 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPerRAG: High-Performance Retrieval Augmented Generation for Scientific Insights
May 07, 2025The volume of scientific literature is growing exponentially, leading to underutilized discoveries, duplicated efforts, and limited cross-disciplinary collaboration. Retrieval Augmented Generation (RAG) offers a way to assist scientists by improving the factuality of Large Language Models (LLMs) in processing this influx of information. However, scaling RAG to handle millions of articles introduces significant challenges, including the high computational costs associated with parsing documents and embedding scientific knowledge, as well as the algorithmic complexity of aligning these representations with the nuanced semantics of scientific content. To address these issues, we introduce HiPerRAG, a RAG workflow powered by high performance computing (HPC) to index and retrieve knowledge from more than 3.6 million scientific articles. At its core are Oreo, a high-throughput model for multimodal document parsing, and ColTrast, a query-aware encoder fine-tuning algorithm that enhances retrieval accuracy by using contrastive learning and late-interaction techniques. HiPerRAG delivers robust performance on existing scientific question answering benchmarks and two new benchmarks introduced in this work, achieving 90% accuracy on SciQ and 76% on PubMedQA-outperforming both domain-specific models like PubMedGPT and commercial LLMs such as GPT-4. Scaling to thousands of GPUs on the Polaris, Sunspot, and Frontier supercomputers, HiPerRAG delivers million document-scale RAG workflows for unifying scientific knowledge and fostering interdisciplinary innovation.
Trust Your Gut: Comparing Human and Machine Inference from Noisy Visualizations
Jul 23, 2024



People commonly utilize visualizations not only to examine a given dataset, but also to draw generalizable conclusions about the underlying models or phenomena. Prior research has compared human visual inference to that of an optimal Bayesian agent, with deviations from rational analysis viewed as problematic. However, human reliance on non-normative heuristics may prove advantageous in certain circumstances. We investigate scenarios where human intuition might surpass idealized statistical rationality. In two experiments, we examine individuals' accuracy in characterizing the parameters of known data-generating models from bivariate visualizations. Our findings indicate that, although participants generally exhibited lower accuracy compared to statistical models, they frequently outperformed Bayesian agents, particularly when faced with extreme samples. Participants appeared to rely on their internal models to filter out noisy visualizations, thus improving their resilience against spurious data. However, participants displayed overconfidence and struggled with uncertainty estimation. They also exhibited higher variance than statistical machines. Our findings suggest that analyst gut reactions to visualizations may provide an advantage, even when departing from rationality. These results carry implications for designing visual analytics tools, offering new perspectives on how to integrate statistical models and analyst intuition for improved inference and decision-making. The data and materials for this paper are available at https://osf.io/qmfv6
Interpretable Modeling of Deep Reinforcement Learning Driven Scheduling
Mar 24, 2024In the field of high-performance computing (HPC), there has been recent exploration into the use of deep reinforcement learning for cluster scheduling (DRL scheduling), which has demonstrated promising outcomes. However, a significant challenge arises from the lack of interpretability in deep neural networks (DNN), rendering them as black-box models to system managers. This lack of model interpretability hinders the practical deployment of DRL scheduling. In this work, we present a framework called IRL (Interpretable Reinforcement Learning) to address the issue of interpretability of DRL scheduling. The core idea is to interpret DNN (i.e., the DRL policy) as a decision tree by utilizing imitation learning. Unlike DNN, decision tree models are non-parametric and easily comprehensible to humans. To extract an effective and efficient decision tree, IRL incorporates the Dataset Aggregation (DAgger) algorithm and introduces the notion of critical state to prune the derived decision tree. Through trace-based experiments, we demonstrate that IRL is capable of converting a black-box DNN policy into an interpretable rulebased decision tree while maintaining comparable scheduling performance. Additionally, IRL can contribute to the setting of rewards in DRL scheduling.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
A Comprehensive Performance Study of Large Language Models on Novel AI Accelerators
Oct 06, 2023



Artificial intelligence (AI) methods have become critical in scientific applications to help accelerate scientific discovery. Large language models (LLMs) are being considered as a promising approach to address some of the challenging problems because of their superior generalization capabilities across domains. The effectiveness of the models and the accuracy of the applications is contingent upon their efficient execution on the underlying hardware infrastructure. Specialized AI accelerator hardware systems have recently become available for accelerating AI applications. However, the comparative performance of these AI accelerators on large language models has not been previously studied. In this paper, we systematically study LLMs on multiple AI accelerators and GPUs and evaluate their performance characteristics for these models. We evaluate these systems with (i) a micro-benchmark using a core transformer block, (ii) a GPT- 2 model, and (iii) an LLM-driven science use case, GenSLM. We present our findings and analyses of the models' performance to better understand the intrinsic capabilities of AI accelerators. Furthermore, our analysis takes into account key factors such as sequence lengths, scaling behavior, sparsity, and sensitivity to gradient accumulation steps.
A Multi-Level, Multi-Scale Visual Analytics Approach to Assessment of Multifidelity HPC Systems
Jun 15, 2023The ability to monitor and interpret of hardware system events and behaviors are crucial to improving the robustness and reliability of these systems, especially in a supercomputing facility. The growing complexity and scale of these systems demand an increase in monitoring data collected at multiple fidelity levels and varying temporal resolutions. In this work, we aim to build a holistic analytical system that helps make sense of such massive data, mainly the hardware logs, job logs, and environment logs collected from disparate subsystems and components of a supercomputer system. This end-to-end log analysis system, coupled with visual analytics support, allows users to glean and promptly extract supercomputer usage and error patterns at varying temporal and spatial resolutions. We use multiresolution dynamic mode decomposition (mrDMD), a technique that depicts high-dimensional data as correlated spatial-temporal variations patterns or modes, to extract variation patterns isolated at specified frequencies. Our improvements to the mrDMD algorithm help promptly reveal useful information in the massive environment log dataset, which is then associated with the processed hardware and job log datasets using our visual analytics system. Furthermore, our system can identify the usage and error patterns filtered at user, project, and subcomponent levels. We exemplify the effectiveness of our approach with two use scenarios with the Cray XC40 supercomputer.
Distributed Neural Representation for Reactive in situ Visualization
Mar 28, 2023



In situ visualization and steering of computational modeling can be effectively achieved using reactive programming, which leverages temporal abstraction and data caching mechanisms to create dynamic workflows. However, implementing a temporal cache for large-scale simulations can be challenging. Implicit neural networks have proven effective in compressing large volume data. However, their application to distributed data has yet to be fully explored. In this work, we develop an implicit neural representation for distributed volume data and incorporate it into the DIVA reactive programming system. This implementation enables us to build an in situ temporal caching system with a capacity 100 times larger than previously achieved. We integrate our implementation into the Ascent infrastructure and evaluate its performance using real-world simulations.
BFTrainer: Low-Cost Training of Neural Networks on Unfillable Supercomputer Nodes
Jun 22, 2021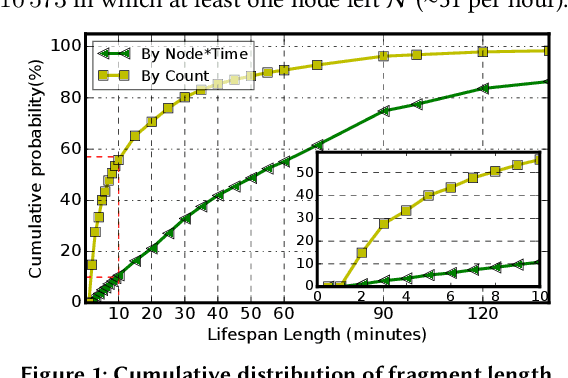
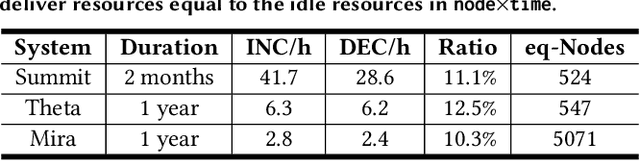
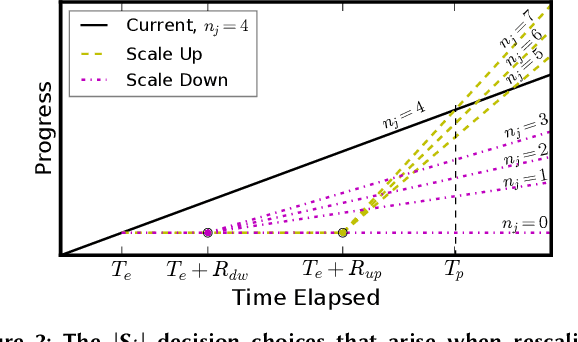
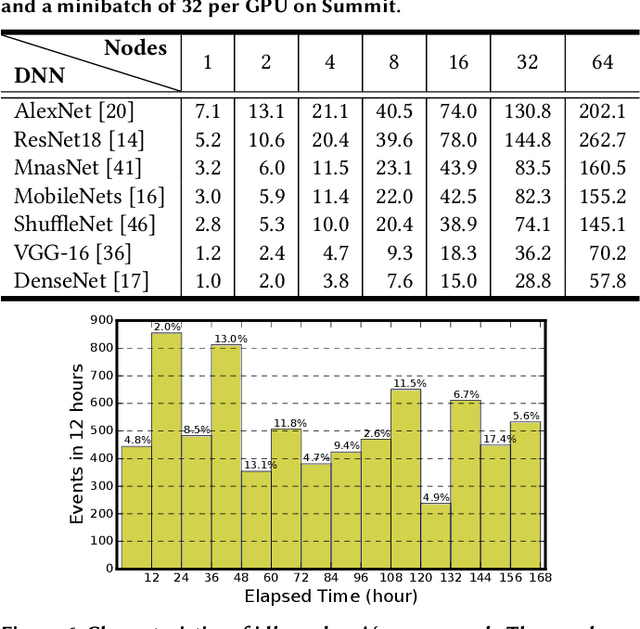
Supercomputer FCFS-based scheduling policies result in many transient idle nodes, a phenomenon that is only partially alleviated by backfill scheduling methods that promote small jobs to run before large jobs. Here we describe how to realize a novel use for these otherwise wasted resources, namely, deep neural network (DNN) training. This important workload is easily organized as many small fragments that can be configured dynamically to fit essentially any node*time hole in a supercomputer's schedule. We describe how the task of rescaling suitable DNN training tasks to fit dynamically changing holes can be formulated as a deterministic mixed integer linear programming (MILP)-based resource allocation algorithm, and show that this MILP problem can be solved efficiently at run time. We show further how this MILP problem can be adapted to optimize for administrator- or user-defined metrics. We validate our method with supercomputer scheduler logs and different DNN training scenarios, and demonstrate efficiencies of up to 93% compared with running the same training tasks on dedicated nodes. Our method thus enables substantial supercomputer resources to be allocated to DNN training with no impact on other applications.
Deep Reinforcement Agent for Scheduling in HPC
Feb 11, 2021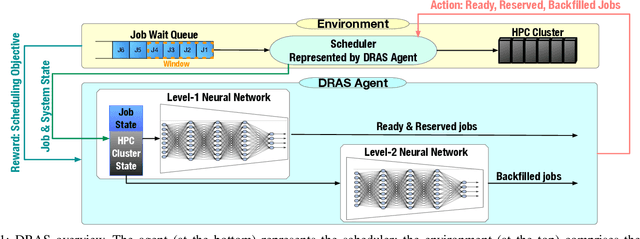
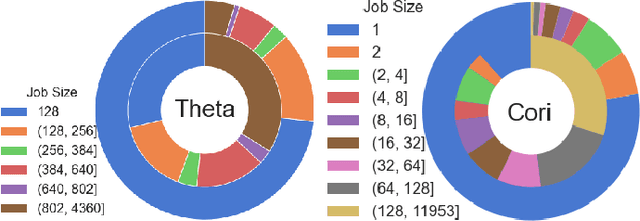
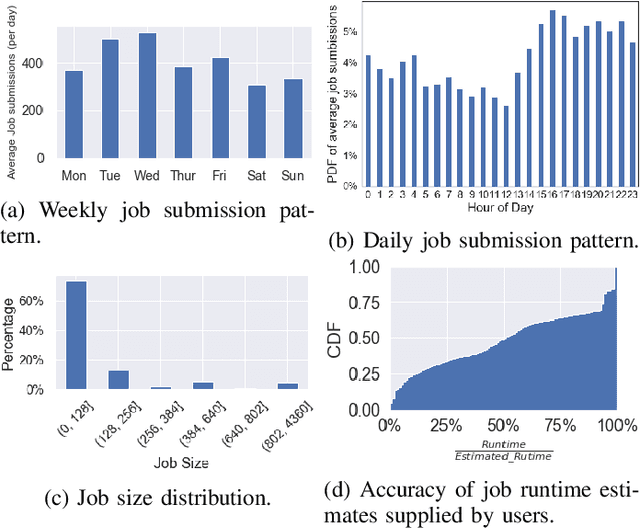
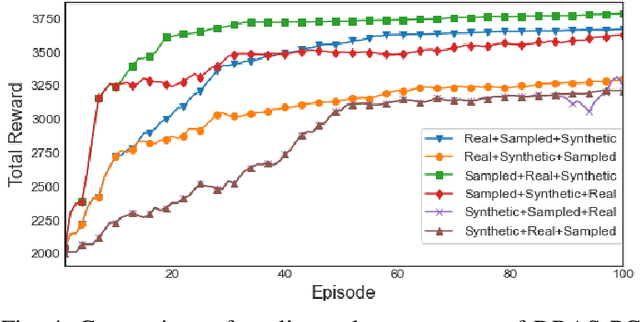
Cluster scheduler is crucial in high-performance computing (HPC). It determines when and which user jobs should be allocated to available system resources. Existing cluster scheduling heuristics are developed by human experts based on their experience with specific HPC systems and workloads. However, the increasing complexity of computing systems and the highly dynamic nature of application workloads have placed tremendous burden on manually designed and tuned scheduling heuristics. More aggressive optimization and automation are needed for cluster scheduling in HPC. In this work, we present an automated HPC scheduling agent named DRAS (Deep Reinforcement Agent for Scheduling) by leveraging deep reinforcement learning. DRAS is built on a novel, hierarchical neural network incorporating special HPC scheduling features such as resource reservation and backfilling. A unique training strategy is presented to enable DRAS to rapidly learn the target environment. Once being provided a specific scheduling objective given by system manager, DRAS automatically learns to improve its policy through interaction with the scheduling environment and dynamically adjusts its policy as workload changes. The experiments with different production workloads demonstrate that DRAS outperforms the existing heuristic and optimization approaches by up to 45%.
* Accepted by IPDPS 2021