 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-review to Peer review: Pitfalls of Automating Reviews using Large Language Models
Dec 14, 2025Large Language Models are versatile general-task solvers, and their capabilities can truly assist people with scholarly peer review as \textit{pre-review} agents, if not as fully autonomous \textit{peer-review} agents. While incredibly beneficial, automating academic peer-review, as a concept, raises concerns surrounding safety, research integrity, and the validity of the academic peer-review process. The majority of the studies performing a systematic evaluation of frontier LLMs generating reviews across science disciplines miss the mark on addressing the alignment/misalignment of reviews along with the utility of LLM generated reviews when compared against publication outcomes such as \textbf{Citations}, \textbf{Hit-papers}, \textbf{Novelty}, and \textbf{Disruption}. This paper presents an experimental study in which we gathered ground-truth reviewer ratings from OpenReview and used various frontier open-weight LLMs to generate reviews of papers to gauge the safety and reliability of incorporating LLMs into the scientific review pipeline. Our findings demonstrate the utility of frontier open-weight LLMs as pre-review screening agents despite highlighting fundamental misalignment risks when deployed as autonomous reviewers. Our results show that all models exhibit weak correlation with human peer reviewers (0.15), with systematic overestimation bias of 3-5 points and uniformly high confidence scores (8.0-9.0/10) despite prediction errors. However, we also observed that LLM reviews correlate more strongly with post-publication metrics than with human scores, suggesting potential utility as pre-review screening tools. Our findings highlight the potential and address the pitfalls of automating peer reviews with language models. We open-sourced our dataset $D_{LMRSD}$ to help the research community expand the safety framework of automating scientific reviews.
Laying foundations to quantify the "Effort of Reproducibility"
Aug 24, 2023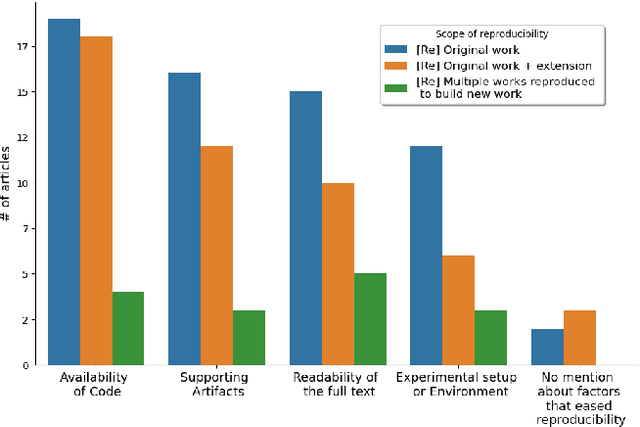

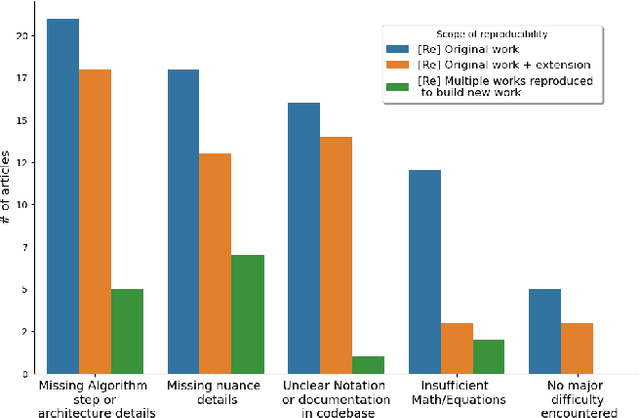

Why are some research studies easy to reproduce while others are difficult? Casting doubt on the accuracy of scientific work is not fruitful, especially when an individual researcher cannot reproduce the claims made in the paper. There could be many subjective reasons behind the inability to reproduce a scientific paper. The field of Machine Learning (ML) faces a reproducibility crisis, and surveying a portion of published articles has resulted in a group realization that although sharing code repositories would be appreciable, code bases are not the end all be all for determining the reproducibility of an article. Various parties involved in the publication process have come forward to address the reproducibility crisis and solutions such as badging articles as reproducible, reproducibility checklists at conferences (\textit{NeurIPS, ICML, ICLR, etc.}), and sharing artifacts on \textit{OpenReview} come across as promising solutions to the core problem. The breadth of literature on reproducibility focuses on measures required to avoid ir-reproducibility, and there is not much research into the effort behind reproducing these articles. In this paper, we investigate the factors that contribute to the easiness and difficulty of reproducing previously published studies and report on the foundational framework to quantify effort of reproducibility.
Early Indicators of Scientific Impact: Predicting Citations with Altmetrics
Dec 25, 2020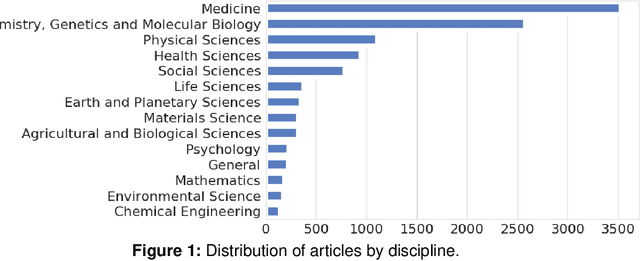
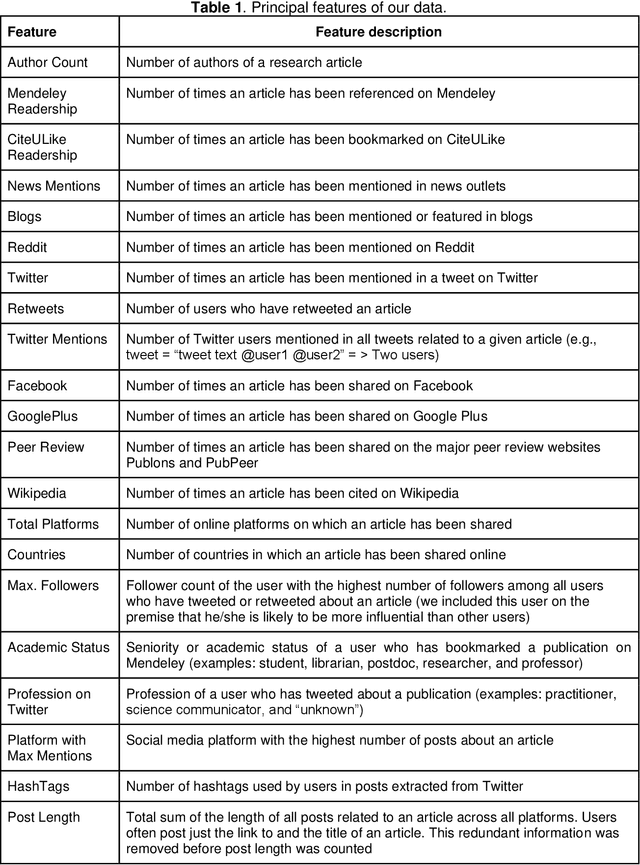
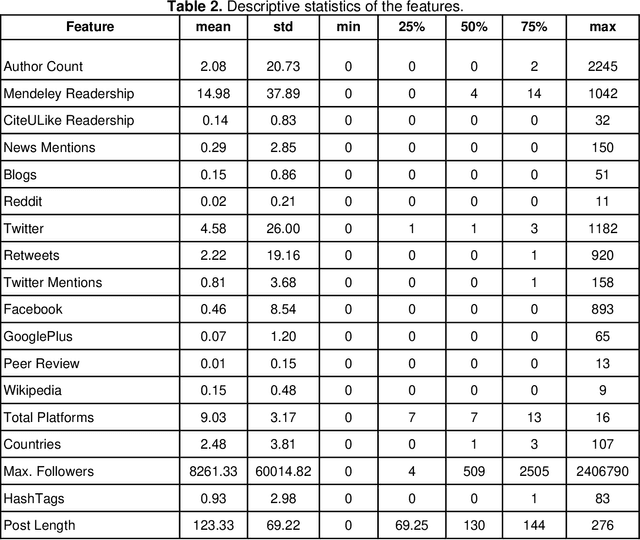
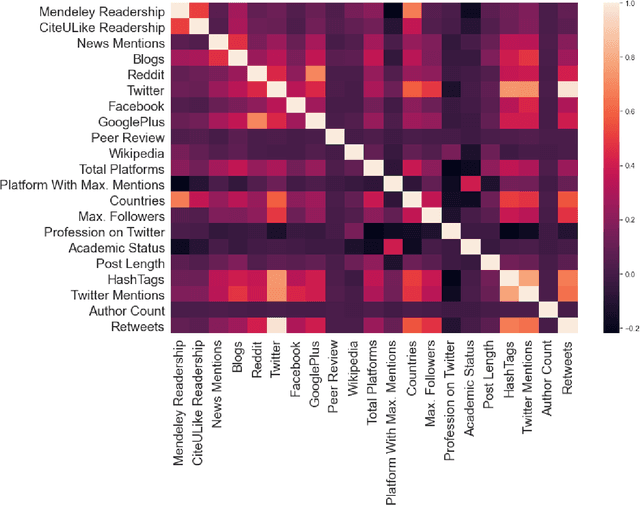
Identifying important scholarly literature at an early stage is vital to the academic research community and other stakeholders such as technology companies and government bodies. Due to the sheer amount of research published and the growth of ever-changing interdisciplinary areas, researchers need an efficient way to identify important scholarly work. The number of citations a given research publication has accrued has been used for this purpose, but these take time to occur and longer to accumulate. In this article, we use altmetrics to predict the short-term and long-term citations that a scholarly publication could receive. We build various classification and regression models and evaluate their performance, finding neural networks and ensemble models to perform best for these tasks. We also find that Mendeley readership is the most important factor in predicting the early citations, followed by other factors such as the academic status of the readers (e.g., student, postdoc, professor), followers on Twitter, online post length, author count, and the number of mentions on Twitter, Wikipedia, and across different countries.