 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Indicators of Scientific Impact: Predicting Citations with Altmetrics
Dec 25, 2020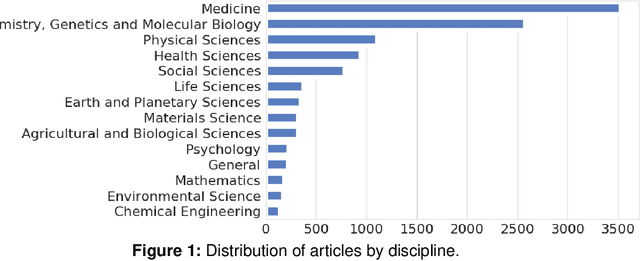
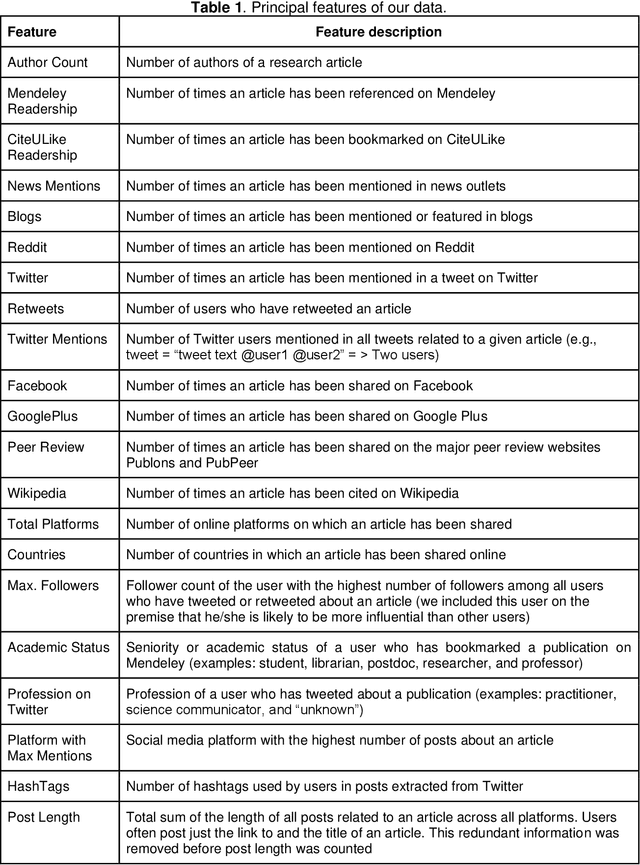
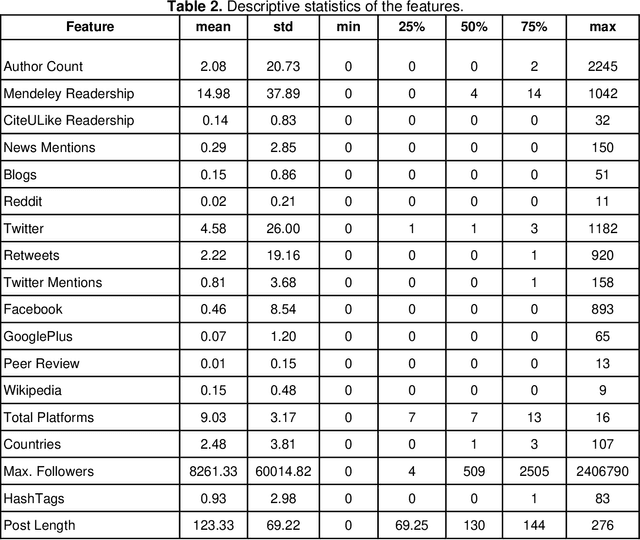
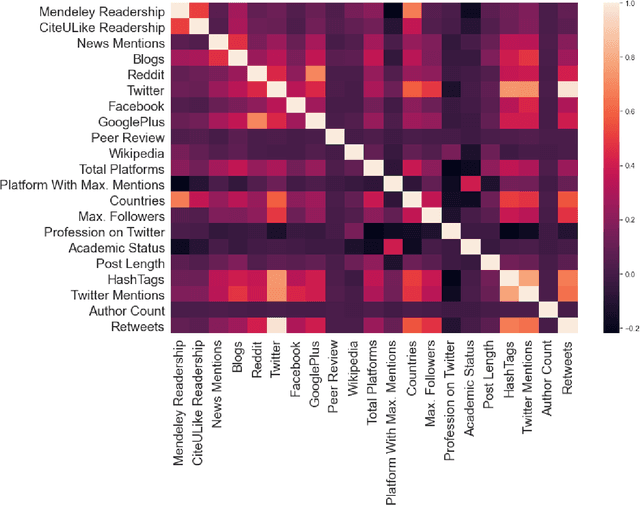
Identifying important scholarly literature at an early stage is vital to the academic research community and other stakeholders such as technology companies and government bodies. Due to the sheer amount of research published and the growth of ever-changing interdisciplinary areas, researchers need an efficient way to identify important scholarly work. The number of citations a given research publication has accrued has been used for this purpose, but these take time to occur and longer to accumulate. In this article, we use altmetrics to predict the short-term and long-term citations that a scholarly publication could receive. We build various classification and regression models and evaluate their performance, finding neural networks and ensemble models to perform best for these tasks. We also find that Mendeley readership is the most important factor in predicting the early citations, followed by other factors such as the academic status of the readers (e.g., student, postdoc, professor), followers on Twitter, online post length, author count, and the number of mentions on Twitter, Wikipedia, and across different countries.
Shared Feelings: Understanding Facebook Reactions to Scholarly Articles
May 27, 2019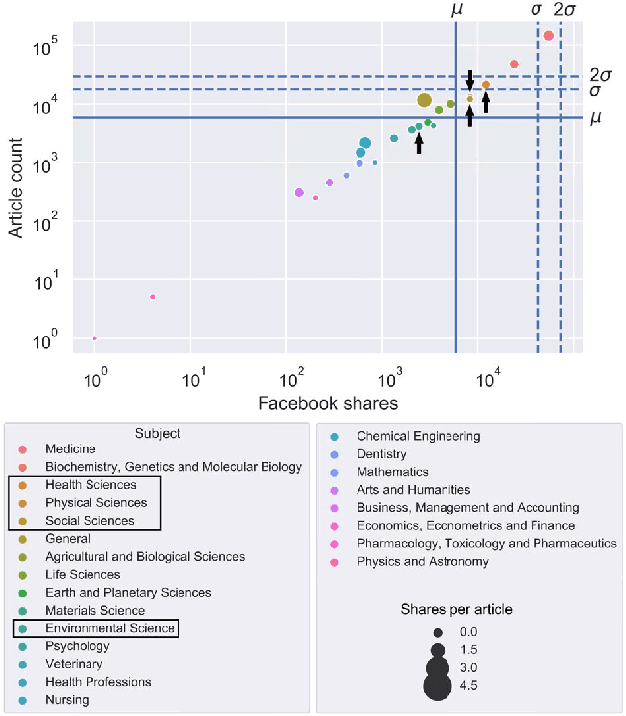
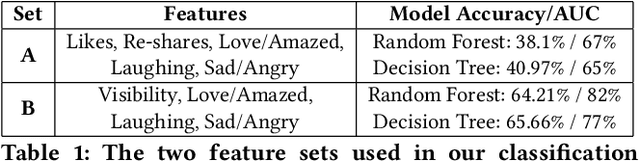
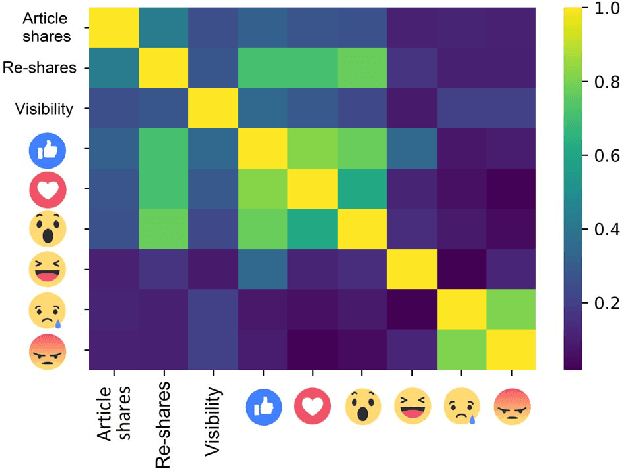
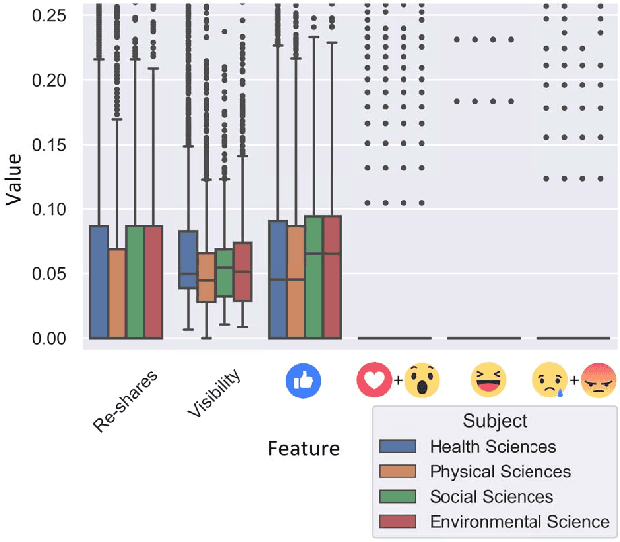
Research on social-media platforms has tended to rely on textual analysis to perform research tasks. While text-based approaches have significantly increased our understanding of online behavior and social dynamics, they overlook features on these platforms that have grown in prominence in the past few years: click-based responses to content. In this paper, we present a new dataset of Facebook Reactions to scholarly content. We give an overview of its structure, analyze some of the statistical trends in the data, and use it to train and test two supervised learning algorithms. Our preliminary tests suggest the presence of stratification in the number of users following pages, divisions that seem to fall in line with distinctions in the subject matter of those pages.