 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Treatment Strategies: The Role of Adjuvant Anti-Her2 Neu Therapy and Skin/Nipple Involvement in Local Recurrence-Free Survival in Breast Cancer Patients
Jan 04, 2025



This study explores how causal inference models, specifically the Linear Non-Gaussian Acyclic Model (LiNGAM), can extract causal relationships between demographic factors, treatments, conditions, and outcomes from observational patient data, enabling insights beyond correlation. Unlike traditional randomized controlled trials (RCTs), which establish causal relationships within narrowly defined populations, our method leverages broader observational data, improving generalizability. Using over 40 features in the Duke MRI Breast Cancer dataset, we found that Adjuvant Anti-Her2 Neu Therapy increased local recurrence-free survival by 169 days, while Skin/Nipple involvement reduced it by 351 days. These findings highlight the therapy's importance for Her2-positive patients and the need for targeted interventions for high-risk cases, informing personalized treatment strategies.
A Large Language Model Pipeline for Breast Cancer Oncology
Jun 10, 2024Large language models (LLMs) have demonstrated potential in the innovation of many disciplines. However, how they can best be developed for oncology remains underdeveloped. State-of-the-art OpenAI models were fine-tuned on a clinical dataset and clinical guidelines text corpus for two important cancer treatment factors, adjuvant radiation therapy and chemotherapy, using a novel Langchain prompt engineering pipeline. A high accuracy (0.85+) was achieved in the classification of adjuvant radiation therapy and chemotherapy for breast cancer patients. Furthermore, a confidence interval was formed from observational data on the quality of treatment from human oncologists to estimate the proportion of scenarios in which the model must outperform the original oncologist in its treatment prediction to be a better solution overall as 8.2% to 13.3%. Due to indeterminacy in the outcomes of cancer treatment decisions, future investigation, potentially a clinical trial, would be required to determine if this threshold was met by the models. Nevertheless, with 85% of U.S. cancer patients receiving treatment at local community facilities, these kinds of models could play an important part in expanding access to quality care with outcomes that lie, at minimum, close to a human oncologist.
fairDMS: Rapid Model Training by Data and Model Reuse
Apr 20, 2022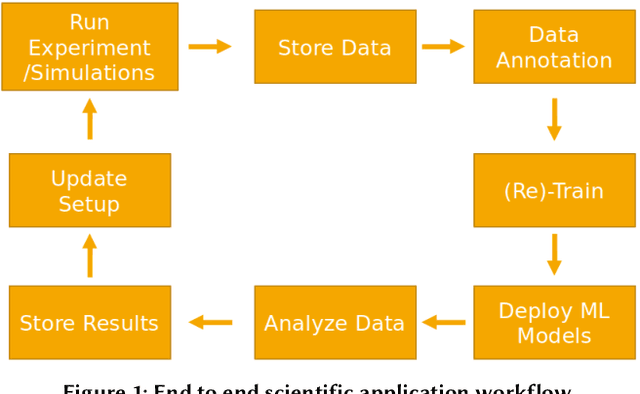
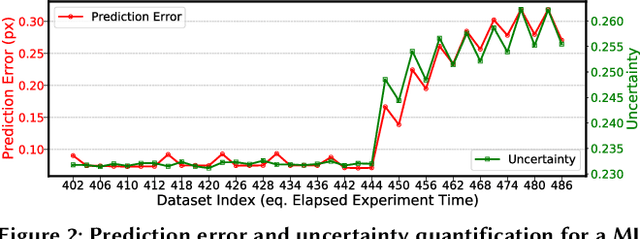
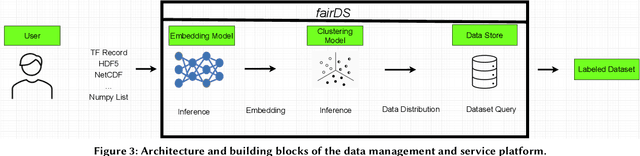
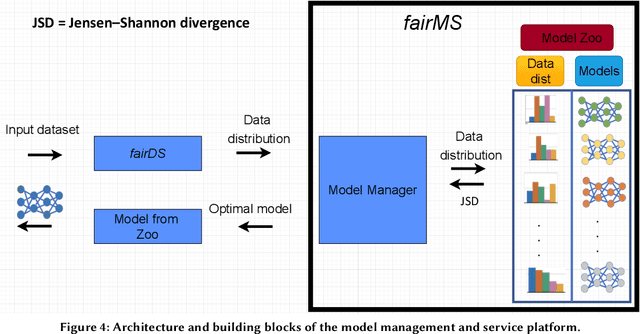
Extracting actionable information from data sources such as the Linac Coherent Light Source (LCLS-II) and Advanced Photon Source Upgrade (APS-U) is becoming more challenging due to the fast-growing data generation rate. The rapid analysis possible with ML methods can enable fast feedback loops that can be used to adjust experimental setups in real-time, for example when errors occur or interesting events are detected. However, to avoid degradation in ML performance over time due to changes in an instrument or sample, we need a way to update ML models rapidly while an experiment is running. We present here a data service and model service to accelerate deep neural network training with a focus on ML-based scientific applications. Our proposed data service achieves 100x speedup in terms of data labeling compare to the current state-of-the-art. Further, our model service achieves up to 200x improvement in training speed. Overall, fairDMS achieves up to 92x speedup in terms of end-to-end model updating time.
Bridge Data Center AI Systems with Edge Computing for Actionable Information Retrieval
May 28, 2021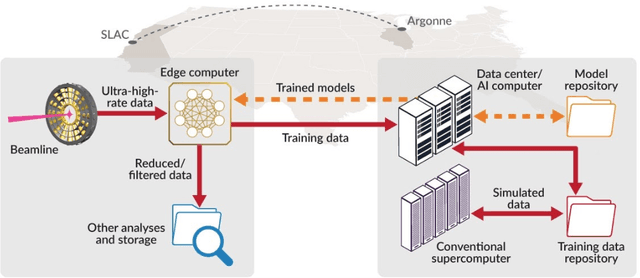

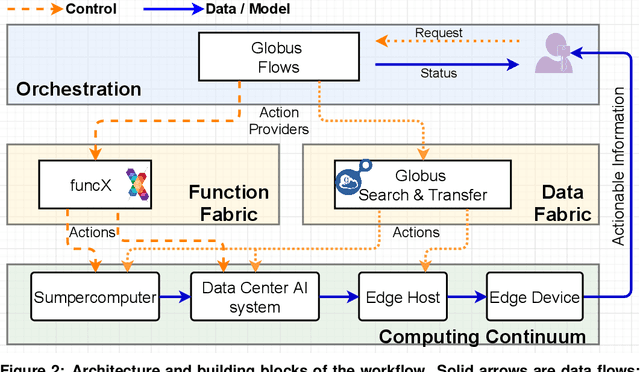
Extremely high data rates at modern synchrotron and X-ray free-electron lasers (XFELs) light source beamlines motivate the use of machine learning methods for data reduction, feature detection, and other purposes. Regardless of the application, the basic concept is the same: data collected in early stages of an experiment, data from past similar experiments, and/or data simulated for the upcoming experiment are used to train machine learning models that, in effect, learn specific characteristics of those data; these models are then used to process subsequent data more efficiently than would general-purpose models that lack knowledge of the specific dataset or data class. Thus, a key challenge is to be able to train models with sufficient rapidity that they can be deployed and used within useful timescales. We describe here how specialized data center AI systems can be used for this purpose.