 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Models to Systems: A Comprehensive Fairness Framework for Compositional Recommender Systems
Dec 05, 2024Fairness research in machine learning often centers on ensuring equitable performance of individual models. However, real-world recommendation systems are built on multiple models and even multiple stages, from candidate retrieval to scoring and serving, which raises challenges for responsible development and deployment. This system-level view, as highlighted by regulations like the EU AI Act, necessitates moving beyond auditing individual models as independent entities. We propose a holistic framework for modeling system-level fairness, focusing on the end-utility delivered to diverse user groups, and consider interactions between components such as retrieval and scoring models. We provide formal insights on the limitations of focusing solely on model-level fairness and highlight the need for alternative tools that account for heterogeneity in user preferences. To mitigate system-level disparities, we adapt closed-box optimization tools (e.g., BayesOpt) to jointly optimize utility and equity. We empirically demonstrate the effectiveness of our proposed framework on synthetic and real datasets, underscoring the need for a system-level framework.
Interpretable Assessment of Fairness During Model Evaluation
Oct 26, 2020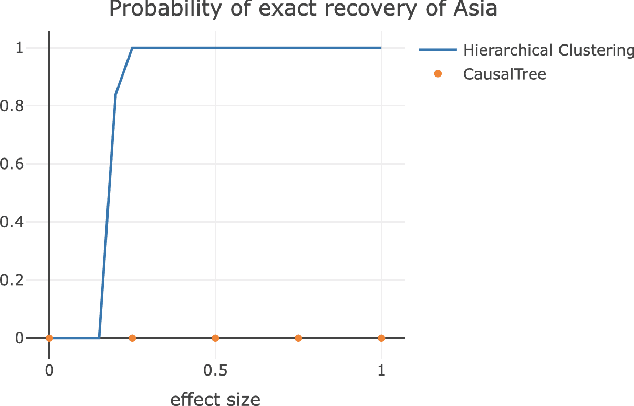
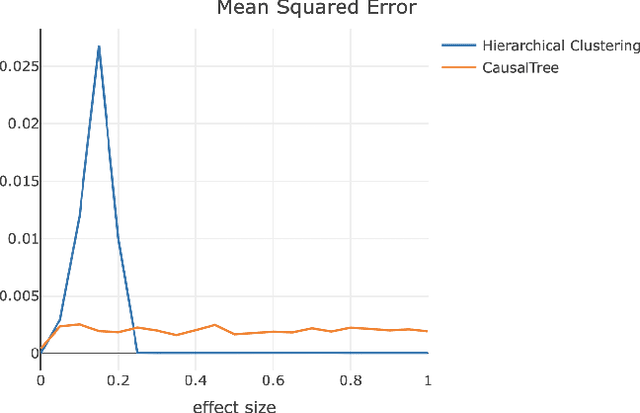
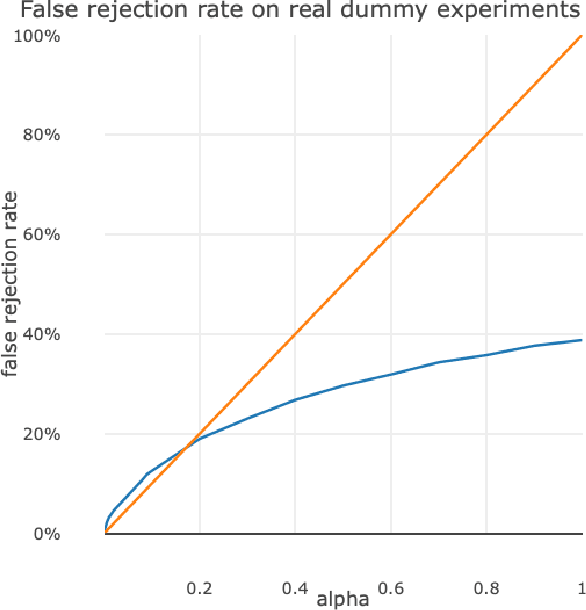
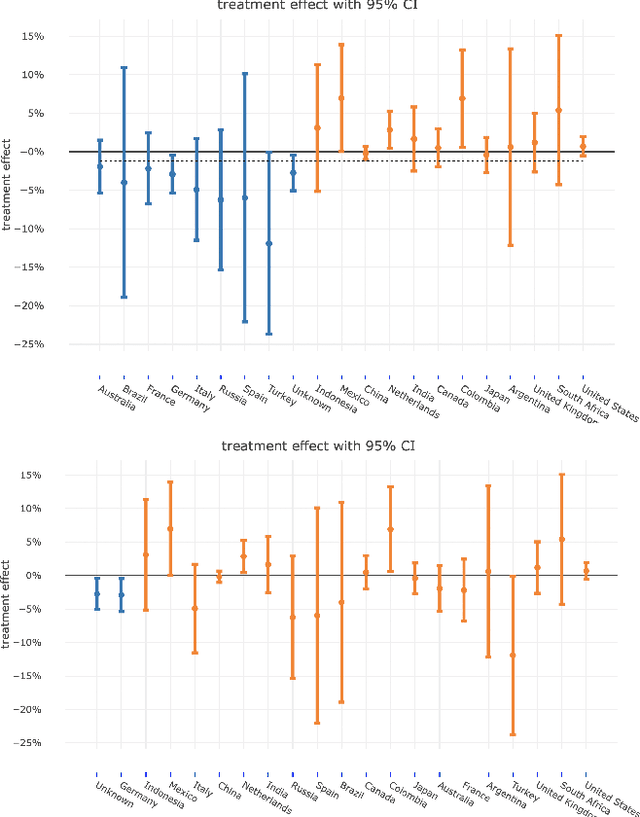
For companies developing products or algorithms, it is important to understand the potential effects not only globally, but also on sub-populations of users. In particular, it is important to detect if there are certain groups of users that are impacted differently compared to others with regard to business metrics or for whom a model treats unequally along fairness concerns. In this paper, we introduce a novel hierarchical clustering algorithm to detect heterogeneity among users in given sets of sub-populations with respect to any specified notion of group similarity. We prove statistical guarantees about the output and provide interpretable results. We demonstrate the performance of the algorithm on real data from LinkedIn.
A Framework for Fairness in Two-Sided Marketplaces
Jun 23, 2020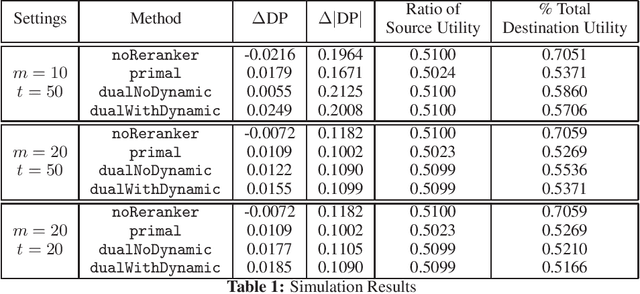
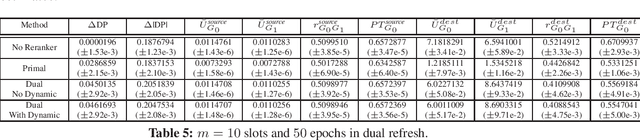


Many interesting problems in the Internet industry can be framed as a two-sided marketplace problem. Examples include search applications and recommender systems showing people, jobs, movies, products, restaurants, etc. Incorporating fairness while building such systems is crucial and can have a deep social and economic impact (applications include job recommendations, recruiters searching for candidates, etc.). In this paper, we propose a definition and develop an end-to-end framework for achieving fairness while building such machine learning systems at scale. We extend prior work to develop an optimization framework that can tackle fairness constraints from both the source and destination sides of the marketplace, as well as dynamic aspects of the problem. The framework is flexible enough to adapt to different definitions of fairness and can be implemented in very large-scale settings. We perform simulations to show the efficacy of our approach.