 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioAlchemy: Distilling Biological Literature into Reasoning-Ready Reinforcement Learning Training Data
Apr 03, 2026Despite the large corpus of biology training text, the impact of reasoning models on biological research generally lags behind math and coding. In this work, we show that biology questions from current large-scale reasoning datasets do not align well with modern research topic distributions in biology, and that this topic imbalance may negatively affect performance. In addition, we find that methods for extracting challenging and verifiable research problems from biology research text are a critical yet underdeveloped ingredient in applying reinforcement learning for better performance on biology research tasks. We introduce BioAlchemy, a pipeline for sourcing a diverse set of verifiable question-and-answer pairs from a scientific corpus of biology research text. We curate BioAlchemy-345K, a training dataset containing over 345K scientific reasoning problems in biology. Then, we demonstrate how aligning our dataset to the topic distribution of modern scientific biology can be used with reinforcement learning to improve reasoning performance. Finally, we present BioAlchemist-8B, which improves over its base reasoning model by 9.12% on biology benchmarks. These results demonstrate the efficacy of our approach for developing stronger scientific reasoning capabilities in biology. The BioAlchemist-8B model is available at: https://huggingface.co/BioAlchemy.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
HiPerRAG: High-Performance Retrieval Augmented Generation for Scientific Insights
May 07, 2025The volume of scientific literature is growing exponentially, leading to underutilized discoveries, duplicated efforts, and limited cross-disciplinary collaboration. Retrieval Augmented Generation (RAG) offers a way to assist scientists by improving the factuality of Large Language Models (LLMs) in processing this influx of information. However, scaling RAG to handle millions of articles introduces significant challenges, including the high computational costs associated with parsing documents and embedding scientific knowledge, as well as the algorithmic complexity of aligning these representations with the nuanced semantics of scientific content. To address these issues, we introduce HiPerRAG, a RAG workflow powered by high performance computing (HPC) to index and retrieve knowledge from more than 3.6 million scientific articles. At its core are Oreo, a high-throughput model for multimodal document parsing, and ColTrast, a query-aware encoder fine-tuning algorithm that enhances retrieval accuracy by using contrastive learning and late-interaction techniques. HiPerRAG delivers robust performance on existing scientific question answering benchmarks and two new benchmarks introduced in this work, achieving 90% accuracy on SciQ and 76% on PubMedQA-outperforming both domain-specific models like PubMedGPT and commercial LLMs such as GPT-4. Scaling to thousands of GPUs on the Polaris, Sunspot, and Frontier supercomputers, HiPerRAG delivers million document-scale RAG workflows for unifying scientific knowledge and fostering interdisciplinary innovation.
From Models to Systems: A Comprehensive Fairness Framework for Compositional Recommender Systems
Dec 05, 2024



Fairness research in machine learning often centers on ensuring equitable performance of individual models. However, real-world recommendation systems are built on multiple models and even multiple stages, from candidate retrieval to scoring and serving, which raises challenges for responsible development and deployment. This system-level view, as highlighted by regulations like the EU AI Act, necessitates moving beyond auditing individual models as independent entities. We propose a holistic framework for modeling system-level fairness, focusing on the end-utility delivered to diverse user groups, and consider interactions between components such as retrieval and scoring models. We provide formal insights on the limitations of focusing solely on model-level fairness and highlight the need for alternative tools that account for heterogeneity in user preferences. To mitigate system-level disparities, we adapt closed-box optimization tools (e.g., BayesOpt) to jointly optimize utility and equity. We empirically demonstrate the effectiveness of our proposed framework on synthetic and real datasets, underscoring the need for a system-level framework.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Disentangling and Operationalizing AI Fairness at LinkedIn
May 30, 2023Operationalizing AI fairness at LinkedIn's scale is challenging not only because there are multiple mutually incompatible definitions of fairness but also because determining what is fair depends on the specifics and context of the product where AI is deployed. Moreover, AI practitioners need clarity on what fairness expectations need to be addressed at the AI level. In this paper, we present the evolving AI fairness framework used at LinkedIn to address these three challenges. The framework disentangles AI fairness by separating out equal treatment and equitable product expectations. Rather than imposing a trade-off between these two commonly opposing interpretations of fairness, the framework provides clear guidelines for operationalizing equal AI treatment complemented with a product equity strategy. This paper focuses on the equal AI treatment component of LinkedIn's AI fairness framework, shares the principles that support it, and illustrates their application through a case study. We hope this paper will encourage other big tech companies to join us in sharing their approach to operationalizing AI fairness at scale, so that together we can keep advancing this constantly evolving field.
An Operational Perspective to Fairness Interventions: Where and How to Intervene
Feb 03, 2023



As AI-based decision systems proliferate, their successful operationalization requires balancing multiple desiderata: predictive performance, disparity across groups, safeguarding sensitive group attributes (e.g., race), and engineering cost. We present a holistic framework for evaluating and contextualizing fairness interventions with respect to the above desiderata. The two key points of practical consideration are where (pre-, in-, post-processing) and how (in what way the sensitive group data is used) the intervention is introduced. We demonstrate our framework using a thorough benchmarking study on predictive parity; we study close to 400 methodological variations across two major model types (XGBoost vs. Neural Net) and ten datasets. Methodological insights derived from our empirical study inform the practical design of ML workflow with fairness as a central concern. We find predictive parity is difficult to achieve without using group data, and despite requiring group data during model training (but not inference), distributionally robust methods provide significant Pareto improvement. Moreover, a plain XGBoost model often Pareto-dominates neural networks with fairness interventions, highlighting the importance of model inductive bias.
Pushing the limits of fairness impossibility: Who's the fairest of them all?
Aug 24, 2022
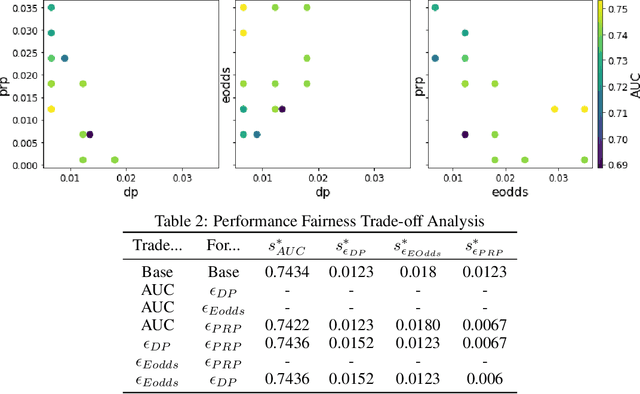
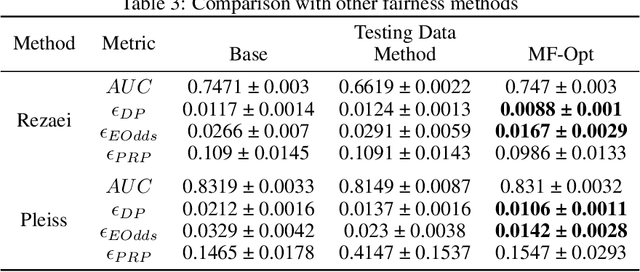
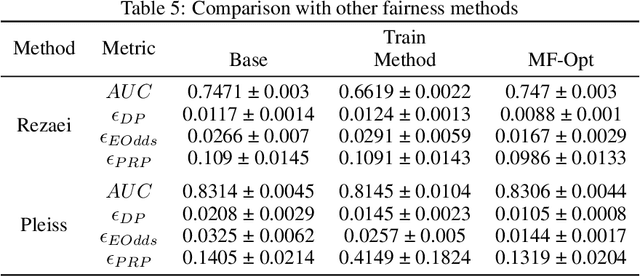
The impossibility theorem of fairness is a foundational result in the algorithmic fairness literature. It states that outside of special cases, one cannot exactly and simultaneously satisfy all three common and intuitive definitions of fairness - demographic parity, equalized odds, and predictive rate parity. This result has driven most works to focus on solutions for one or two of the metrics. Rather than follow suit, in this paper we present a framework that pushes the limits of the impossibility theorem in order to satisfy all three metrics to the best extent possible. We develop an integer-programming based approach that can yield a certifiably optimal post-processing method for simultaneously satisfying multiple fairness criteria under small violations. We show experiments demonstrating that our post-processor can improve fairness across the different definitions simultaneously with minimal model performance reduction. We also discuss applications of our framework for model selection and fairness explainability, thereby attempting to answer the question: who's the fairest of them all?