 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Start To End Machine Learning Approach To Maximize Scientific Throughput From The LCLS-II-HE
May 29, 2025With the increasing brightness of Light sources, including the Diffraction-Limited brightness upgrade of APS and the high-repetition-rate upgrade of LCLS, the proposed experiments therein are becoming increasingly complex. For instance, experiments at LCLS-II-HE will require the X-ray beam to be within a fraction of a micron in diameter, with pointing stability of a few nanoradians, at the end of a kilometer-long electron accelerator, a hundred-meter-long undulator section, and tens of meters long X-ray optics. This enhancement of brightness will increase the data production rate to rival the largest data generators in the world. Without real-time active feedback control and an optimized pipeline to transform measurements to scientific information and insights, researchers will drown in a deluge of mostly useless data, and fail to extract the highly sophisticated insights that the recent brightness upgrades promise. In this article, we outline the strategy we are developing at SLAC to implement Machine Learning driven optimization, automation and real-time knowledge extraction from the electron-injector at the start of the electron accelerator, to the multidimensional X-ray optical systems, and till the experimental endstations and the high readout rate, multi-megapixel detectors at LCLS to deliver the design performance to the users. This is illustrated via examples from Accelerator, Optics and End User applications.
FPGA-Accelerated SpeckleNN with SNL for Real-time X-ray Single-Particle Imaging
Feb 27, 2025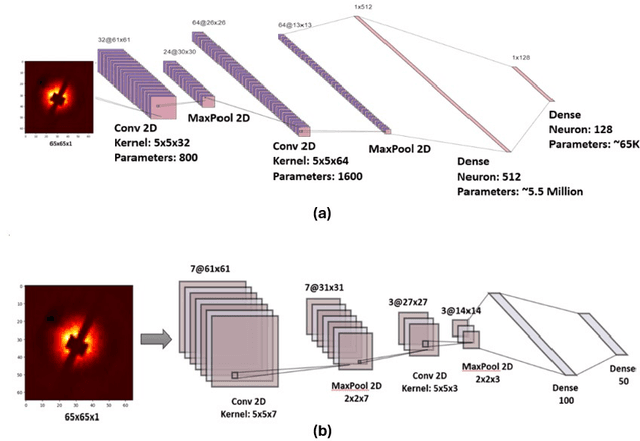
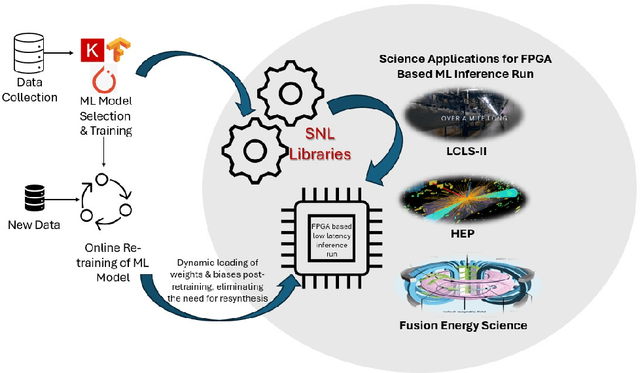
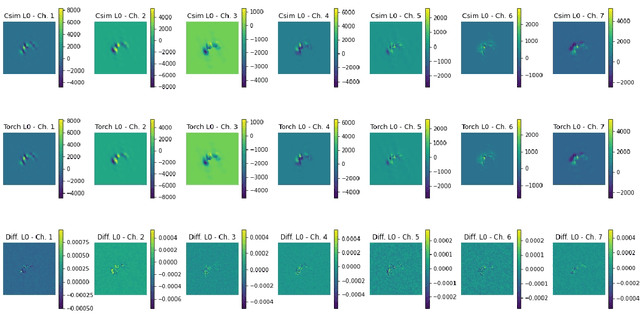

We implement a specialized version of our SpeckleNN model for real-time speckle pattern classification in X-ray Single-Particle Imaging (SPI) using the SLAC Neural Network Library (SNL) on an FPGA. This hardware is optimized for inference near detectors in high-throughput X-ray free-electron laser (XFEL) facilities like the Linac Coherent Light Source (LCLS). To fit FPGA constraints, we optimized SpeckleNN, reducing parameters from 5.6M to 64.6K (98.8% reduction) with 90% accuracy. We also compressed the latent space from 128 to 50 dimensions. Deployed on a KCU1500 FPGA, the model used 71% of DSPs, 75% of LUTs, and 48% of FFs, with an average power consumption of 9.4W. The FPGA achieved 45.015us inference latency at 200 MHz. On an NVIDIA A100 GPU, the same inference consumed ~73W and had a 400us latency. Our FPGA version achieved an 8.9x speedup and 7.8x power reduction over the GPU. Key advancements include model specialization and dynamic weight loading through SNL, eliminating time-consuming FPGA re-synthesis for fast, continuous deployment of (re)trained models. These innovations enable real-time adaptive classification and efficient speckle pattern vetoing, making SpeckleNN ideal for XFEL facilities. This implementation accelerates SPI experiments and enhances adaptability to evolving conditions.
PeakNet: Bragg peak finding in X-ray crystallography experiments with U-Net
Mar 24, 2023Serial crystallography at X-ray free electron laser (XFEL) sources has experienced tremendous progress in achieving high data rate in recent times. While this development offers potential to enable novel scientific investigations, such as imaging molecular events at logarithmic timescales, it also poses challenges in regards to real-time data analysis, which involves some degree of data reduction to only save those features or images pertaining to the science on disks. If data reduction is not effective, it could directly result in a substantial increase in facility budgetary requirements, or even hinder the utilization of ultra-high repetition imaging techniques making data analysis unwieldy. Furthermore, an additional challenge involves providing real-time feedback to users derived from real-time data analysis. In the context of serial crystallography, the initial and critical step in real-time data analysis is finding X-ray Bragg peaks from diffraction images. To tackle this challenge, we present PeakNet, a Bragg peak finder that utilizes neural networks and runs about four times faster than Psocake peak finder, while delivering significantly better indexing rates and comparable number of indexed events. We formulated the task of peak finding into a semantic segmentation problem, which is implemented as a classical U-Net architecture. A key advantage of PeakNet is its ability to scale linearly with respect to data volume, making it well-suited for real-time serial crystallography data analysis at high data rates.
SpeckleNN: A unified embedding for real-time speckle pattern classification in X-ray single-particle imaging with limited labeled examples
Feb 14, 2023With X-ray free-electron lasers (XFELs), it is possible to determine the three-dimensional structure of noncrystalline nanoscale particles using X-ray single-particle imaging (SPI) techniques at room temperature. Classifying SPI scattering patterns, or "speckles", to extract single hits that are needed for real-time vetoing and three-dimensional reconstruction poses a challenge for high data rate facilities like European XFEL and LCLS-II-HE. Here, we introduce SpeckleNN, a unified embedding model for real-time speckle pattern classification with limited labeled examples that can scale linearly with dataset size. Trained with twin neural networks, SpeckleNN maps speckle patterns to a unified embedding vector space, where similarity is measured by Euclidean distance. We highlight its few-shot classification capability on new never-seen samples and its robust performance despite only tens of labels per classification category even in the presence of substantial missing detector areas. Without the need for excessive manual labeling or even a full detector image, our classification method offers a great solution for real-time high-throughput SPI experiments.
fairDMS: Rapid Model Training by Data and Model Reuse
Apr 20, 2022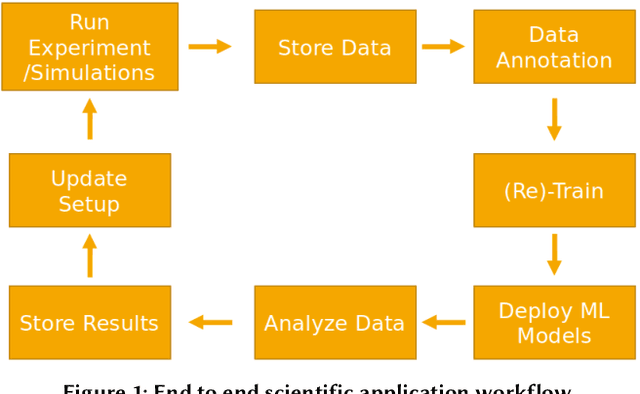
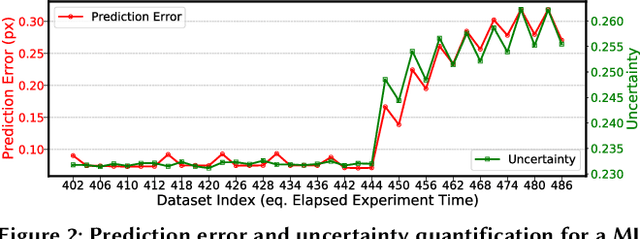
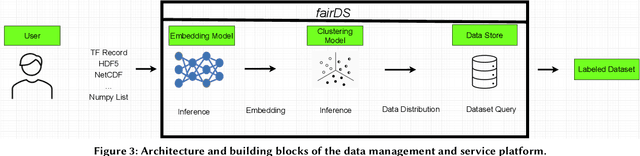
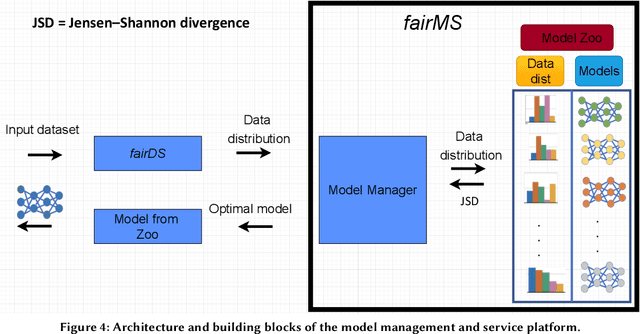
Extracting actionable information from data sources such as the Linac Coherent Light Source (LCLS-II) and Advanced Photon Source Upgrade (APS-U) is becoming more challenging due to the fast-growing data generation rate. The rapid analysis possible with ML methods can enable fast feedback loops that can be used to adjust experimental setups in real-time, for example when errors occur or interesting events are detected. However, to avoid degradation in ML performance over time due to changes in an instrument or sample, we need a way to update ML models rapidly while an experiment is running. We present here a data service and model service to accelerate deep neural network training with a focus on ML-based scientific applications. Our proposed data service achieves 100x speedup in terms of data labeling compare to the current state-of-the-art. Further, our model service achieves up to 200x improvement in training speed. Overall, fairDMS achieves up to 92x speedup in terms of end-to-end model updating time.
Bridge Data Center AI Systems with Edge Computing for Actionable Information Retrieval
May 28, 2021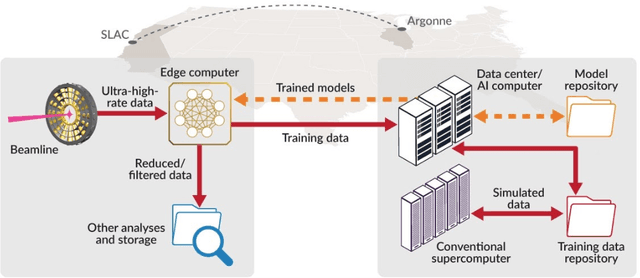

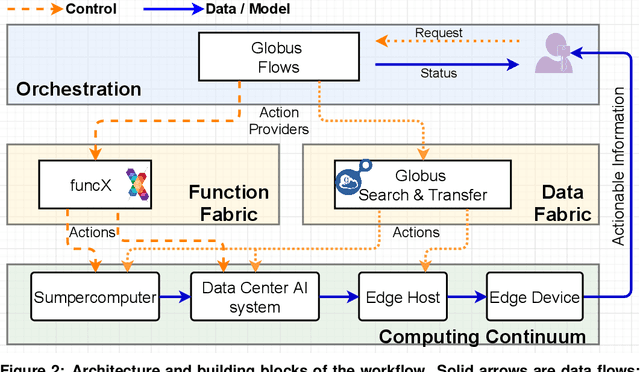
Extremely high data rates at modern synchrotron and X-ray free-electron lasers (XFELs) light source beamlines motivate the use of machine learning methods for data reduction, feature detection, and other purposes. Regardless of the application, the basic concept is the same: data collected in early stages of an experiment, data from past similar experiments, and/or data simulated for the upcoming experiment are used to train machine learning models that, in effect, learn specific characteristics of those data; these models are then used to process subsequent data more efficiently than would general-purpose models that lack knowledge of the specific dataset or data class. Thus, a key challenge is to be able to train models with sufficient rapidity that they can be deployed and used within useful timescales. We describe here how specialized data center AI systems can be used for this purpose.