 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePtychographic Image Reconstruction from Limited Data via Score-Based Diffusion Models with Physics-Guidance
Feb 26, 2025



Ptychography is a computational imaging technique that achieves high spatial resolution over large fields of view. It involves scanning a coherent beam across overlapping regions and recording diffraction patterns. Conventional reconstruction algorithms require substantial overlap, increasing data volume and experimental time. We propose a reconstruction method employing a physics-guided score-based diffusion model. Our approach trains a diffusion model on representative object images to learn an object distribution prior. During reconstruction, we modify the reverse diffusion process to enforce data consistency, guiding reverse diffusion toward a physically plausible solution. This method requires a single pretraining phase, allowing it to generalize across varying scan overlap ratios and positions. Our results demonstrate that the proposed method achieves high-fidelity reconstructions with only a 20% overlap, while the widely employed rPIE method requires a 62% overlap to achieve similar accuracy. This represents a significant reduction in data requirements, offering an alternative to conventional techniques.
Effective Defect Detection Using Instance Segmentation for NDI
Jan 24, 2025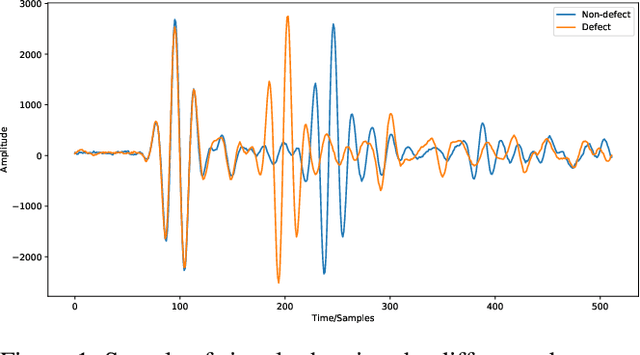
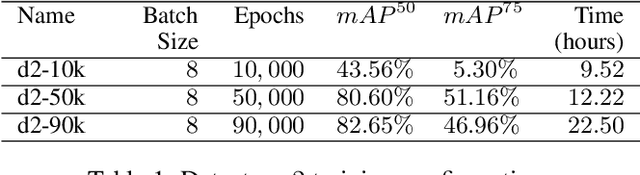

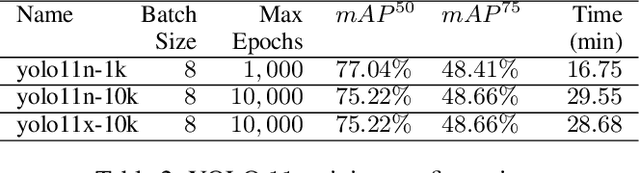
Ultrasonic testing is a common Non-Destructive Inspection (NDI) method used in aerospace manufacturing. However, the complexity and size of the ultrasonic scans make it challenging to identify defects through visual inspection or machine learning models. Using computer vision techniques to identify defects from ultrasonic scans is an evolving research area. In this study, we used instance segmentation to identify the presence of defects in the ultrasonic scan images of composite panels that are representative of real components manufactured in aerospace. We used two models based on Mask-RCNN (Detectron 2) and YOLO 11 respectively. Additionally, we implemented a simple statistical pre-processing technique that reduces the burden of requiring custom-tailored pre-processing techniques. Our study demonstrates the feasibility and effectiveness of using instance segmentation in the NDI pipeline by significantly reducing data pre-processing time, inspection time, and overall costs.
Rapid detection of rare events from in situ X-ray diffraction data using machine learning
Dec 07, 2023High-energy X-ray diffraction methods can non-destructively map the 3D microstructure and associated attributes of metallic polycrystalline engineering materials in their bulk form. These methods are often combined with external stimuli such as thermo-mechanical loading to take snapshots over time of the evolving microstructure and attributes. However, the extreme data volumes and the high costs of traditional data acquisition and reduction approaches pose a barrier to quickly extracting actionable insights and improving the temporal resolution of these snapshots. Here we present a fully automated technique capable of rapidly detecting the onset of plasticity in high-energy X-ray microscopy data. Our technique is computationally faster by at least 50 times than the traditional approaches and works for data sets that are up to 9 times sparser than a full data set. This new technique leverages self-supervised image representation learning and clustering to transform massive data into compact, semantic-rich representations of visually salient characteristics (e.g., peak shapes). These characteristics can be a rapid indicator of anomalous events such as changes in diffraction peak shapes. We anticipate that this technique will provide just-in-time actionable information to drive smarter experiments that effectively deploy multi-modal X-ray diffraction methods that span many decades of length scales.
Masked Sinogram Model with Transformer for ill-Posed Computed Tomography Reconstruction: a Preliminary Study
Sep 03, 2022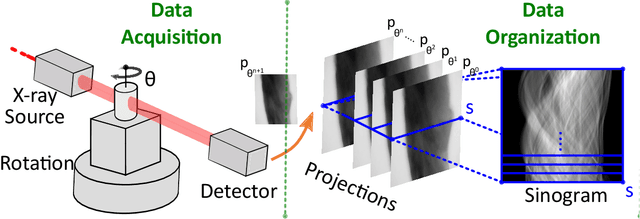

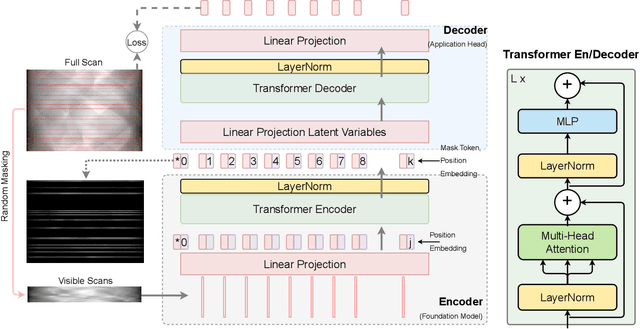

Computed Tomography (CT) is an imaging technique where information about an object are collected at different angles (called projections or scans). Then the cross-sectional image showing the internal structure of the slice is produced by solving an inverse problem. Limited by certain factors such as radiation dosage, projection angles, the produced images can be noisy or contain artifacts. Inspired by the success of transformer for natural language processing, the core idea of this preliminary study is to consider a projection of tomography as a word token, and the whole scan of the cross-section (A.K.A. sinogram) as a sentence in the context of natural language processing. Then we explore the idea of foundation model by training a masked sinogram model (MSM) and fine-tune MSM for various downstream applications including CT reconstruction under data collections restriction (e.g., photon-budget) and a data-driven solution to approximate solutions of the inverse problem for CT reconstruction. Models and data used in this study are available at https://github.com/lzhengchun/TomoTx.
fairDMS: Rapid Model Training by Data and Model Reuse
Apr 20, 2022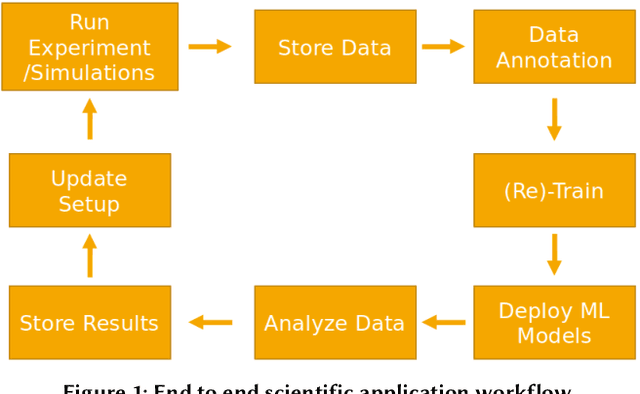
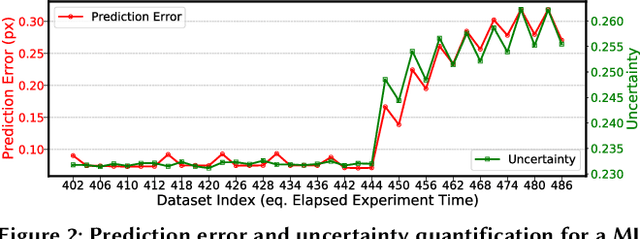
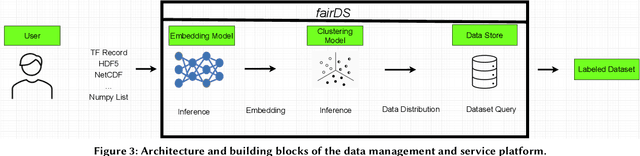
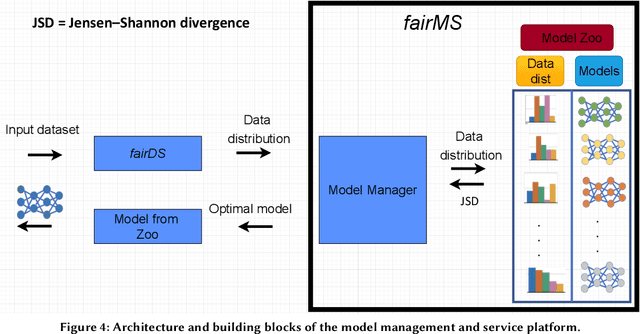
Extracting actionable information from data sources such as the Linac Coherent Light Source (LCLS-II) and Advanced Photon Source Upgrade (APS-U) is becoming more challenging due to the fast-growing data generation rate. The rapid analysis possible with ML methods can enable fast feedback loops that can be used to adjust experimental setups in real-time, for example when errors occur or interesting events are detected. However, to avoid degradation in ML performance over time due to changes in an instrument or sample, we need a way to update ML models rapidly while an experiment is running. We present here a data service and model service to accelerate deep neural network training with a focus on ML-based scientific applications. Our proposed data service achieves 100x speedup in terms of data labeling compare to the current state-of-the-art. Further, our model service achieves up to 200x improvement in training speed. Overall, fairDMS achieves up to 92x speedup in terms of end-to-end model updating time.
BFTrainer: Low-Cost Training of Neural Networks on Unfillable Supercomputer Nodes
Jun 22, 2021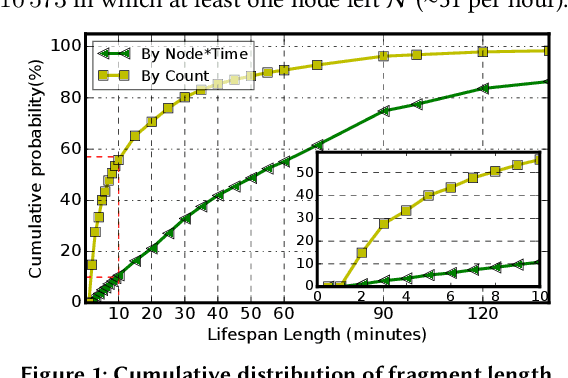
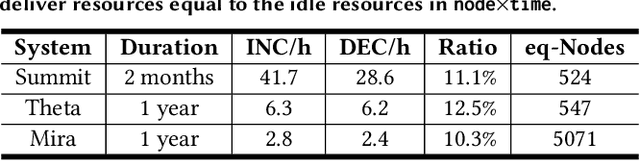
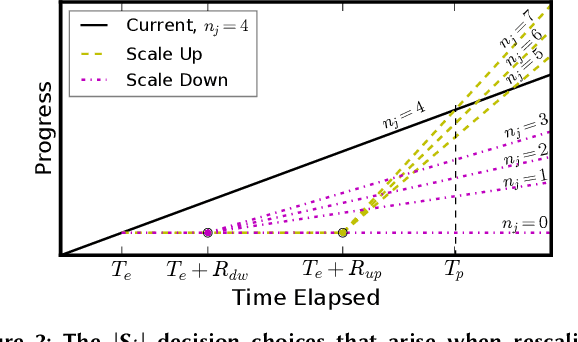
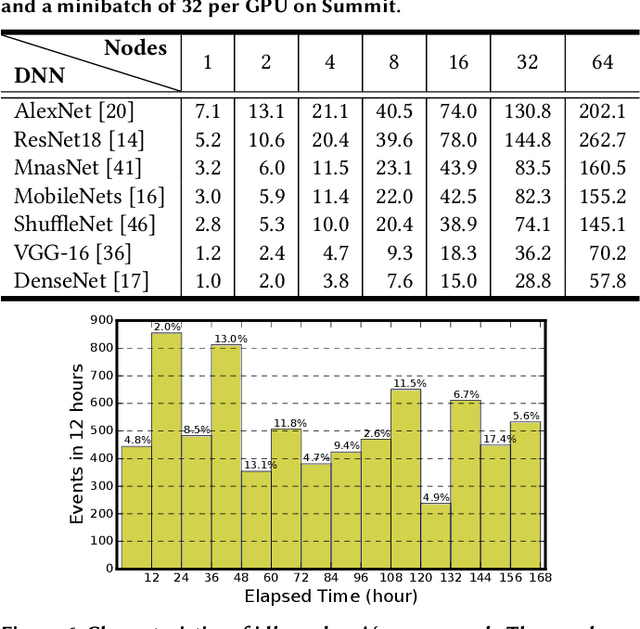
Supercomputer FCFS-based scheduling policies result in many transient idle nodes, a phenomenon that is only partially alleviated by backfill scheduling methods that promote small jobs to run before large jobs. Here we describe how to realize a novel use for these otherwise wasted resources, namely, deep neural network (DNN) training. This important workload is easily organized as many small fragments that can be configured dynamically to fit essentially any node*time hole in a supercomputer's schedule. We describe how the task of rescaling suitable DNN training tasks to fit dynamically changing holes can be formulated as a deterministic mixed integer linear programming (MILP)-based resource allocation algorithm, and show that this MILP problem can be solved efficiently at run time. We show further how this MILP problem can be adapted to optimize for administrator- or user-defined metrics. We validate our method with supercomputer scheduler logs and different DNN training scenarios, and demonstrate efficiencies of up to 93% compared with running the same training tasks on dedicated nodes. Our method thus enables substantial supercomputer resources to be allocated to DNN training with no impact on other applications.
Fast and accurate learned multiresolution dynamical downscaling for precipitation
Jan 18, 2021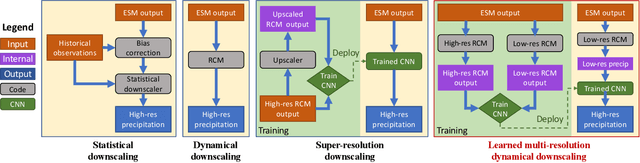

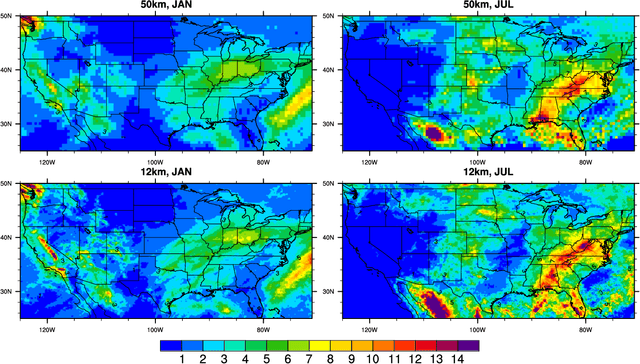
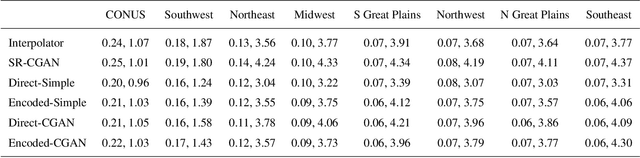
This study develops a neural network-based approach for emulating high-resolution modeled precipitation data with comparable statistical properties but at greatly reduced computational cost. The key idea is to use combination of low- and high- resolution simulations to train a neural network to map from the former to the latter. Specifically, we define two types of CNNs, one that stacks variables directly and one that encodes each variable before stacking, and we train each CNN type both with a conventional loss function, such as mean square error (MSE), and with a conditional generative adversarial network (CGAN), for a total of four CNN variants. We compare the four new CNN-derived high-resolution precipitation results with precipitation generated from original high resolution simulations, a bilinear interpolater and the state-of-the-art CNN-based super-resolution (SR) technique. Results show that the SR technique produces results similar to those of the bilinear interpolator with smoother spatial and temporal distributions and smaller data variabilities and extremes than the original high resolution simulations. While the new CNNs trained by MSE generate better results over some regions than the interpolator and SR technique do, their predictions are still not as close as the original high resolution simulations. The CNNs trained by CGAN generate more realistic and physically reasonable results, better capturing not only data variability in time and space but also extremes such as intense and long-lasting storms. The new proposed CNN-based downscaling approach can downscale precipitation from 50~km to 12~km in 14~min for 30~years once the network is trained (training takes 4~hours using 1~GPU), while the conventional dynamical downscaling would take 1~month using 600 CPU cores to generate simulations at the resolution of 12~km over contiguous United States.
BraggNN: Fast X-ray Bragg Peak Analysis Using Deep Learning
Aug 18, 2020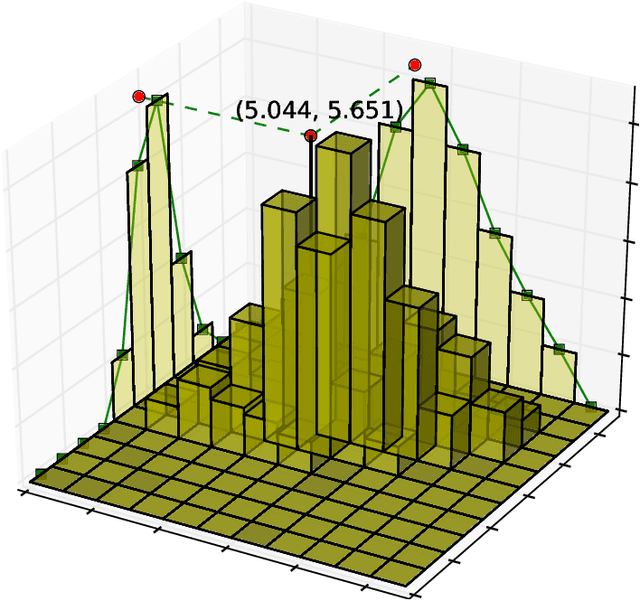
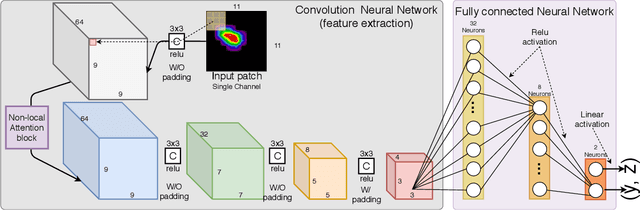
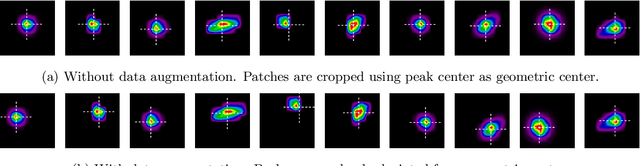
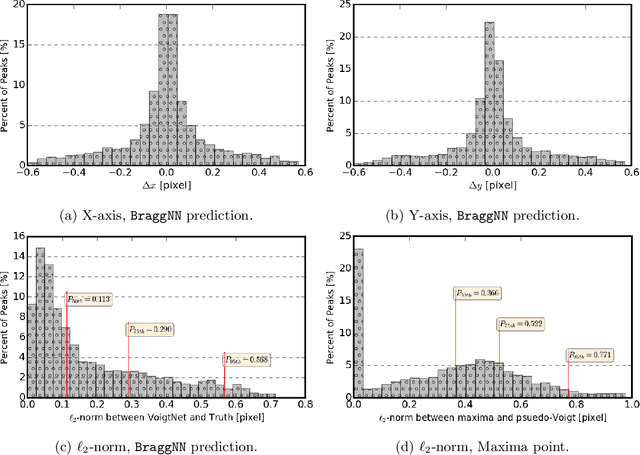
X-ray diffraction based microscopy techniques such as high energy diffraction microscopy rely on knowledge of position of diffraction peaks with high resolution. These positions are typically computed by fitting the observed intensities in detector data to a theoretical peak shape such as pseudo-Voigt. As experiments become more complex and detector technologies evolve, the computational cost of such peak shape fitting becomes the biggest hurdle to the rapid analysis required for real-time feedback for experiments. To this end, this paper proposes BraggNN, a machine learning-based method that can localize Bragg peak much more rapidly than conventional pseudo-Voigt peak fitting. When applied to our test dataset, BraggNN gives errors of less than 0.29 and 0.57 voxels, relative to conventional method, for 75% and 95% of the peaks, respectively. When applied to a real experiment dataset, a 3D reconstruction using peak positions located by BraggNN yields an average grain position difference of 17 micrometer and size difference of 1.3 micrometer as compared to the results obtained when the reconstruction used peaks from conventional 2D pseudo-Voigt fitting. Recent advances in deep learning method implementations and special-purpose model inference accelerators allow BraggNN to deliver enormous performance improvements relative to the conventional method, running, for example, more than 200 times faster than a conventional method when using a GPU card with out-of-the-box software.
Scientific Image Restoration Anywhere
Nov 12, 2019

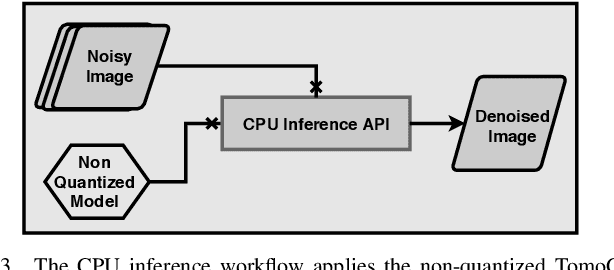
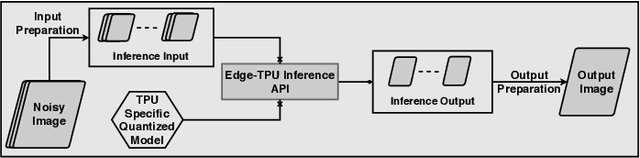
The use of deep learning models within scientific experimental facilities frequently requires low-latency inference, so that, for example, quality control operations can be performed while data are being collected. Edge computing devices can be useful in this context, as their low cost and compact form factor permit them to be co-located with the experimental apparatus. Can such devices, with their limited resources, can perform neural network feed-forward computations efficiently and effectively? We explore this question by evaluating the performance and accuracy of a scientific image restoration model, for which both model input and output are images, on edge computing devices. Specifically, we evaluate deployments of TomoGAN, an image-denoising model based on generative adversarial networks developed for low-dose x-ray imaging, on the Google Edge TPU and NVIDIA Jetson. We adapt TomoGAN for edge execution, evaluate model inference performance, and propose methods to address the accuracy drop caused by model quantization. We show that these edge computing devices can deliver accuracy comparable to that of a full-fledged CPU or GPU model, at speeds that are more than adequate for use in the intended deployments, denoising a 1024 x 1024 image in less than a second. Our experiments also show that the Edge TPU models can provide 3x faster inference response than a CPU-based model and 1.5x faster than an edge GPU-based model. This combination of high speed and low cost permits image restoration anywhere.
Deep Learning Accelerated Light Source Experiments
Oct 09, 2019
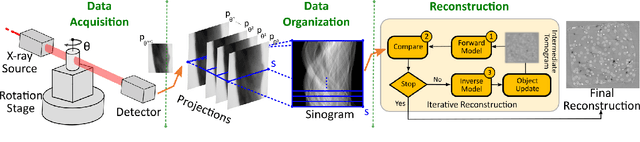

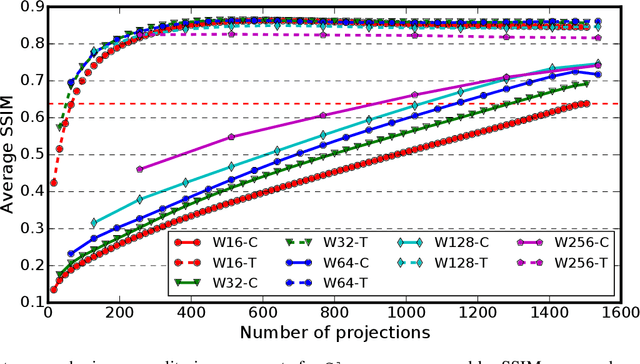
Experimental protocols at synchrotron light sources typically process and validate data only after an experiment has completed, which can lead to undetected errors and cannot enable online steering. Real-time data analysis can enable both detection of, and recovery from, errors, and optimization of data acquisition. However, modern scientific instruments, such as detectors at synchrotron light sources, can generate data at GBs/sec rates. Data processing methods such as the widely used computational tomography usually require considerable computational resources, and yield poor quality reconstructions in the early stages of data acquisition when available views are sparse. We describe here how a deep convolutional neural network can be integrated into the real-time streaming tomography pipeline to enable better-quality images in the early stages of data acquisition. Compared with conventional streaming tomography processing, our method can significantly improve tomography image quality, deliver comparable images using only 32% of the data needed for conventional streaming processing, and save 68% experiment time for data acquisition.