 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAGELS: Benchmarking the Automated Generation and Extraction of Limitations from Scholarly Text
May 22, 2025In scientific research, limitations refer to the shortcomings, constraints, or weaknesses within a study. Transparent reporting of such limitations can enhance the quality and reproducibility of research and improve public trust in science. However, authors often a) underreport them in the paper text and b) use hedging strategies to satisfy editorial requirements at the cost of readers' clarity and confidence. This underreporting behavior, along with an explosion in the number of publications, has created a pressing need to automatically extract or generate such limitations from scholarly papers. In this direction, we present a complete architecture for the computational analysis of research limitations. Specifically, we create a dataset of limitations in ACL, NeurIPS, and PeerJ papers by extracting them from papers' text and integrating them with external reviews; we propose methods to automatically generate them using a novel Retrieval Augmented Generation (RAG) technique; we create a fine-grained evaluation framework for generated limitations; and we provide a meta-evaluation for the proposed evaluation techniques.
FutureGen: LLM-RAG Approach to Generate the Future Work of Scientific Article
Mar 20, 2025
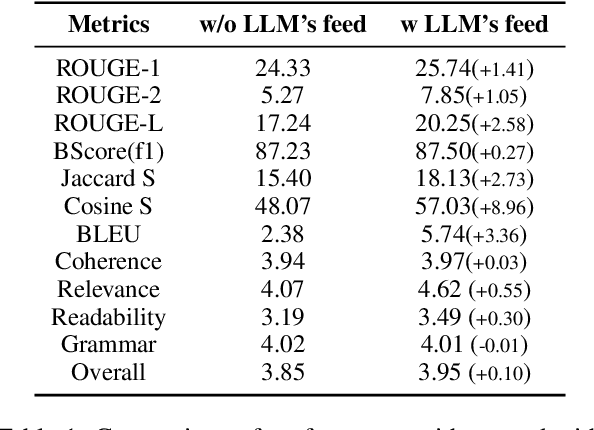
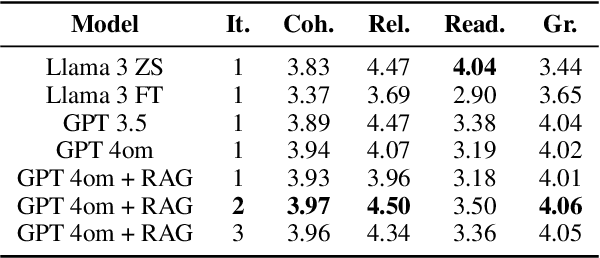
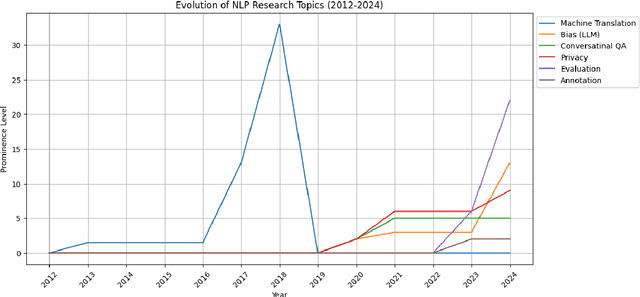
The future work section of a scientific article outlines potential research directions by identifying gaps and limitations of a current study. This section serves as a valuable resource for early-career researchers seeking unexplored areas and experienced researchers looking for new projects or collaborations. In this study, we generate future work suggestions from key sections of a scientific article alongside related papers and analyze how the trends have evolved. We experimented with various Large Language Models (LLMs) and integrated Retrieval-Augmented Generation (RAG) to enhance the generation process. We incorporate a LLM feedback mechanism to improve the quality of the generated content and propose an LLM-as-a-judge approach for evaluation. Our results demonstrated that the RAG-based approach with LLM feedback outperforms other methods evaluated through qualitative and quantitative metrics. Moreover, we conduct a human evaluation to assess the LLM as an extractor and judge. The code and dataset for this project are here, code: HuggingFace
Quantifying the Relevance of Youth Research Cited in the US Policy Documents
Mar 06, 2025In recent years, there has been a growing concern and emphasis on conducting research beyond academic or scientific research communities, benefiting society at large. A well-known approach to measuring the impact of research on society is enumerating its policy citation(s). Despite the importance of research in informing policy, there is no concrete evidence to suggest the research's relevance in cited policy documents. This is concerning because it may increase the possibility of evidence used in policy being manipulated by individual, social, or political biases that may lead to inappropriate, fragmented, or archaic research evidence in policy. Therefore, it is crucial to identify the degree of relevance between research articles and citing policy documents. In this paper, we examined the scale of contextual relevance of youth-focused research in the referenced US policy documents using natural language processing techniques, state-of-the-art pre-trained Large Language Models (LLMs), and statistical analysis. Our experiments and analysis concluded that youth-related research articles that get US policy citations are mostly relevant to the citing policy documents.
* The paper was accepted and presented in IEEE BIG DATA 2024. It has 10 pages, 5 figures, and 4 tables
Effective Defect Detection Using Instance Segmentation for NDI
Jan 24, 2025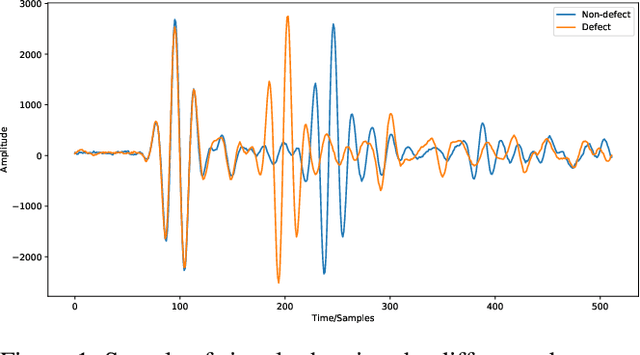
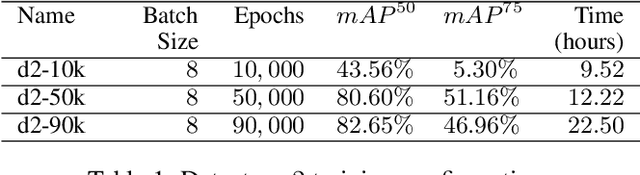

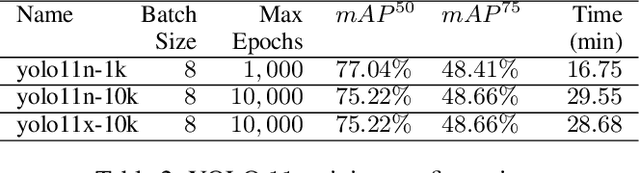
Ultrasonic testing is a common Non-Destructive Inspection (NDI) method used in aerospace manufacturing. However, the complexity and size of the ultrasonic scans make it challenging to identify defects through visual inspection or machine learning models. Using computer vision techniques to identify defects from ultrasonic scans is an evolving research area. In this study, we used instance segmentation to identify the presence of defects in the ultrasonic scan images of composite panels that are representative of real components manufactured in aerospace. We used two models based on Mask-RCNN (Detectron 2) and YOLO 11 respectively. Additionally, we implemented a simple statistical pre-processing technique that reduces the burden of requiring custom-tailored pre-processing techniques. Our study demonstrates the feasibility and effectiveness of using instance segmentation in the NDI pipeline by significantly reducing data pre-processing time, inspection time, and overall costs.
Test Case Recommendations with Distributed Representation of Code Syntactic Features
Oct 04, 2023Frequent modifications of unit test cases are inevitable due to software's continuous underlying changes in source code, design, and requirements. Since manually maintaining software test suites is tedious, timely, and costly, automating the process of generation and maintenance of test units will significantly impact the effectiveness and efficiency of software testing processes. To this end, we propose an automated approach which exploits both structural and semantic properties of source code methods and test cases to recommend the most relevant and useful unit tests to the developers. The proposed approach initially trains a neural network to transform method-level source code, as well as unit tests, into distributed representations (embedded vectors) while preserving the importance of the structure in the code. Retrieving the semantic and structural properties of a given method, the approach computes cosine similarity between the method's embedding and the previously-embedded training instances. Further, according to the similarity scores between the embedding vectors, the model identifies the closest methods of embedding and the associated unit tests as the most similar recommendations. The results on the Methods2Test dataset showed that, while there is no guarantee to have similar relevant test cases for the group of similar methods, the proposed approach extracts the most similar existing test cases for a given method in the dataset, and evaluations show that recommended test cases decrease the developers' effort to generating expected test cases.
Laying foundations to quantify the "Effort of Reproducibility"
Aug 24, 2023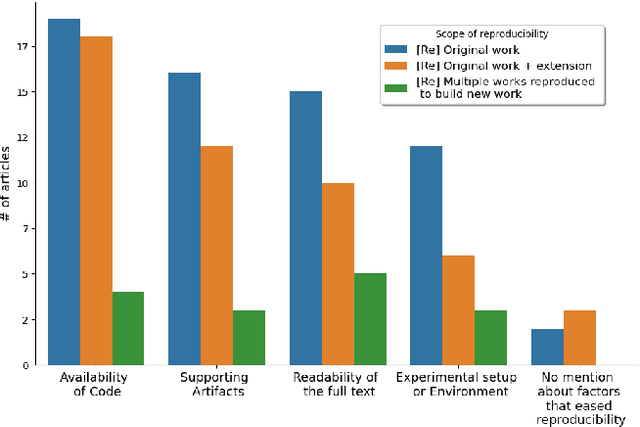

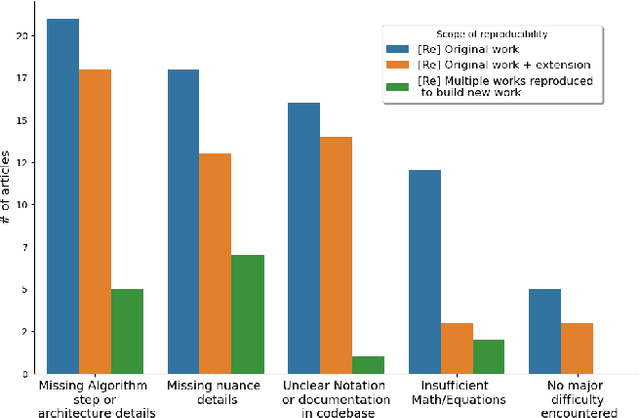

Why are some research studies easy to reproduce while others are difficult? Casting doubt on the accuracy of scientific work is not fruitful, especially when an individual researcher cannot reproduce the claims made in the paper. There could be many subjective reasons behind the inability to reproduce a scientific paper. The field of Machine Learning (ML) faces a reproducibility crisis, and surveying a portion of published articles has resulted in a group realization that although sharing code repositories would be appreciable, code bases are not the end all be all for determining the reproducibility of an article. Various parties involved in the publication process have come forward to address the reproducibility crisis and solutions such as badging articles as reproducible, reproducibility checklists at conferences (\textit{NeurIPS, ICML, ICLR, etc.}), and sharing artifacts on \textit{OpenReview} come across as promising solutions to the core problem. The breadth of literature on reproducibility focuses on measures required to avoid ir-reproducibility, and there is not much research into the effort behind reproducing these articles. In this paper, we investigate the factors that contribute to the easiness and difficulty of reproducing previously published studies and report on the foundational framework to quantify effort of reproducibility.
Visualizing Relation Between (De)Motivating Topics and Public Stance toward COVID-19 Vaccine
Jul 06, 2023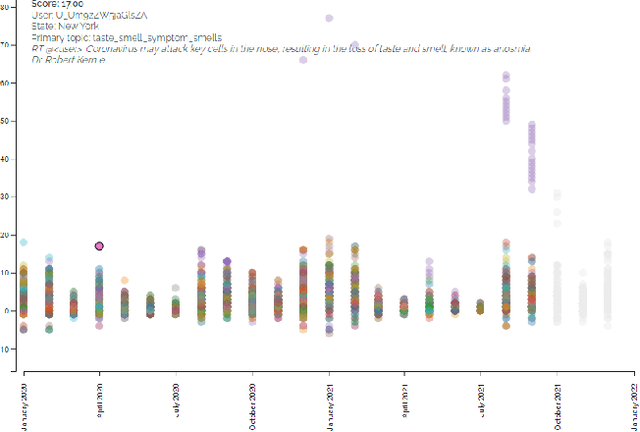
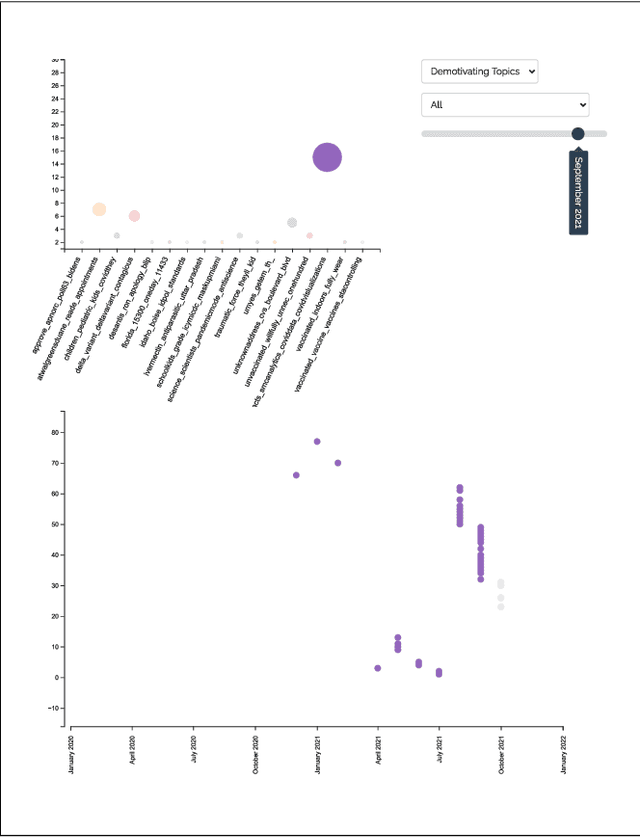
While social media plays a vital role in communication nowadays, misinformation and trolls can easily take over the conversation and steer public opinion on these platforms. We saw the effect of misinformation during the COVID-19 pandemic when public health officials faced significant push-back while trying to motivate the public to vaccinate. To tackle the current and any future threats in emergencies and motivate the public towards a common goal, it is essential to understand how public motivation shifts and which topics resonate among the general population. In this study, we proposed an interactive visualization tool to inspect and analyze the topics that resonated among Twitter-sphere during the COVID-19 pandemic and understand the key factors that shifted public stance for vaccination. This tool can easily be generalized for any scenario for visual analysis and to increase the transparency of social media data for researchers and the general population alike.
Quantifying the Online Long-Term Interest in Research
Sep 13, 2022
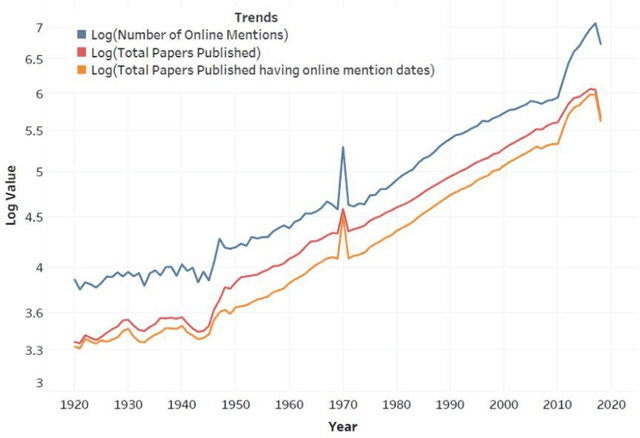
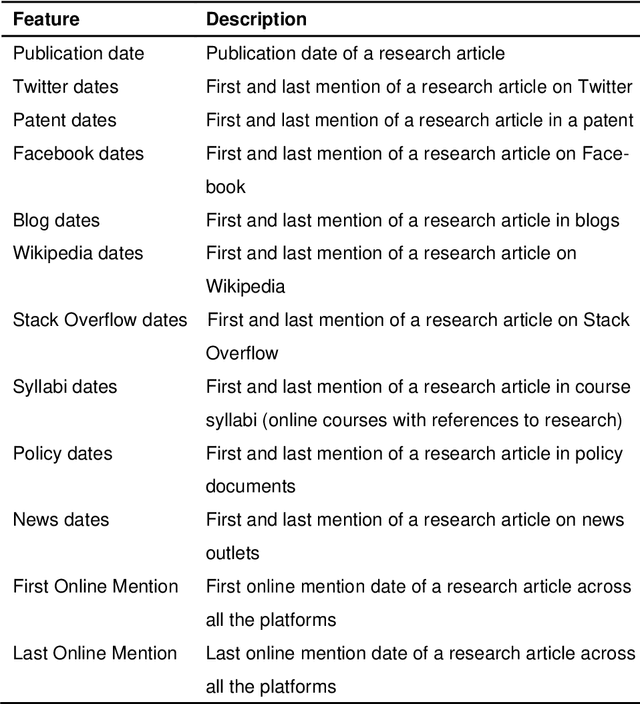
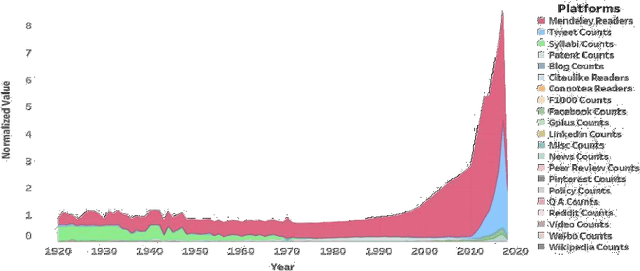
Research articles are being shared in increasing numbers on multiple online platforms. Although the scholarly impact of these articles has been widely studied, the online interest determined by how long the research articles are shared online remains unclear. Being cognizant of how long a research article is mentioned online could be valuable information to the researchers. In this paper, we analyzed multiple social media platforms on which users share and/or discuss scholarly articles. We built three clusters for papers, based on the number of yearly online mentions having publication dates ranging from the year 1920 to 2016. Using the online social media metrics for each of these three clusters, we built machine learning models to predict the long-term online interest in research articles. We addressed the prediction task with two different approaches: regression and classification. For the regression approach, the Multi-Layer Perceptron model performed best, and for the classification approach, the tree-based models performed better than other models. We found that old articles are most evident in the contexts of economics and industry (i.e., patents). In contrast, recently published articles are most evident in research platforms (i.e., Mendeley) followed by social media platforms (i.e., Twitter).
* Journal of Informetrics
Public Reaction to Scientific Research via Twitter Sentiment Prediction
Sep 11, 2022
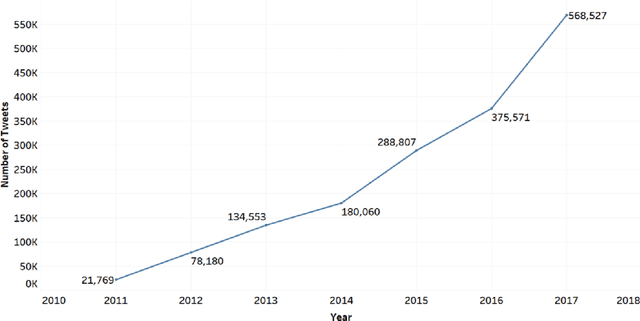
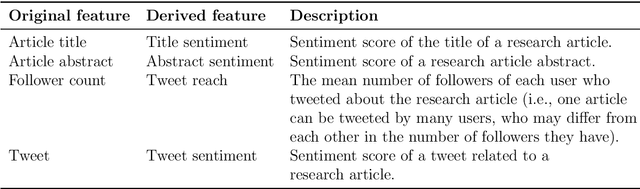
Social media users share their ideas, thoughts, and emotions with other users. However, it is not clear how online users would respond to new research outcomes. This study aims to predict the nature of the emotions expressed by Twitter users toward scientific publications. Additionally, we investigate what features of the research articles help in such prediction. Identifying the sentiments of research articles on social media will help scientists gauge a new societal impact of their research articles.
* Journal of Data and Information Sciences
YouTube and Science: Models for Research Impact
Sep 01, 2022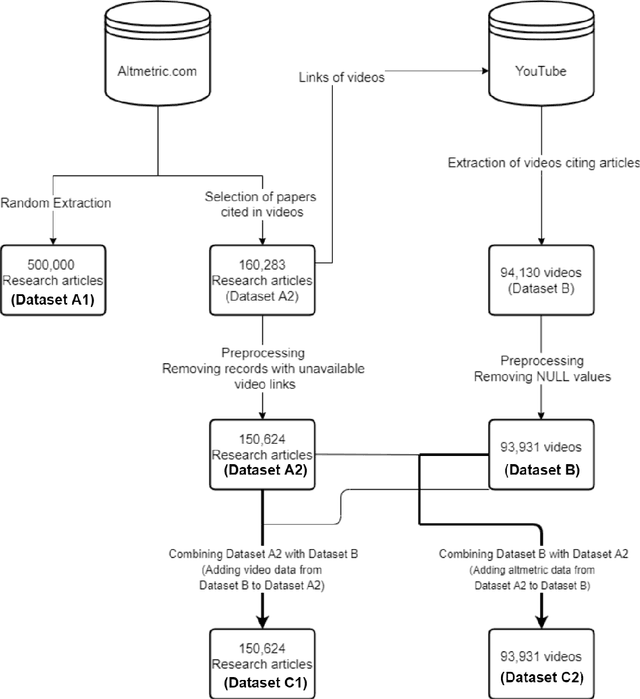
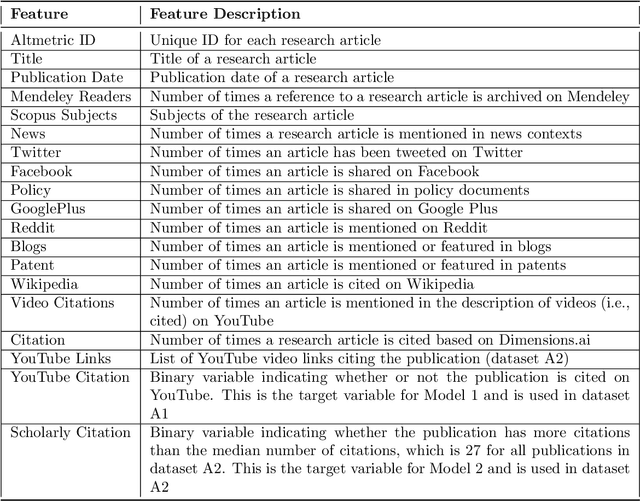

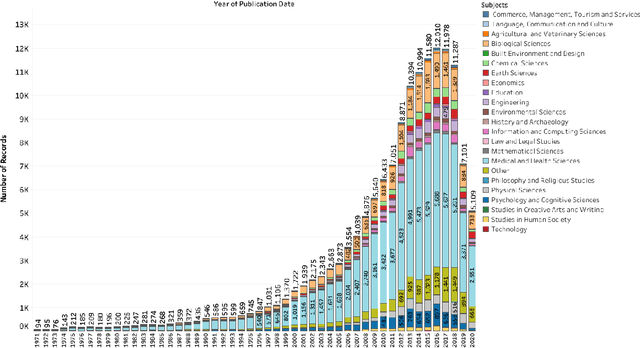
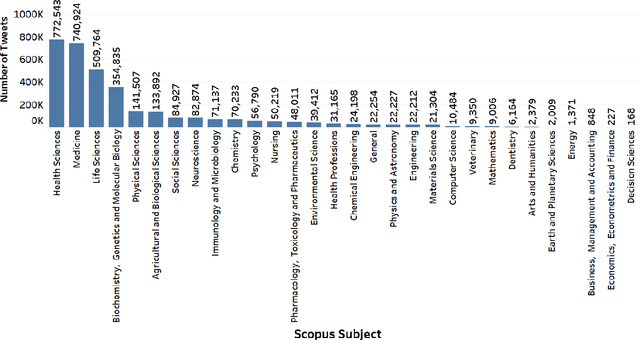
Video communication has been rapidly increasing over the past decade, with YouTube providing a medium where users can post, discover, share, and react to videos. There has also been an increase in the number of videos citing research articles, especially since it has become relatively commonplace for academic conferences to require video submissions. However, the relationship between research articles and YouTube videos is not clear, and the purpose of the present paper is to address this issue. We created new datasets using YouTube videos and mentions of research articles on various online platforms. We found that most of the articles cited in the videos are related to medicine and biochemistry. We analyzed these datasets through statistical techniques and visualization, and built machine learning models to predict (1) whether a research article is cited in videos, (2) whether a research article cited in a video achieves a level of popularity, and (3) whether a video citing a research article becomes popular. The best models achieved F1 scores between 80% and 94%. According to our results, research articles mentioned in more tweets and news coverage have a higher chance of receiving video citations. We also found that video views are important for predicting citations and increasing research articles' popularity and public engagement with science.