 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaying foundations to quantify the "Effort of Reproducibility"
Aug 24, 2023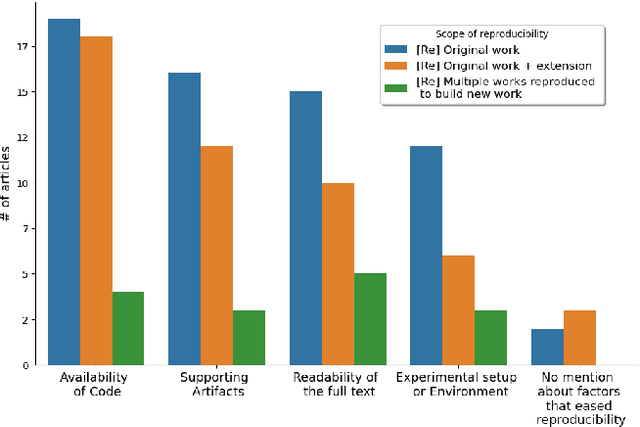

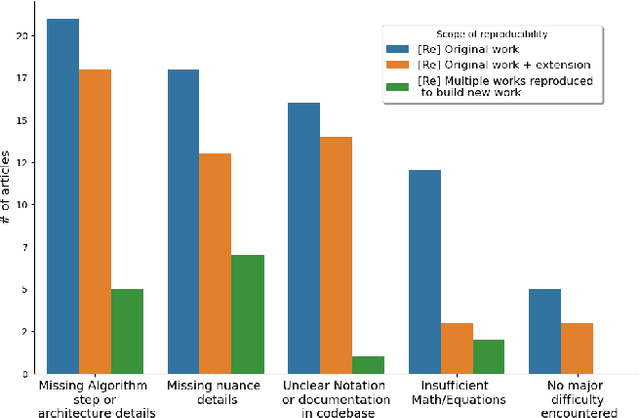

Why are some research studies easy to reproduce while others are difficult? Casting doubt on the accuracy of scientific work is not fruitful, especially when an individual researcher cannot reproduce the claims made in the paper. There could be many subjective reasons behind the inability to reproduce a scientific paper. The field of Machine Learning (ML) faces a reproducibility crisis, and surveying a portion of published articles has resulted in a group realization that although sharing code repositories would be appreciable, code bases are not the end all be all for determining the reproducibility of an article. Various parties involved in the publication process have come forward to address the reproducibility crisis and solutions such as badging articles as reproducible, reproducibility checklists at conferences (\textit{NeurIPS, ICML, ICLR, etc.}), and sharing artifacts on \textit{OpenReview} come across as promising solutions to the core problem. The breadth of literature on reproducibility focuses on measures required to avoid ir-reproducibility, and there is not much research into the effort behind reproducing these articles. In this paper, we investigate the factors that contribute to the easiness and difficulty of reproducing previously published studies and report on the foundational framework to quantify effort of reproducibility.
An Edge Map based Ensemble Solution to Detect Water Level in Stream
Jan 16, 2022Flooding is one of the most dangerous weather events today. Between $2015-2019$, on average, flooding has caused more than $130$ deaths every year in the USA alone. The devastating nature of flood necessitates the continuous monitoring of water level in the rivers and streams to detect the incoming flood. In this work, we have designed and implemented an efficient vision-based ensemble solution to continuously detect the water level in the creek. Our solution adapts template matching algorithm to find the region of interest by leveraging edge maps, and combines two parallel approach to identify the water level. While first approach fits a linear regression model in edge map to identify the water line, second approach uses a split sliding window to compute the sum of squared difference in pixel intensities to find the water surface. We evaluated the proposed system on $4306$ images collected between $3$rd October and $18$th December in 2019 with the frequency of $1$ image in every $10$ minutes. The system exhibited low error rate as it achieved $4.8$, $3.1\%$ and $0.92$ scores for MAE, MAPE and $R^2$ evaluation metrics, respectively. We believe the proposed solution is very practical as it is pervasive, accurate, doesn't require installation of any additional infrastructure in the water body and can be easily adapted to other locations.