Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Assessment of Fairness During Model Evaluation
Paper and Code
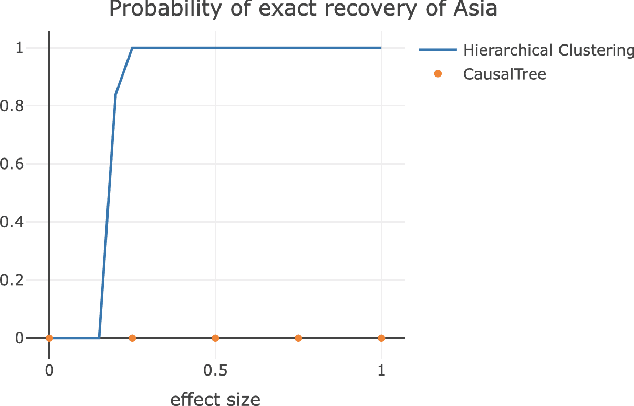
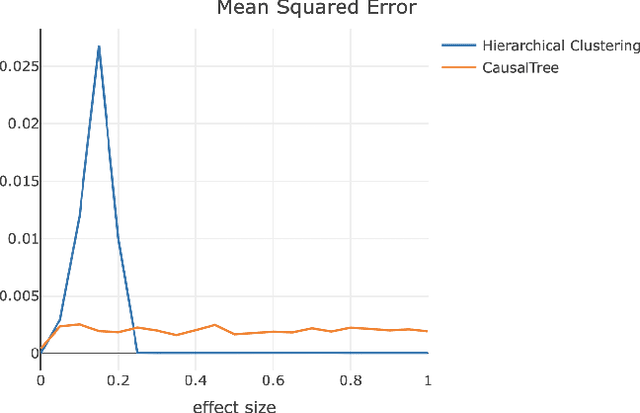
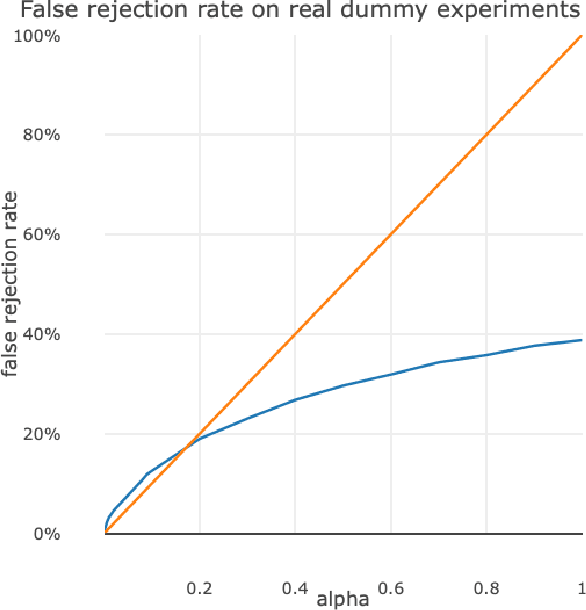
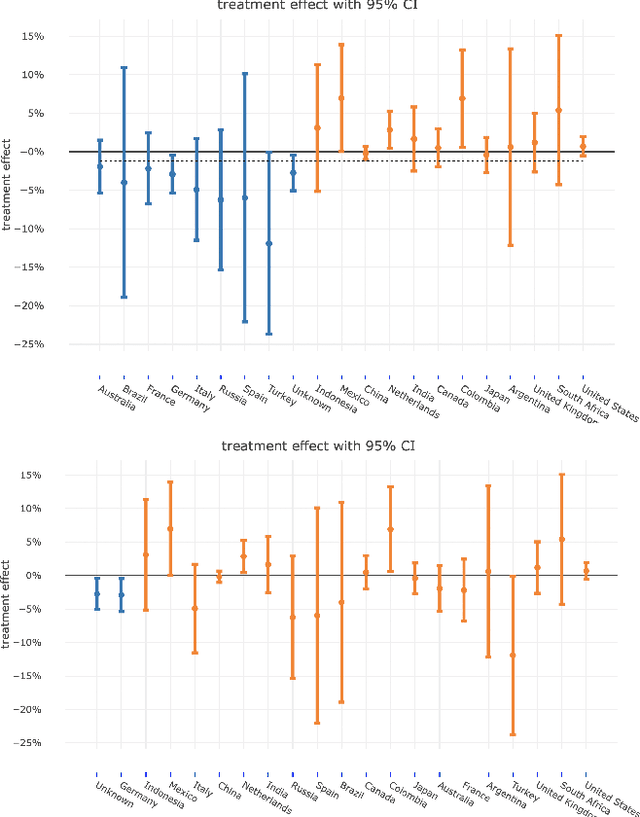
For companies developing products or algorithms, it is important to understand the potential effects not only globally, but also on sub-populations of users. In particular, it is important to detect if there are certain groups of users that are impacted differently compared to others with regard to business metrics or for whom a model treats unequally along fairness concerns. In this paper, we introduce a novel hierarchical clustering algorithm to detect heterogeneity among users in given sets of sub-populations with respect to any specified notion of group similarity. We prove statistical guarantees about the output and provide interpretable results. We demonstrate the performance of the algorithm on real data from LinkedIn.
View paper on