 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Aware Tensor Networks for Real-Time Quantum-Inspired Anomaly Detection at Particle Colliders
Mar 27, 2026Quantum machine learning offers the ability to capture complex correlations in high-dimensional feature spaces, crucial for the challenge of detecting beyond the Standard Model physics in collider events, along with the potential for unprecedented computational efficiency in future quantum processors. Near-term utilization of these benefits can be achieved by developing quantum-inspired algorithms for deployment in classical hardware to enable applications at the "edge" of current scientific experiments. This work demonstrates the use of tensor networks for real-time anomaly detection in collider detectors. A spaced matrix product operator (SMPO) is developed that provides sensitivity to a variety beyond the Standard Model benchmarks, and can be implemented in field programmable gate array hardware with resources and latency consistent with trigger deployment. The cascaded SMPO architecture is introduced as an SMPO variation that affords greater flexibility and efficiency in ways that are key to edge applications in resource-constrained environments. These results reveal the benefit and near-term feasibility of deploying quantum-inspired ML in high energy colliders.
Machine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
Neural Network Acceleration on MPSoC board: Integrating SLAC's SNL, Rogue Software and Auto-SNL
Aug 29, 2025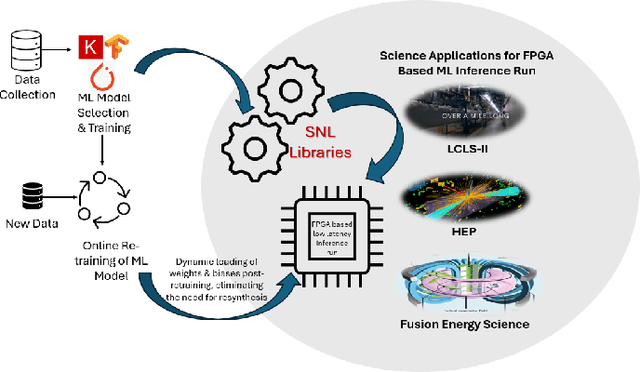
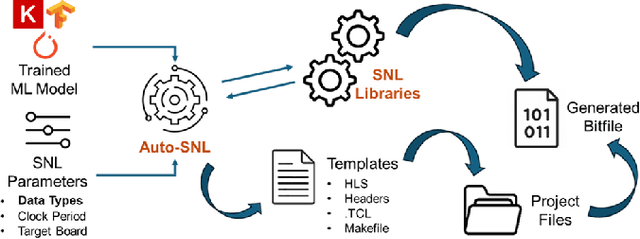
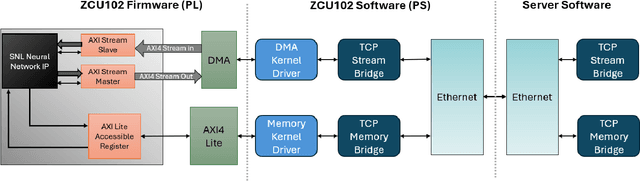
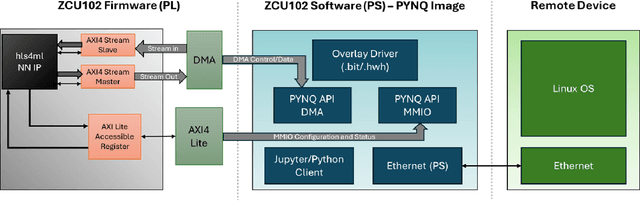
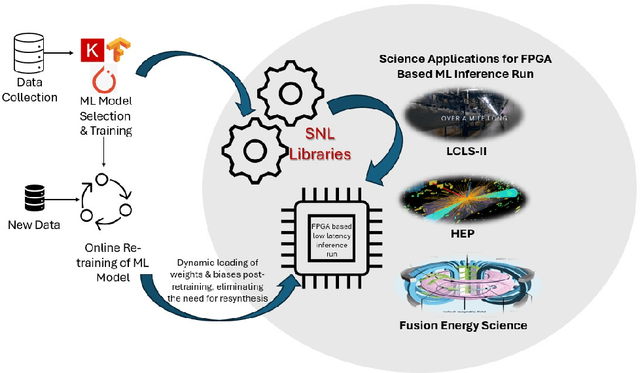
The LCLS-II Free Electron Laser (FEL) will generate X-ray pulses for beamline experiments at rates of up to 1~MHz, with detectors producing data throughputs exceeding 1 TB/s. Managing such massive data streams presents significant challenges, as transmission and storage infrastructures become prohibitively expensive. Machine learning (ML) offers a promising solution for real-time data reduction, but conventional implementations introduce excessive latency, making them unsuitable for high-speed experimental environments. To address these challenges, SLAC developed the SLAC Neural Network Library (SNL), a specialized framework designed to deploy real-time ML inference models on Field-Programmable Gate Arrays (FPGA). SNL's key feature is the ability to dynamically update model weights without requiring FPGA resynthesis, enhancing flexibility for adaptive learning applications. To further enhance usability and accessibility, we introduce Auto-SNL, a Python extension that streamlines the process of converting Python-based neural network models into SNL-compatible high-level synthesis code. This paper presents a benchmark comparison against hls4ml, the current state-of-the-art tool, across multiple neural network architectures, fixed-point precisions, and synthesis configurations targeting a Xilinx ZCU102 FPGA. The results showed that SNL achieves competitive or superior latency in most tested architectures, while in some cases also offering FPGA resource savings. This adaptation demonstrates SNL's versatility, opening new opportunities for researchers and academics in fields such as high-energy physics, medical imaging, robotics, and many more.
FPGA-Accelerated SpeckleNN with SNL for Real-time X-ray Single-Particle Imaging
Feb 27, 2025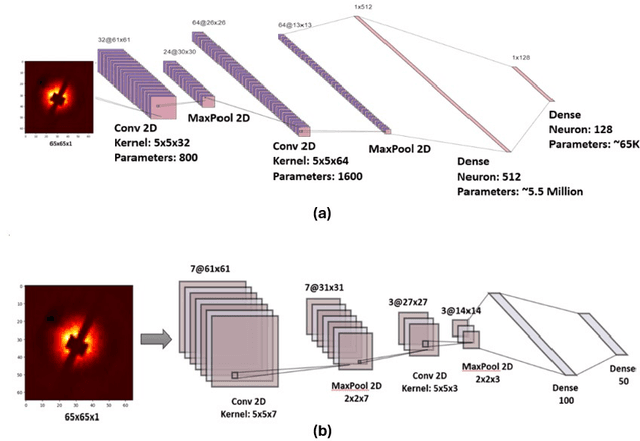

We implement a specialized version of our SpeckleNN model for real-time speckle pattern classification in X-ray Single-Particle Imaging (SPI) using the SLAC Neural Network Library (SNL) on an FPGA. This hardware is optimized for inference near detectors in high-throughput X-ray free-electron laser (XFEL) facilities like the Linac Coherent Light Source (LCLS). To fit FPGA constraints, we optimized SpeckleNN, reducing parameters from 5.6M to 64.6K (98.8% reduction) with 90% accuracy. We also compressed the latent space from 128 to 50 dimensions. Deployed on a KCU1500 FPGA, the model used 71% of DSPs, 75% of LUTs, and 48% of FFs, with an average power consumption of 9.4W. The FPGA achieved 45.015us inference latency at 200 MHz. On an NVIDIA A100 GPU, the same inference consumed ~73W and had a 400us latency. Our FPGA version achieved an 8.9x speedup and 7.8x power reduction over the GPU. Key advancements include model specialization and dynamic weight loading through SNL, eliminating time-consuming FPGA re-synthesis for fast, continuous deployment of (re)trained models. These innovations enable real-time adaptive classification and efficient speckle pattern vetoing, making SpeckleNN ideal for XFEL facilities. This implementation accelerates SPI experiments and enhances adaptability to evolving conditions.
Analysis of Hardware Synthesis Strategies for Machine Learning in Collider Trigger and Data Acquisition
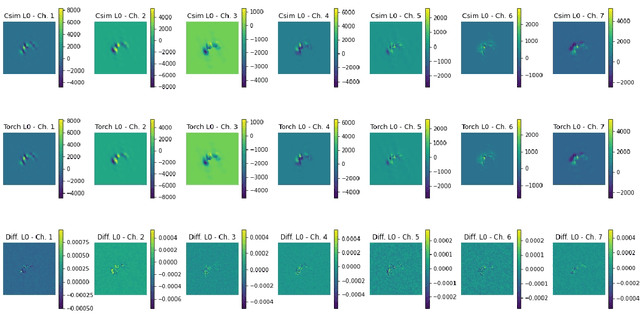
Nov 18, 2024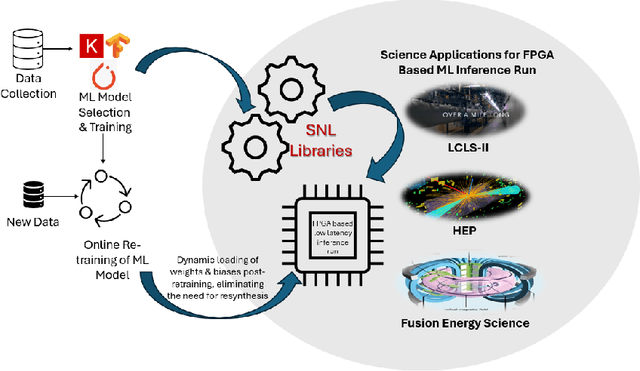

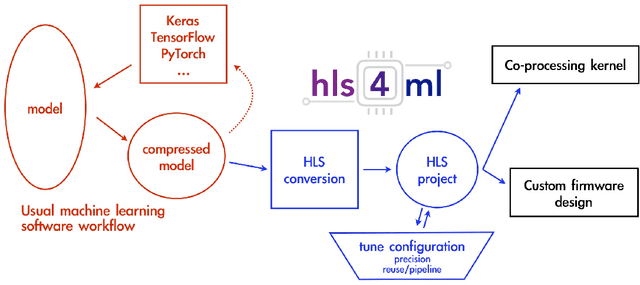

To fully exploit the physics potential of current and future high energy particle colliders, machine learning (ML) can be implemented in detector electronics for intelligent data processing and acquisition. The implementation of ML in real-time at colliders requires very low latencies that are unachievable with a software-based approach, requiring optimization and synthesis of ML algorithms for deployment on hardware. An analysis of neural network inference efficiency is presented, focusing on the application of collider trigger algorithms in field programmable gate arrays (FPGAs). Trade-offs are evaluated between two frameworks, the SLAC Neural Network Library (SNL) and hls4ml, in terms of resources and latency for different model sizes. Results highlight the strengths and limitations of each approach, offering valuable insights for optimizing real-time neural network deployments at colliders. This work aims to guide researchers and engineers in selecting the most suitable hardware and software configurations for real-time, resource-constrained environments.