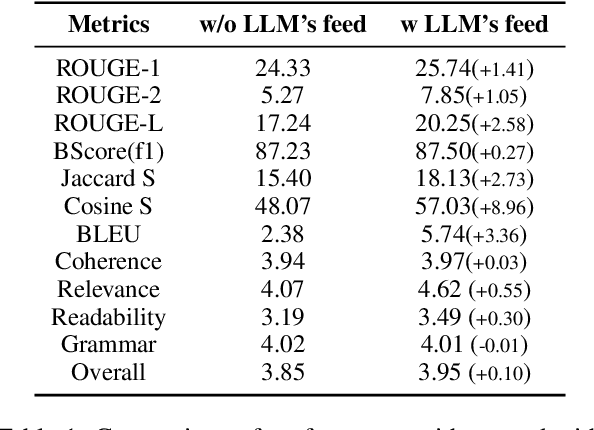
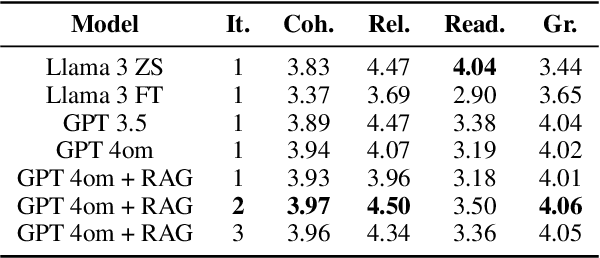
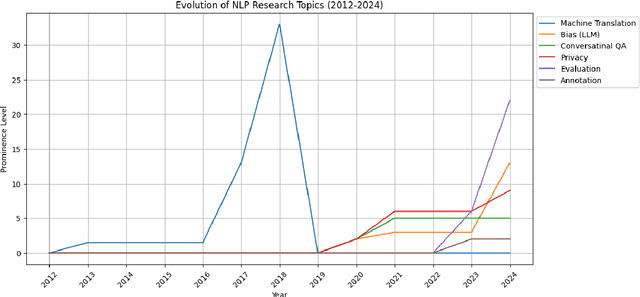
The future work section of a scientific article outlines potential research directions by identifying gaps and limitations of a current study. This section serves as a valuable resource for early-career researchers seeking unexplored areas and experienced researchers looking for new projects or collaborations. In this study, we generate future work suggestions from key sections of a scientific article alongside related papers and analyze how the trends have evolved. We experimented with various Large Language Models (LLMs) and integrated Retrieval-Augmented Generation (RAG) to enhance the generation process. We incorporate a LLM feedback mechanism to improve the quality of the generated content and propose an LLM-as-a-judge approach for evaluation. Our results demonstrated that the RAG-based approach with LLM feedback outperforms other methods evaluated through qualitative and quantitative metrics. Moreover, we conduct a human evaluation to assess the LLM as an extractor and judge. The code and dataset for this project are here, code: HuggingFace
Communication-Efficient Federated Group Distributionally Robust Optimization
Oct 08, 2024Federated learning faces challenges due to the heterogeneity in data volumes and distributions at different clients, which can compromise model generalization ability to various distributions. Existing approaches to address this issue based on group distributionally robust optimization (GDRO) often lead to high communication and sample complexity. To this end, this work introduces algorithms tailored for communication-efficient Federated Group Distributionally Robust Optimization (FGDRO). Our contributions are threefold: Firstly, we introduce the FGDRO-CVaR algorithm, which optimizes the average top-K losses while reducing communication complexity to $O(1/\epsilon^4)$, where $\epsilon$ denotes the desired precision level. Secondly, our FGDRO-KL algorithm is crafted to optimize KL regularized FGDRO, cutting communication complexity to $O(1/\epsilon^3)$. Lastly, we propose FGDRO-KL-Adam to utilize Adam-type local updates in FGDRO-KL, which not only maintains a communication cost of $O(1/\epsilon^3)$ but also shows potential to surpass SGD-type local steps in practical applications. The effectiveness of our algorithms has been demonstrated on a variety of real-world tasks, including natural language processing and computer vision.
Blockwise Stochastic Variance-Reduced Methods with Parallel Speedup for Multi-Block Bilevel Optimization
Jun 02, 2023
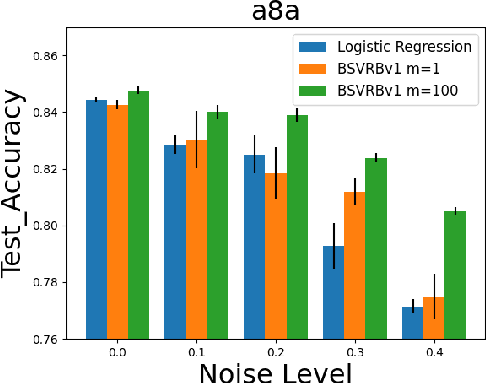
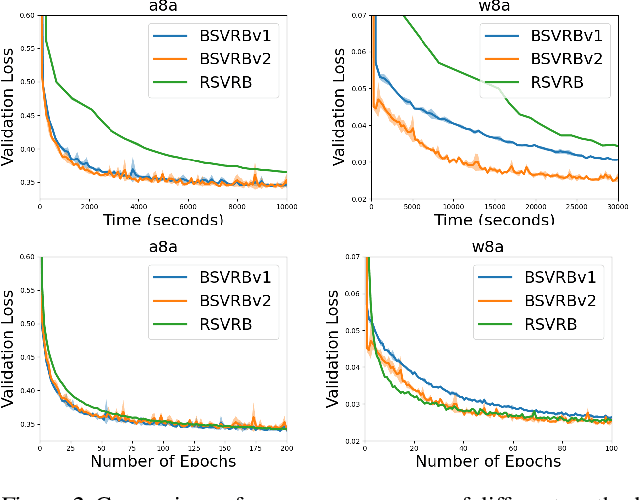
In this paper, we consider non-convex multi-block bilevel optimization (MBBO) problems, which involve $m\gg 1$ lower level problems and have important applications in machine learning. Designing a stochastic gradient and controlling its variance is more intricate due to the hierarchical sampling of blocks and data and the unique challenge of estimating hyper-gradient. We aim to achieve three nice properties for our algorithm: (a) matching the state-of-the-art complexity of standard BO problems with a single block; (b) achieving parallel speedup by sampling $I$ blocks and sampling $B$ samples for each sampled block per-iteration; (c) avoiding the computation of the inverse of a high-dimensional Hessian matrix estimator. However, it is non-trivial to achieve all of these by observing that existing works only achieve one or two of these properties. To address the involved challenges for achieving (a, b, c), we propose two stochastic algorithms by using advanced blockwise variance-reduction techniques for tracking the Hessian matrices (for low-dimensional problems) or the Hessian-vector products (for high-dimensional problems), and prove an iteration complexity of $O(\frac{m\epsilon^{-3}\mathbb{I}(I<m)}{I\sqrt{I}} + \frac{m\epsilon^{-3}}{I\sqrt{B}})$ for finding an $\epsilon$-stationary point under appropriate conditions. We also conduct experiments to verify the effectiveness of the proposed algorithms comparing with existing MBBO algorithms.
FedX: Federated Learning for Compositional Pairwise Risk Optimization
Oct 26, 2022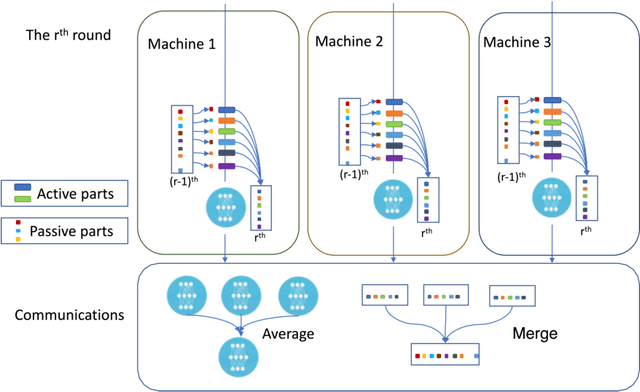

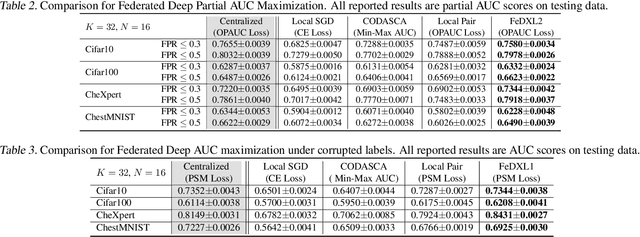
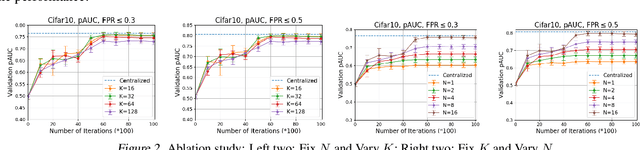
In this paper, we tackle a novel federated learning (FL) problem for optimizing a family of compositional pairwise risks, to which no existing FL algorithms are applicable. In particular, the objective has the form of $\mathbb E_{\mathbf z\sim \mathcal S_1} f(\mathbb E_{\mathbf z'\sim\mathcal S_2} \ell(\mathbf w, \mathbf z, \mathbf z'))$, where two sets of data $\mathcal S_1, \mathcal S_2$ are distributed over multiple machines, $\ell(\cdot; \cdot,\cdot)$ is a pairwise loss that only depends on the prediction outputs of the input data pairs $(\mathbf z, \mathbf z')$, and $f(\cdot)$ is possibly a non-linear non-convex function. This problem has important applications in machine learning, e.g., AUROC maximization with a pairwise loss, and partial AUROC maximization with a compositional loss. The challenges for designing an FL algorithm lie in the non-decomposability of the objective over multiple machines and the interdependency between different machines. We propose two provable FL algorithms (FedX) for handling linear and nonlinear $f$, respectively. To address the challenges, we decouple the gradient's components with two types, namely active parts and lazy parts, where the active parts depend on local data that are computed with the local model and the lazy parts depend on other machines that are communicated/computed based on historical models and samples. We develop a novel theoretical analysis to combat the latency of the lazy parts and the interdependency between the local model parameters and the involved data for computing local gradient estimators. We establish both iteration and communication complexities and show that using the historical samples and models for computing the lazy parts do not degrade the complexities. We conduct empirical studies of FedX for deep AUROC and partial AUROC maximization, and demonstrate their performance compared with several baselines.
A Novel Convergence Analysis for Algorithms of the Adam Family
Dec 07, 2021

Since its invention in 2014, the Adam optimizer has received tremendous attention. On one hand, it has been widely used in deep learning and many variants have been proposed, while on the other hand their theoretical convergence property remains to be a mystery. It is far from satisfactory in the sense that some studies require strong assumptions about the updates, which are not necessarily applicable in practice, while other studies still follow the original problematic convergence analysis of Adam, which was shown to be not sufficient to ensure convergence. Although rigorous convergence analysis exists for Adam, they impose specific requirements on the update of the adaptive step size, which are not generic enough to cover many other variants of Adam. To address theses issues, in this extended abstract, we present a simple and generic proof of convergence for a family of Adam-style methods (including Adam, AMSGrad, Adabound, etc.). Our analysis only requires an increasing or large "momentum" parameter for the first-order moment, which is indeed the case used in practice, and a boundness condition on the adaptive factor of the step size, which applies to all variants of Adam under mild conditions of stochastic gradients. We also establish a variance diminishing result for the used stochastic gradient estimators. Indeed, our analysis of Adam is so simple and generic that it can be leveraged to establish the convergence for solving a broader family of non-convex optimization problems, including min-max, compositional, and bilevel optimization problems. For the full (earlier) version of this extended abstract, please refer to arXiv:2104.14840.